
大家好,又见面了,我是全栈君。
前言:
游戏领域, 特别是移动端的社交类游戏, 排行榜成为了一种增强体验交互, 提高用户粘性的大法宝. 这边讲述在不同用户规模下, 游戏服务化/游戏平台化趋势下, 如何去设计和实现游戏排名榜. 本文侧重于传统关系型Mysql的方案实现, 后续会讲解Nosql的作用. 小编(mumuxinfei)对这块认识较浅, 所述观点不代表主流(工业界)做法, 望能抛砖引玉.
需求分析
曾几何时, 微信版飞机大战红极一时. 各路英雄刷排名, 晒成绩. 不过该排名限制在自己的好友圈中, 而每个用户的好友圈各不一样, 因此每个用户有自己的排名. 且排名按周重置清零. 一些简单的移动端游戏(比如2048, 没有好友概念), 则采用简单的全局排名的方式, 且排名采用历史最高.

综上的列子, 对于游戏排行榜, 我们可以依据属性来进行划分.
1). 按是否属于好友圈划分
* 游戏全局的Top N模式.
* 以自身好友圈为界的Top N模式.
2). 按时间周期来划分
* 按时间周期重置, 比如按周清零
* 历史最高, 没有重置清零机制
基础篇:
社交类游戏, 在小规模用户的前提下, 借助关系型数据库(mysql)来实现, 采用单库单表.
定义好友表tb_friend
CREATE TABLE IF NOT EXISTS tb_friend ( id INT PRIMARY KEY AUTO_INCREMENT, user_id varchar(64), friend_id varchar(64), UNIQUE KEY `idx_tb_friend_user_id_friend_id` (`user_id`, `friend_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
用户得分表tb_score
CREATE TABLE IF NOT EXISTS tb_score ( id INT PRIMARY KEY AUTO_INCREMENT, user_id varchar(64), score int, UNIQUE KEY `idx_tb_score_user_id` (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
评注: tb_friend表中user_id/friend_id构成复合索引, 用于维护user_id的好友列表, tb_score用于记录每个用户的得分情况
在该两张表的前提之下, 如何获取该好友的排行榜呢?
利用两表join来实现:
SELECT tf.friend_id AS friend_id, ts.score AS score FROM tb_friend tf JOIN tb_score ts ON tf.friend_id = ts.user_id WHERE tf.user_id = ? ORDER BY ts.score DESC
类似的结果如下:
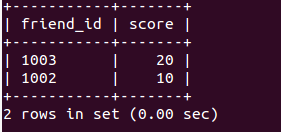
评注: 在sql的join中, 需要注意left join/equal join/right join的区别. 这边选用等值join.
性能评估和执行分析:
1). 小表+大表模式: 在tb_friend单表9801条(100个小伙伴, 互为好友)/tb_score单表53条(53个小伙伴有得分)记录下, 进行join分析
执行规划
EXPLAIN SELECT tf.friend_id AS friend_id, ts.score AS score FROM tb_friend tf JOIN tb_score ts ON tf.friend_id = ts.user_id WHERE tf.user_id = ? ORDER BY ts.score DESC

评注: 这边sql优化器非常的智能, 借助了小表驱动大表的join优化方式(小表tb_score驱动大表tb_friend进行join), 小表用到了file sort(总共53行记录), 大表用了index(等值join对应一行大表记录).
2). 等表模式: 在tb_friend单表19602条/tb_score单表5092条记录下, 进行join分析

评注: 这边tb_friend表驱动tb_score作join, tb_friend借助复合索引(user_id,friend_id)来加速优化. Mysql的sql优化器还是相当的智能和强大.
进阶篇:
随着数据规模越来越大, 并发访问量的增加, mysql的访问逐渐变成瓶颈. 同时该join的sql语句涉及的filesort非常耗CPU的. 如何破解这种状况?
*) 引入分布式mysql集群, 进行分库分表.
分库分表作为互联网的一大神器, 作用立竿见影. 但是有所得,就会有所失, 分库分表后, 会失去很多特性. 比如事务性, 外键约束关联. 在业务这层, 会导致涉及用户的tb_score, tb_friend表数据不在同一库中, 进而导致join失效. 最终导致, 在应用层做merge, 使得排名操作演变成 1+N sql操作(1 sql 用于获取好友列表, N sql 用于获取每个好友的得分). 这需要注意.
1+N的SQL演化, 应用层做得分排序, 性能会演变成一场灾难.
(1) 获取用户好友列表 SELECT friend_id FROM tb_friend_{N} WHERE user_id = ? (2) 遍历获取每个好友的得分 foreach friend_id in friend_list(?) SELECT score FROM tb_score_{M} WEHRE user_id = ? (3) 应用层做得分排序
评注: {N},{M}是指具体的分表数, 当然在同一库同一表, 可以借助SELECT * IN (…)来优化,这个得看具体的数据分布. 不过是种很好的思路.
小编观点: 由于tb_friend是大表, 而tb_score是小表, 因此tb_friend采用分库分表(以user_id作为依据)的方式去实现, 而tb_score采用单库单表(便于批量查询)的方式实现.
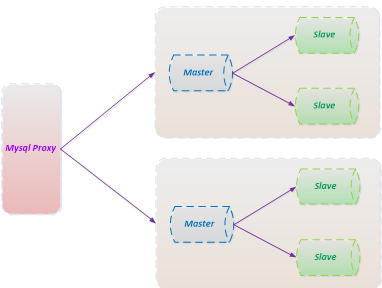
当然在工业界, Mysql的优化方案非常的成熟, 不光是分库分表,还有主从分离(Master/Slave机制, Master用于写服务, 多Slave节点提供读服务).
可以参见如下的图示:
总结&后续:
这边主要讲述基于传统关系型数据库mysql来实现基于好友的游戏排行榜, 个人的战绩需要实时的去获取, 而好友列表的战绩能允许有一定的延迟. 而好友战绩的排序实现,就成为了本文的中心议题. Mysql的实现方案在数据量/并发数增加的前提下,还是显示了一定的疲态. 下文将讲解, 如何引入Nosql系统, 在游戏rank中,扮演重要的角色. 期待你的关注.
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/108752.html原文链接:https://javaforall.net


