

由于各种原因,之前做好的推荐系统没有上线,我将我们推荐系统初步的一些资料整理下,供大家交流参考。
整个结构借鉴了predictionio,如下图:
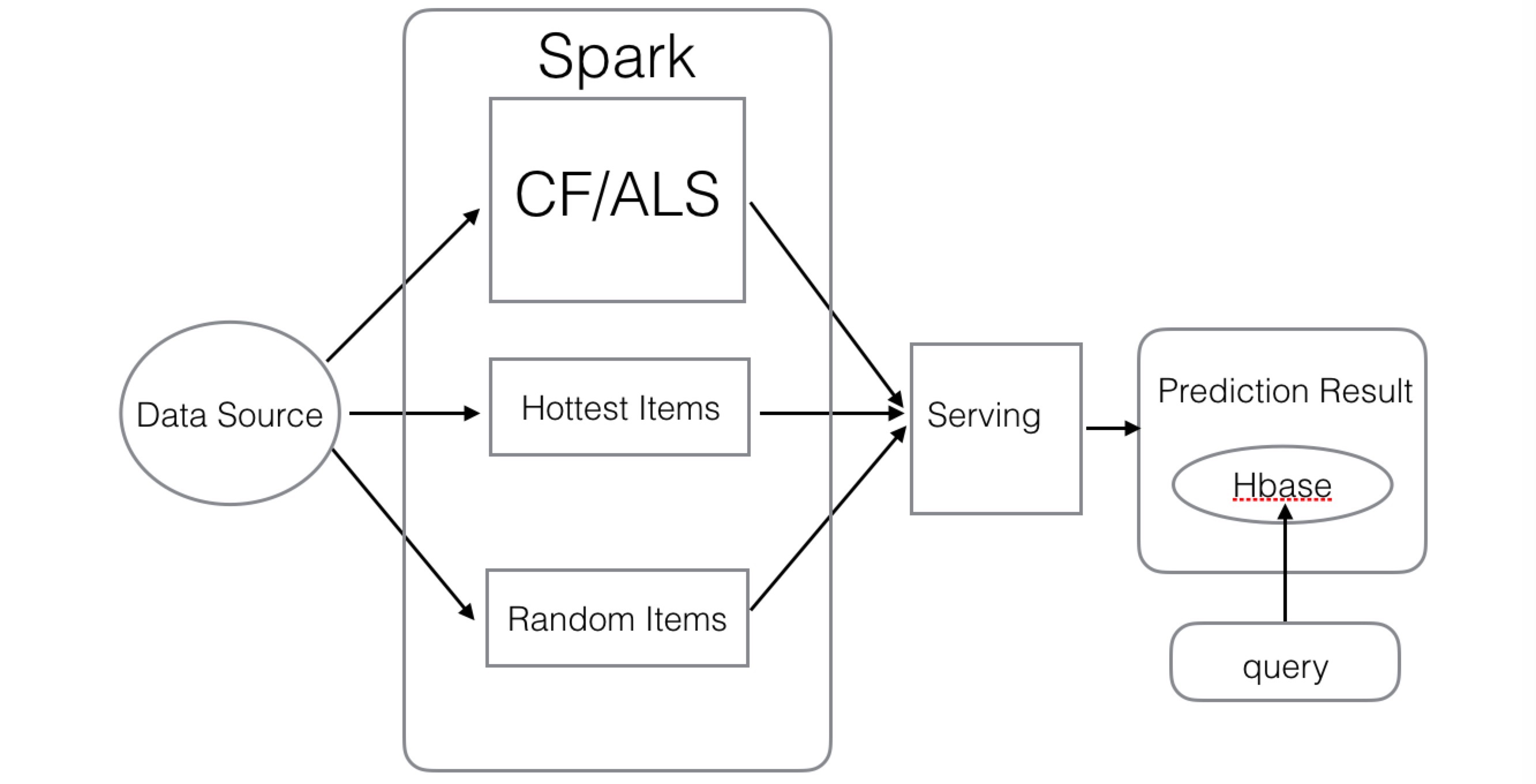

模型training在spark上完成,每次都输出对每一个用户的预测结果,并将预测结果保存在Hbase中。多模型/多规则预测结果的融合主要在Serving部分完成。每次需要拿该针对用户推荐的结果其实也可以像predictionio一样,将traning好的model persist在local file system或者hdfs上,但是各有优劣,具体还是要看应用场景。
转载于:https://my.oschina.net/u/1450520/blog/738302
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/108898.html原文链接:https://javaforall.net


