
大家好,又见面了,我是你们的朋友全栈君。
在论文中看到L1正则化,可以实现降维,加大稀疏程度,菜鸟不太懂来直观理解学习一下。
在工程优化中也学习过惩罚函数这部分的内容,具体给忘记了。而正则化正是在损失函数后面加一个额外的惩罚项,一般就是L1正则化和L2正则化。之所以叫惩罚项就是为了对损失函数(也就是工程优化里面的目标函数)的某个或些参数进行限制,从而减少计算量。


L1正则化的损失函数是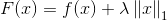 是不光滑的,
是不光滑的,
L2正则化的损失函数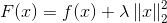 是光滑的。
是光滑的。
从下图理解更加直观:
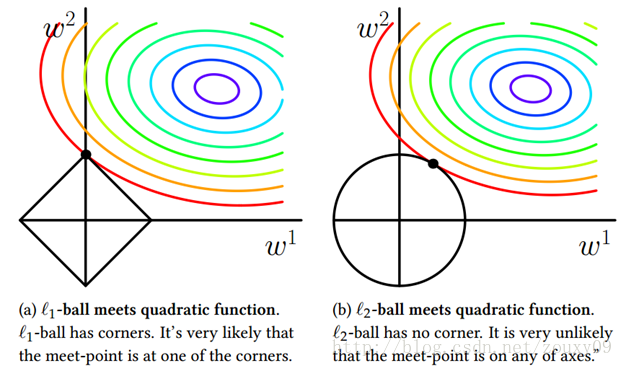
左图为L1正则化,若考虑二维的情况,即只有两个权值 w 1 , w 2 \ w^1,w^2\, w1,w2,令L1正则化的修正项为L = ∣ w 1 ∣ + ∣ w 2 ∣ \ |w^1|+|w^2|\, ∣w1∣+∣w2∣的约束条件下(图中的黑色框)求原损失函数的最小值(图中的等值线),可以看出,当等值线与L图形首次相交的地方就是最优解,上图中在上方顶点处相交,这个顶点就是最优解,这其中可以看出 w 1 \ w^1\, w1 = 0,从而就达到了减少参数产生稀疏模型,进而可以用于特征选择。
同理右图为L2正则化的过程,可以想到L2正则化中磨去了棱角,例如在图中相交的那一点,此时两个参数都不为零,所以L2正则化不具有稀疏性。
参考:
https://blog.csdn.net/jinping_shi/article/details/52433975
https://blog.csdn.net/qq_32742009/article/details/81629210
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/128144.html原文链接:https://javaforall.net


