
卷积层要提升表达能力,主要依靠增加输出通道数,副作用是计算量增大和过拟合。
一、历史过程:
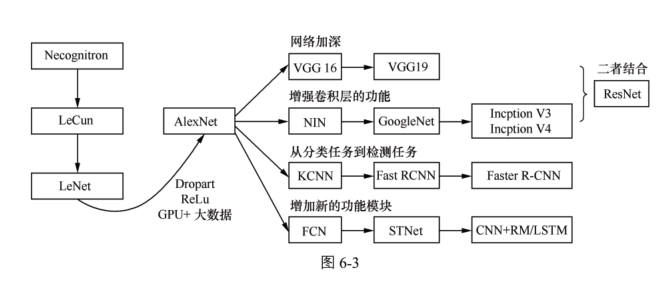

二、经典网络
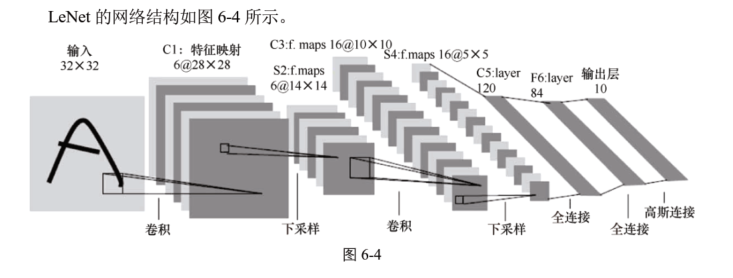
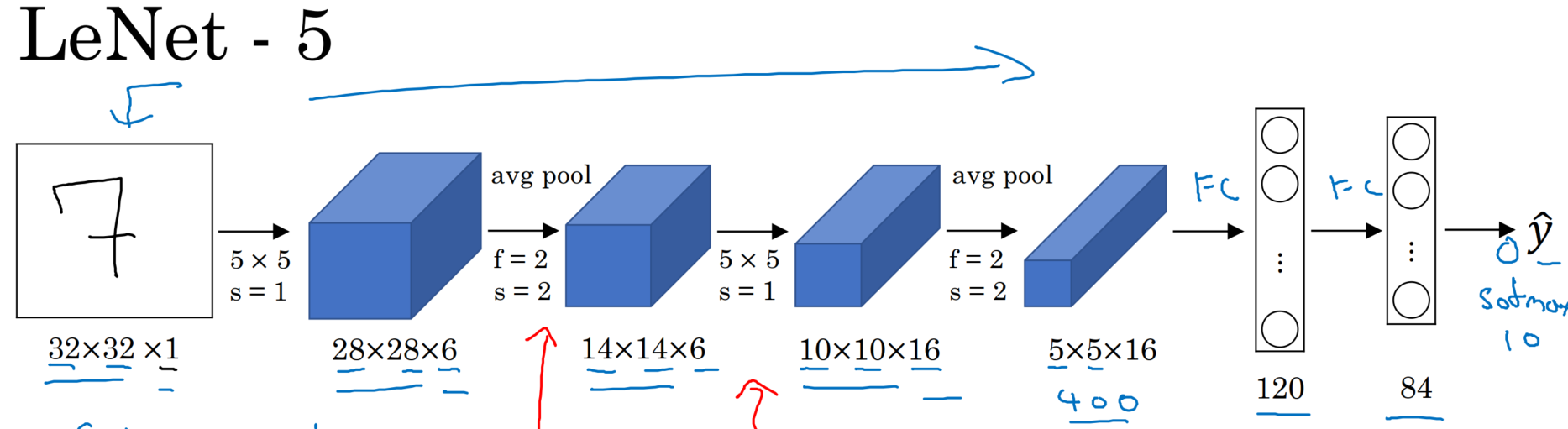
1、LeNet:两层卷积+池化,两层全连接
2、AlexNet:5个卷积层、5个池化层、3个全连接层【大约5000万个参数】,最后一个全连接层输出到一个1000维的softmax层,产生一个1000类的分类。
优点:

采用了非线性激活函数relu替代了sigmoid,SGD的收敛速度会比sigmoid/tanh快很多。

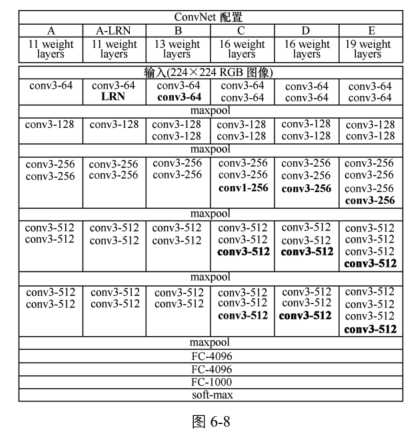
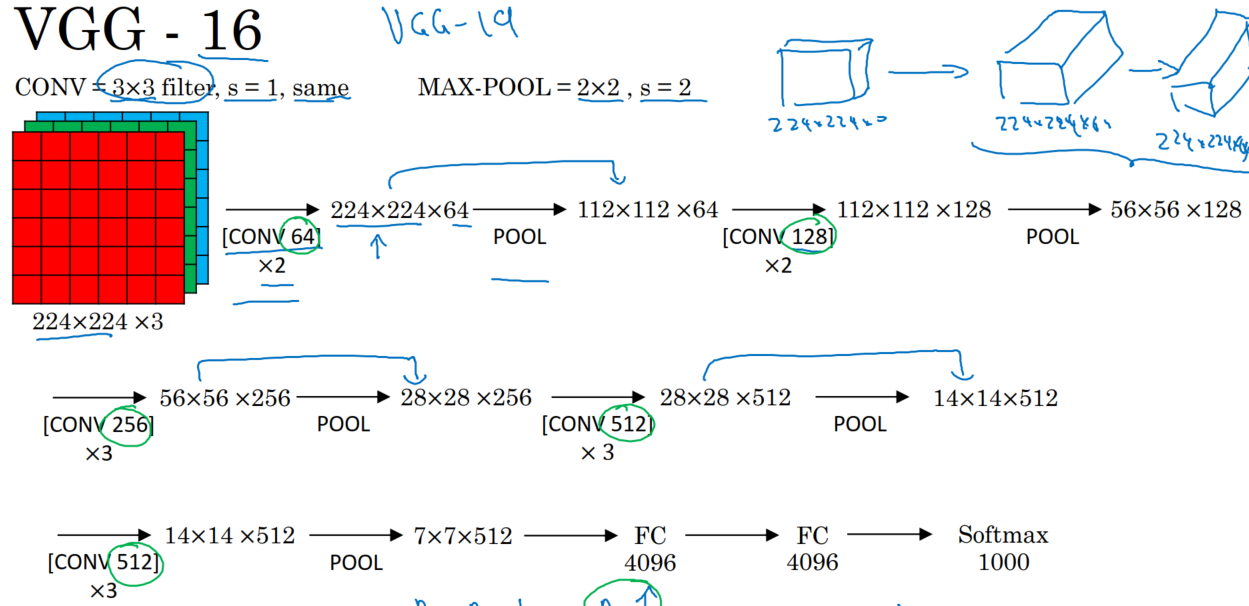
3、VGG是加强版的AlexNet:
13个卷积层【5段卷积层(2+2+3+3+3),5个池化层】、3个全连接层【两个全连接图像特征,1层全连接分类特征】,但其增强了卷积层的功能。即AlexNet采用了8层卷积层(如以下配置A层),但VGG采用了16层和19层(如以下配置的C、D、E层)。
4、GoogleNet(Inception结构):
https://blog.csdn.net/transMaple/article/details/78439710
以上的网络主要是纵向延伸,GoogleNet考虑了横向延伸。
主要围绕深度和宽度来实现的:
深度:层数更深,采用了22层,为了避免梯度消失,GoogleNet在不同深度处增加了两个损失函数来避免反向传播时梯度消失的现象。
宽度:增加了多种大小的卷积核,如1*1,3*3,5*5。采用了降维的Inception模型,在3*3、5*5卷积前,和最大池化后都分布加上了1*1的卷积核,起到了降低特征映射厚度的作用。
整个网络:
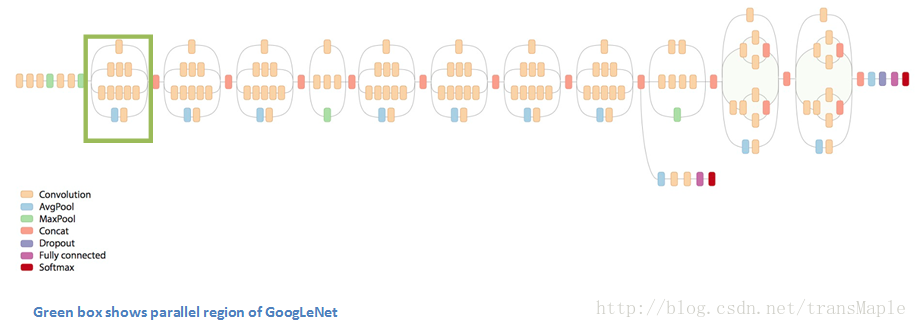
绿色框内就是Inception结构,如下图模型。
在传统的转换网络中,每个层从前一层提取信息,以便将输入数据变换成更有用的表示。然而,每个层类型提取不同种类的信息。5×5卷积核的输出告诉我们与3×3卷积核的输出不同的东西,这告诉我们与最大池内核的输出不同,等等。在任何给定的层面,我们如何知道什么转换提供了最有用的信息?
为什么不让模型选择?
于是Inception将1×1, 3×3, 5×5, max-pool结合起来,让网络选择,最后通过一个聚合操作合并(在输出通道数这个维度上聚合)

这种模块的意义是,你可能不清楚用一个小的感受野效果好还是大的感受野效果好,可以把这些放一起来评判
关键点:
– 横向扩展
– 使用了1×1的filter,可以很方便的改变卷积结果的层数(1×1的filter也被称为bottleneck),性价比高,很小的计算量能增加一层特征变换和非线性化。
GooleNet分三种:Inception V1(22层)、Inception V2、Inception V3
- Inception V1的最大特点是控制了计算量和参数量的同时,获得很好的分类性能。【参数量降低,但准确率上升】
- 降低参数量的目的有两点:
第一,参数越多模型越庞大,需提供学习的数据量更大。
第二,参数越多,耗费的计算资源更大。
- 参数少效果好的原因:
一、模型层数深、表达能力更强。
二、去除了最后的全连接层,全局平均池化层(即将图片尺寸变为 1 × 1)来取代它。【全连接层具有大部分的参数且会引起过拟合,采用全局平均池化层采用了NIN思想。】
三、Inception V1中的Inception Module提高了参数的利用率。Inception Module如大网络中的一个小网络,其结构可反复堆叠在一起形成大网络。Inception V1比NIN增加了分支网络,NIN则主要是级联的卷积层和MLPConv层。
- Inception V2:采用了两个3*3的卷积代替5*5的大卷积,还提出了BN(批标准化)方法。
- Inception V3:将一个较大的二维卷积拆成两个较小的一维卷积,如7*7卷积拆成1*7卷积和7*1卷积。
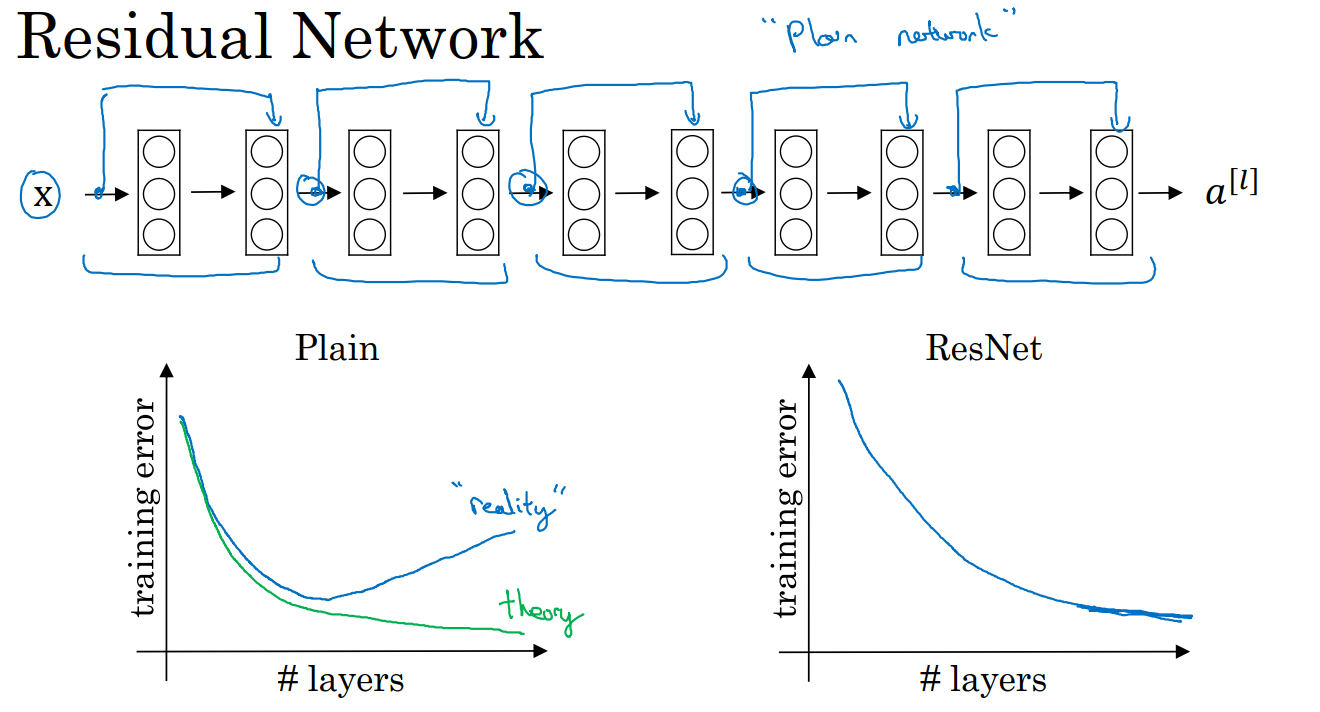
5、残差网络:ResNets
采用了 跳远连接。即a【l+2】= g(Z【l+2】 + a【l】),a【l】作为a【l+2】的残差,g为激活函数。
起作用的原因是:假如Z【l+2】=0,则a【l+2】=a【l】。有时候神经网络深度过大,则

转载于:https://www.cnblogs.com/Lee-yl/p/10015541.html
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/101298.html原文链接:https://javaforall.net


