
大家好,又见面了,我是全栈君。
本学习笔记内容部分来自网易云课堂浙江大学数据结构视频,及海子的博客:http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html以及~大器晚成~的博客http://www.cnblogs.com/luchen927/archive/2012/02/29/2368070.html
1、选择排序
基本思想:
在一个长度为N的无序数组中。在第一趟遍历N个数据,找出当中最小的数值与第一个元素交换,第二趟遍历剩下的N-1个数据,找出当中最小的数值与第二个元素交换……第N-1趟遍历剩下的2个数据,找出当中最小的数值与第N-1个元素交换。至此选择排序完毕。
在一个长度为N的无序数组中。在第一趟遍历N个数据,找出当中最小的数值与第一个元素交换,第二趟遍历剩下的N-1个数据,找出当中最小的数值与第二个元素交换……第N-1趟遍历剩下的2个数据,找出当中最小的数值与第N-1个元素交换。至此选择排序完毕。
举例:选择排序:56 12 80 91 20
第一次:遍历这5个数。找到最小值12。位置在2,交换1和2位置的数字,12 56 80 91 20
第二次:遍历剩下的4个数。找到最小值20。位置在5,交换2和5位置的数字,12 20 80 91 56
依次类推

2、堆排序
是对选择排序的改进
基本思想:
1、将初始待排序keyword序列(R1,R2….Rn)构建成最大堆。此堆为初始的无序区;
2、将堆顶元素R[1]与最后一个元素R[n]交换。此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
3、因为交换后新的堆顶R[1]可能违反堆的性质,因此须要对当前无序区(R1,R2,……Rn-1)调整为新最大堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。
不断反复此过程直到有序区的元素个数为n-1。则整个排序过程完毕。
举例:堆排序:
16,7,3,20,17,8
第一次:构建初始最大堆:
到,此时交换最大值20和堆最后一个位置元素得到 第二次:除20外剩下的元素继续调整为最大堆,之后再交换顶点最大值和倒数第二个位置的元素。得到:
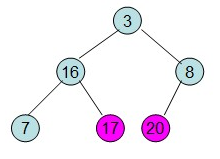
依次类推
对N个元素进行堆排序,最坏情况下时间复杂度为O(NlogN)
3、归并排序
核心:有序子列的归并
两个有序子列归并算法例如以下:
归并算法基本思想:
将待排序文件看成为n个长度为1的有序子文件,把这些子文件两两归并,得到「n/2」个长度为2的有序子文件;然后再把这「n/2」个有序文件的子文件两两归并。如此重复,直到最后得到一个长度为n的有序文件为止。这样的排序方法成为二路归并排序。
将待排序文件看成为n个长度为1的有序子文件,把这些子文件两两归并,得到「n/2」个长度为2的有序子文件;然后再把这「n/2」个有序文件的子文件两两归并。如此重复,直到最后得到一个长度为n的有序文件为止。这样的排序方法成为二路归并排序。
举例:归并排序:72 18 53 36 48 31 36
第一趟:18 72|36 53|31 48|36
第二趟:18 36 53 72|31 36 48
第三趟:18 31 36 36 48 53 72
算法:分而治之:
归并排序非递归的算法须要额外的空间O(N)
4、高速排序
基本思想:
高速排序是找出一个元素(理论上能够随便找一个)作为基准(pivot),然后对数组进行分区操作,使基准左边元素的值都不大于基准值,基准右边的元素值 都不小于基准值,如此作为基准的元素调整到排序后的正确位置。递归高速排序。将其它n-1个元素也调整到排序后的正确位置。最后每一个元素都是在排序后的正 确位置。排序完毕。
高速排序是找出一个元素(理论上能够随便找一个)作为基准(pivot),然后对数组进行分区操作,使基准左边元素的值都不大于基准值,基准右边的元素值 都不小于基准值,如此作为基准的元素调整到排序后的正确位置。递归高速排序。将其它n-1个元素也调整到排序后的正确位置。最后每一个元素都是在排序后的正 确位置。排序完毕。
怎样选基准??算法Median3 想法是把左、中、右三个位置最小的元素放到最左边,然后返回中间位置那个数做为基准
选定基准后,怎样划分子集呢?左右各一个指针,分别往中间走,当左右指针各不正确时(左边大于基准、右边小于基准为不正确的情况)。左右指针指的数字交换。
举例:
2 2 4 9 3 6 7 1 5 首先用2当作基准,使用i j两个指针分别从两边进行扫描,把比2小的元素和比2大的元素分开。首先比較2和5,5比2大,j左移
2 2 4 9 3 6 7 1 5 比較2和1。1小于2,所以把1放在2的位置
2 1 4 9 3 6 7 1 5 比較2和4,4大于2,因此将4移动到后面(原来1的位置)
2 1 4 9 3 6 7 4 5 比較2和7,2和6,2和3。2和9,所有大于2。满足条件,因此不变
经过第一轮的高速排序,元素变为以下的样子
[1] 2 [4 9 3 6 7 5]
之后,在把2左边的元素进行快排。因为仅仅有一个元素,因此快排结束。右边进行快排。递归进行,终于生成最后的结果。
注:当递归的数据规模充分小时。则停止递归,直接调用简单排序就可以了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/116186.html原文链接:https://javaforall.net

![java文件上传总结[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
