
大家好,又见面了,我是你们的朋友全栈君。
如果对LSTM原理不懂得小伙伴可以看博主下一篇博客,因为博主水平有限,结合其他文章尽量把原理写的清楚些。
数据集
首先附上数据集
链接:https://pan.baidu.com/s/1AKsz-ohmYHr9mBEEh76P5g
提取码:6owv
这个数据集是关于股票的,里面有日期,开盘价等信息。
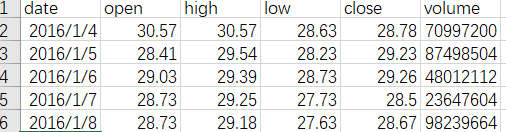

既然是时间序列预测,我们最关心的是预测值在时间维度上的走势如何,那我们只要最后一列volume和第一列date这两列就好了。
实战
先是导入相关包,一些常见的包就不详细说了,我们需要的Sequential,Dense, Activation, Dropout,这些可以在博主上几期关于keras的实战介绍。mean_squared_error是sklearn里面一个评价模型好坏的指标,相对来说越小越好,但也要看数据集值的范围。MinMaxScaler是一个归一化的包,归一化有很多好处,可以让模型算的更快,一些求导呀,梯度下降这些的,归一化后数据小,这些算法自然就运行快。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras import optimizers
import time
这个是创建变量x和y的,因为lstm时间序列不像别的回归一个x,另一个值y,lstm的x和y全是一组数据产生的,也就是它自己和自己比。有一个关键的参数是look_back这个按中文直译就是回看,回溯,理解起来也很容易,假如是这个data是[1,2,3,4,5],look_back为1的话.
x
[[1]
[2]
[3]] y就是[2 3 4],意思就是用前一个数据预测后一个,这是look_back为1的意思。假如是为8,那前8个数据预测第9个数据。小伙伴们可以试试改变这个值,看一下结果是否会更好。
注意维度,维度这样设置一是归一化需要,二是输入网络的要求。
下面这个函数功能就是把data,
def creat_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i: (i+look_back)]
dataX.append(a)
dataY.append(dataset[i+look_back])
return np.array(dataX), np.array(dataY)
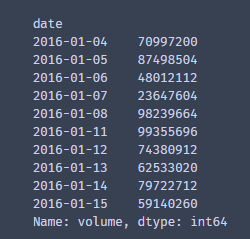
读取一下数据,这些参数的意思是,输出series,series的序号就是date,这样方便下面画图,看着也更加直观。因为我们只要首尾2列,那就是0,5.
dataframe = pd.read_csv('zgpa_train.csv',
header=0, parse_dates=[0],
index_col=0, usecols=[0, 5], squeeze=True)
dataset = dataframe.values
dataframe.head(10)
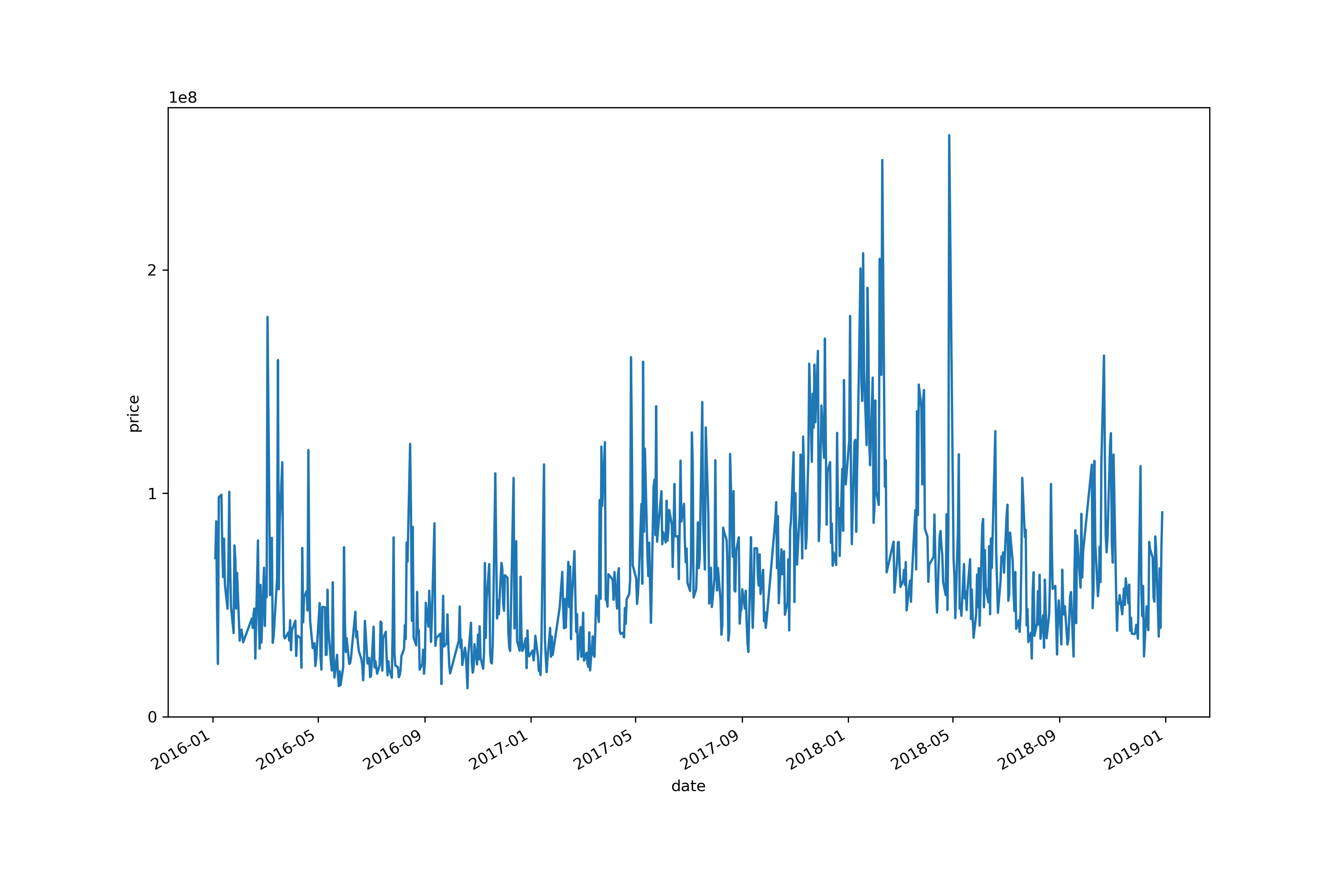
这里就画一下图,之所以弄成series就是为了用pandas画图。
plt.figure(figsize=(12, 8))
dataframe.plot()
plt.ylabel('price')
plt.yticks(np.arange(0, 300000000, 100000000))
plt.show()
这里就是归一化操作,有一个feature_range=(0, 1)这个意思是所有数据标准化到0-1区间内,就是归一化的意思,如果(0,100)那就是标准化到0-100这个区间。最后把它转换成列向量
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset.reshape(-1, 1))
分割数据集,这个很好理解,一会用来测试。
train_size = int(len(dataset)*0.8)
test_size = len(dataset)-train_size
train, test = dataset[0: train_size], dataset[train_size: len(dataset)]
调用前面函数分别生成训练集和测试集的x,y。
look_back = 1
trainX, trainY = creat_dataset(train, look_back)
testX, testY = creat_dataset(test, look_back)
建立模型,这里注意下如果是多层lstm的话一定要注意前后维度对接,也就是input和output维度,当前层的input维度是上一次层的output维度。return_sequences=True表示返回这个维度给下面。
剩下的就是很基础且通用的配置了。更详细的在博主另一篇关于keras的实战。
model = Sequential()
model.add(LSTM(input_dim=1, output_dim=50, return_sequences=True))
#model.add(Dropout(0.2))
model.add(LSTM(input_dim=50, output_dim=100, return_sequences=True))
#model.add(Dropout(0.2))
model.add(LSTM(input_dim=100, output_dim=200, return_sequences=True))
#model.add(Dropout(0.2))
model.add(LSTM(300, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(100))
model.add(Dense(output_dim=1))
model.add(Activation('relu'))
start = time.time()
model.compile(loss='mean_squared_error', optimizer='Adam')
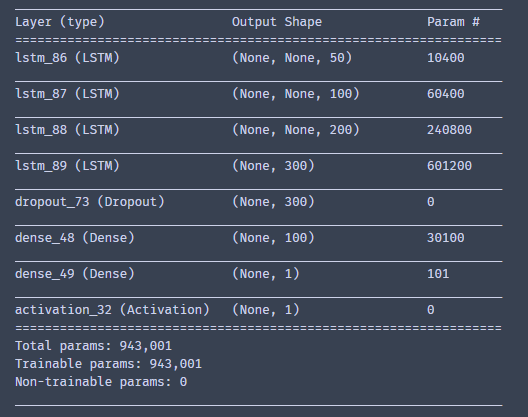
model.summary()
查看一下结构,我们建立的网络层数不多,参数也不多,还不到100万。
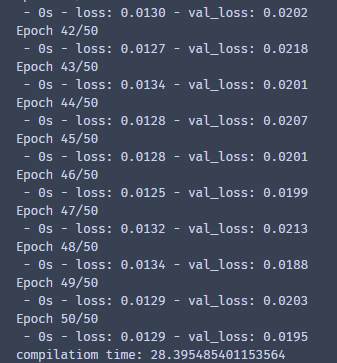
设置了个时间,很快,半分钟都不到就训练完50个epoch。validation_split=0.1表示拿出训练集的10%作为验证集,有了验证集能够更好的训练模型,就相当于给模型纠错。 verbose=2表示打印出每个epoch的信息,默认是1,1的话就更好看,因为有个进度条和时间。小伙伴们不妨试试。这里有个history,意思也很容易理解,训练的历史过程,下面会阐述用处。
history = model.fit(trainX, trainY, batch_size=64, nb_epoch=50,
validation_split=0.1, verbose=2)
print('compilatiom time:', time.time()-start)
这就很简单了,把数据丢进去预测。
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
因为前面进行了归一化,现在的数据都是0-1之间的,这里的作用就是反归一化,让它恢复原来数据范围。
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
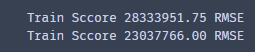
打印一下评分,写到这博主发现小错误,不过懒得改了,下面那个是test score。看到我们的score都非常大,那这是不是说明我们模型很差劲,并不是,这个评分只能参考参考,并不是很绝对。因为我们数据值大,数据都是10的8次方左右。稍微有一点偏差,假如是原来值800000000,预测750000000,其实相差不大,误差才1/16,但是数值大,数值的误差有50000000.这样再平方根号一系列操作后,有可能会更大也有可能变小。总之这个指标只是参考参考。博主写到这里猜想,如果拿没有反归一化的数据进行评分那么是不是评分就很小呢?小伙伴们可以试试。
trainScore = math.sqrt(mean_squared_error(trainY, trainPredict[:, 0]))
print('Train Sccore %.2f RMSE' %(trainScore))
testScore = math.sqrt(mean_squared_error(testY, testPredict[:, 0]))
print('Train Sccore %.2f RMSE' %(testScore))
接下来的操作是为了画图,首先empty_like方法表示创建一个空数组,这个空数组很像dataset,为什么呢,因为维度一样,但是值还没初始化。然后我们让其全为空后进行填值。最后一行的操作相当于是一个100个数值的数值,我填了前面70个,因为前面70个是我训练集的预测值,后面30为空。
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:] = np.nan
trainPredictPlot = np.reshape(trainPredictPlot, (dataset.shape[0], 1))
trainPredictPlot[look_back: len(trainPredict)+look_back, :] = trainPredict
那么这里同理,一个100个数值的数值,前面70个为空,那么后面30个就由我测试集的预测值来填充。
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:] = np.nan
testPredictPlot = np.reshape(testPredictPlot, (dataset.shape[0], 1))
testPredictPlot[len(trainPredict)+(look_back*2)+1: len(dataset)-1, :] = testPredict
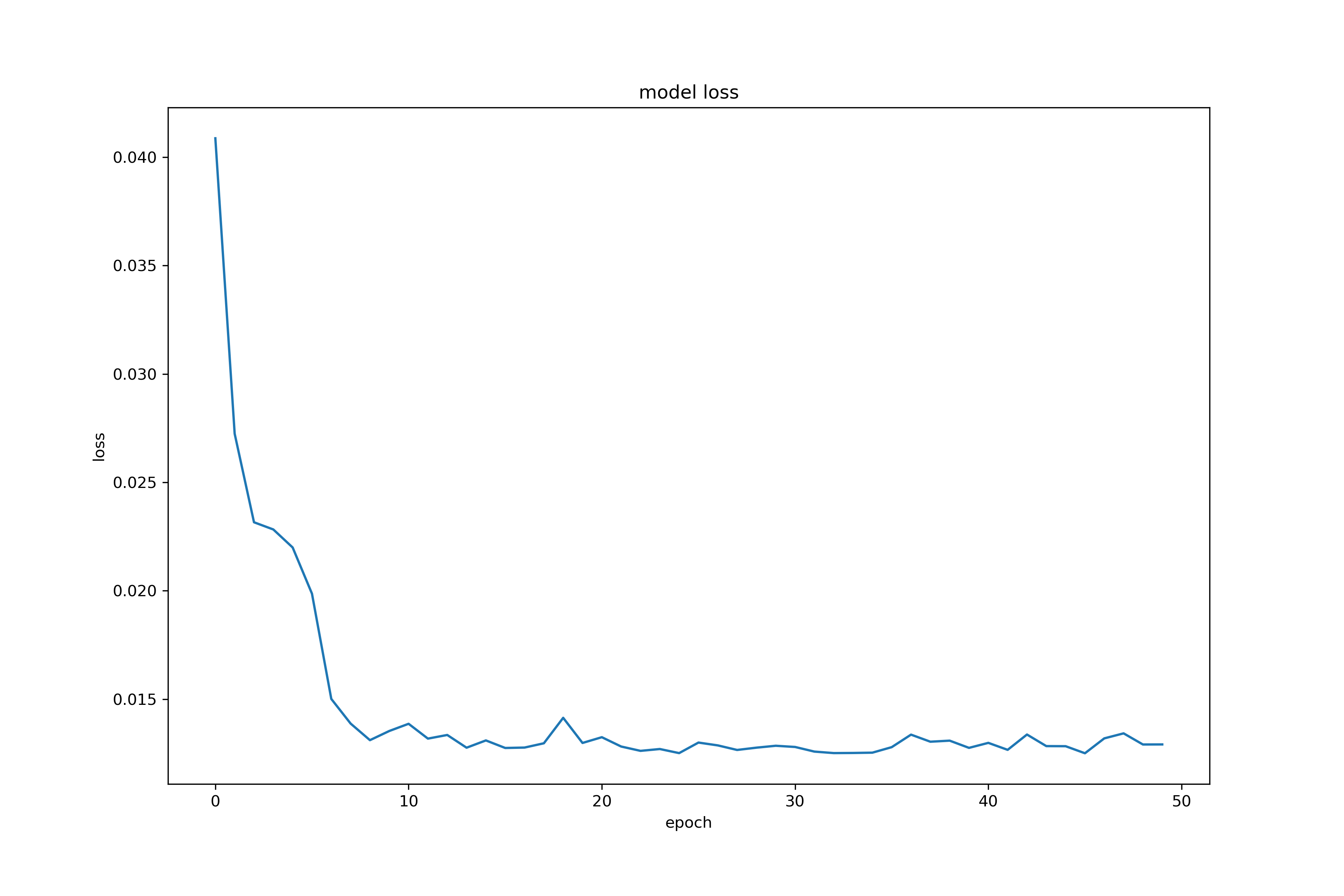
这就是前面history的作用了,相当于是记录下来里面训练过程的一些参数变化吧。有一个很重要的就是损失,可以看到我们的损失下降很快,最后也收敛到一个很小的值,还是很不错的。
fig1 = plt.figure(figsize=(12, 8))
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
画图。
fig2 = plt.figure(figsize=(20, 15))
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.ylabel('price')
plt.xlabel('date')
plt.show()
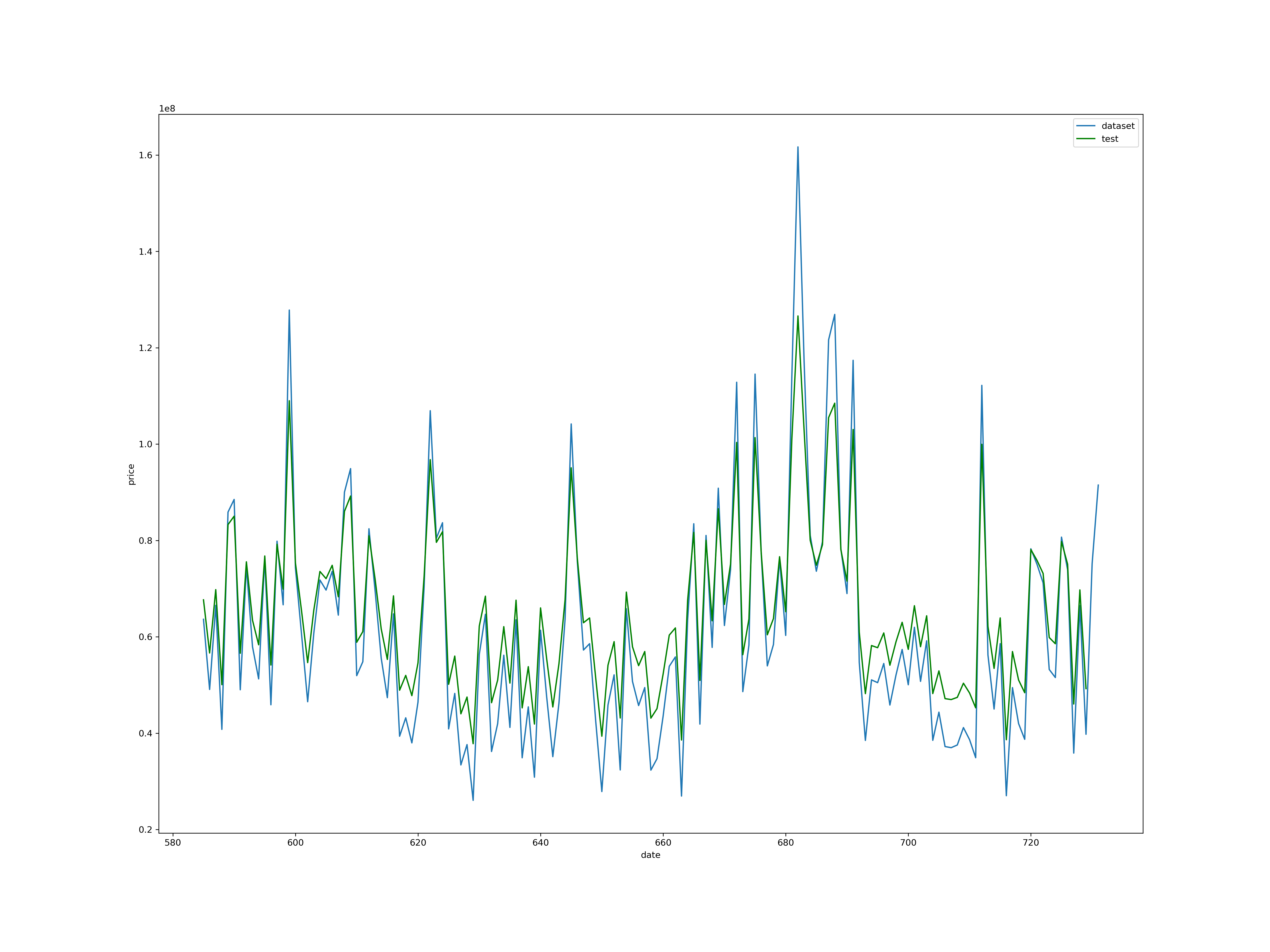
蓝色是原始数据,黄色是训练数据训练完再进行预测的。绿色是测试数据。可以看出我们大概趋势是非常符合的。但是有些地方的峰值预测的不够。但整体效果还算不错。
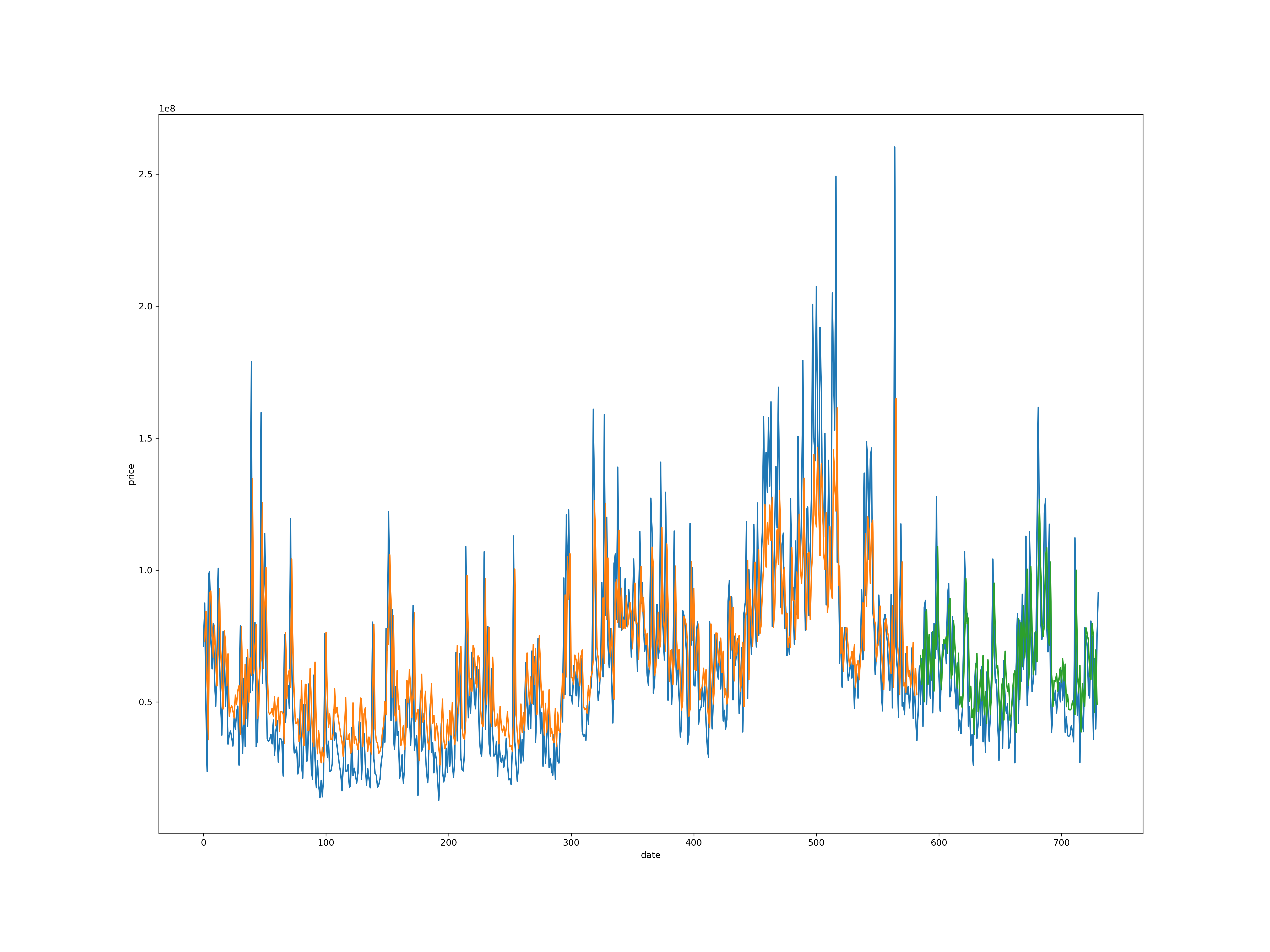
fig3 = plt.figure(figsize=(20, 15))
plt.plot(np.arange(train_size+1, len(dataset)+1, 1), scaler.inverse_transform(dataset)[train_size:], label='dataset')
plt.plot(testPredictPlot, 'g', label='test')
plt.ylabel('price')
plt.xlabel('date')
plt.legend()
plt.show()
我们把预测的拿出来放大看看。绿色是测试的预测值,蓝色的是原始数据,和前面说的一样,趋势大概相同,但是峰值有误差。还有一个问题就是博主这里的代码是将预测值提前一天画的。因为真实预测出来会有滞后性,就看起来像是原始数据往后平移一天的缘故。但博主查阅了很多资料,暂时没发现很方便能消除lstm滞后性的办法。所以博主姑且认为测试集预测值提前一天的效果为最佳效果,这也是为什么上面代码要+1的原因。如果小伙伴们知道如何方便快捷消除lstm时间序列预测的滞后性,记得给博主留言噢。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/126401.html原文链接:https://javaforall.net


