
大家好,又见面了,我是你们的朋友全栈君。
python正则匹配汉字的规则为:[\u4e00-\u9fa5]
后面可以加一个+,匹配多个汉字。
例子如下:
print(re.findall(r'[\u4e00-\u9fa5]+', '这是测试用例'))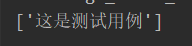

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/128085.html原文链接:https://javaforall.net


