
ls list(列表) 列表目录文件 #ls / 列表根目录
cd change directory 改变目录路径 #cd /etc
pwd print work directory 查看当前路径


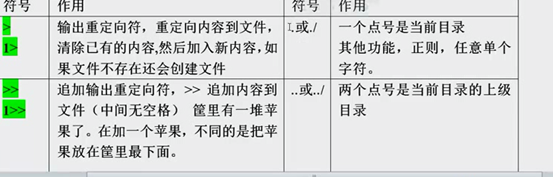
echo 是一个打印输出内容的一个常用命令,配合>或>>,可以为文件覆盖及追加内容。’
例:echo ‘I am study linux’>oldboy.txt
[root@bianzhuo data]# cat >oldboy.txt
cat >>/data/oldboy.txt<<EOF 多行输入 以EOF结尾

echo oldgirl 1>a.txt 2>a.txt 把正确输出和错误输出都放到a.txt
echo oldgirl 1>a,txt 2>&1 同上(更为通用)
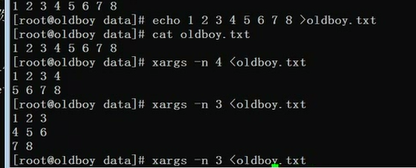
xargs 从标准输入获取内容创建和执行命令 -n 数字 分组
不加参数只能拷贝文件 [root@bianzhuo data]# cp oldboy.txt /tmp/
加了参数 可以拷贝目录 [root@bianzhuo data]# cp -r /data /tmp
-d 若文件链接文件,拷过去的是链接的属性而非文件本身的属性
[root@bianzhuo /]# mv data /root/
[root@bianzhuo data]# rm oldboy.txt
-type f 文件类型 d 目录 c 字符类型 b块设备 s socket文件
-mtime 时间 按修改时间查找 +7 7天以前 7第7天 -7最近7天
find /data -type f -name “oldboy.txt”
find /data -type f -name “oldboy.txt” -exec rm {} \;
find /data -type f -name “*.txt”
find /data -type f -name “*.txt” |xargs
find /data -type f -name “*.txt” |xargs rm -f

[root@bianzhuo data]# cat oldboy.txt
[root@bianzhuo data]# grep -v oldboy oldboy.txt
[root@bianzhuo data]# grep oldboy oldboy.txt
例子:grep 25 -C 5 ett,txt 显示20~~30行数据
[root@bianzhuo data]# head -2 oldboy.txt
[root@bianzhuo data]# head -n 2 oldboy.txt
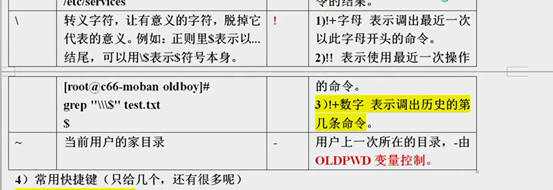
alias 查看和设置别名 例子:查看别名直接输入别名即可 设置别名 alias
· [root@bianzhuo data]# alias haha=’echo hahaha’
[root@bianzhuo data]# alias fuck=’rm’
一般是存储在内存里,重启之后alias设置的命令消失,但是也可以设置其保存在文件里

sed stream editor 流编辑器 实现对文件的增删改查
[root@bianzhuo data]# sed -n ‘20,30’p ett.txt ‘最有效率的’
[root@bianzhuo data]# sed -n ‘$’p ett.txt
sed -i s#oldboy#oldgirl#g a.txt 将oldboy 替换成oldgirl #是分隔符,可以用/@等替换
awk ’19<NR &&NR<31′ ett.txt NR为行号
将所有后缀为.sh的文件中的oldboy替换成oldgirl
[root@bianzhuo oldboy]# find /root/oldboy -type f -name “*.sh”|xargs sed -i ‘s#oldboy#oldgirl#g’
将所有后缀为.sh的文件中的oldgirl替换成oldboy
[root@bianzhuo oldboy]# sed -i ‘s#oldgirl#oldboy#g’ `find /root/oldboy -type f -name “*.sh”`

转载于:https://www.cnblogs.com/bianzhuo/p/10381262.html
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/101122.html原文链接:https://javaforall.net


