
大家好,又见面了,我是你们的朋友全栈君。
本文参考了美团团队的介绍文章。
https://tech.meituan.com/deep_understanding_of_ffm_principles_and_practices.html
以及
http://blog.csdn.net/zc02051126/article/details/54614230
FM和FFM模型是最近几年提出的模型,凭借其在数据量比较大并且特征稀疏的情况下,仍然能够得到优秀的性能和效果的特性,屡次在各大公司举办的CTR预估比赛中获得不错的战绩。
FM原理
FM模型的提出旨在解决稀疏数据下的特征组合问题。假设一个广告分类问题,根据广告位信息和用户信息,预测用户是否点击广告。
| Clicked? | Country | Day | Ad_type |
|---|---|---|---|
| 1 | USA | 26/11/15 | Movie |
| 0 | China | 1/7/14 | Game |
| 1 | China | 19/2/15 | Game |
三个特征都是类别型特征,经过one-hot编码
| Clicked? | Country=USA | Country=China | Day=26/11/15 | Day=1/7/14 | Day=19/2/15 | Ad_type=Movie | Ad_type=Game |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
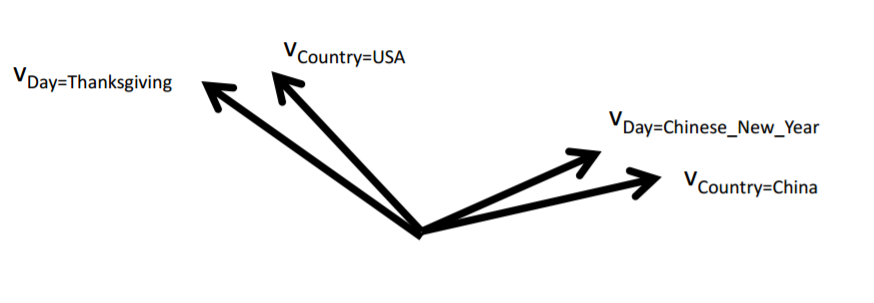
通过观察可以发现,某些特征经过关联会更加有意义。比如Country=USA和Day=26/11/15(感恩节),Country=USA和Day=19/2/15(春节)这样的关联对用户的点击有着正向的影响。而一些其他的组合(Country=USA和Day=26/11/15)可能对用户点击并没有那么强烈的影响。因此引入两个特征的组合是非常有意义的。
多项式模型是包含特征组合最直观的模型,模型表达式如下
其中, n n 代表样本特征数量,
xi
是第 i i 个特征的值,
w0,wi,wij
是模型参数。
从公式可以看出,组合特征的参数一共有 n(n−1)2 n ( n − 1 ) 2 种,任意两个参数是独立的。
当我们想把这个模型运用到点击率预测时,会发现训练每个二次项系数都需要大量的 xi x i 和 xj x j 都非0的样本。而由于经过了one-hot编码,数据变得很稀疏,导致训练样本的不足, wij w i j 会不准确,因此二次项参数的训练是变得困难,验证影响模型的性能。
那么如何解决这个问题呢?矩阵分解提供了思路。
vi v i
是k维的向量
idea的来源是不同的组合特征之间相互不是独立的,他们之间的联系通过一个隐因子建立。
例如在协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以用一个隐向量表示,下例中把一个user表示成一个二维向量,同时把每个item表示成一个二维向量,两个向量的点积就是矩阵中user对item的打分。

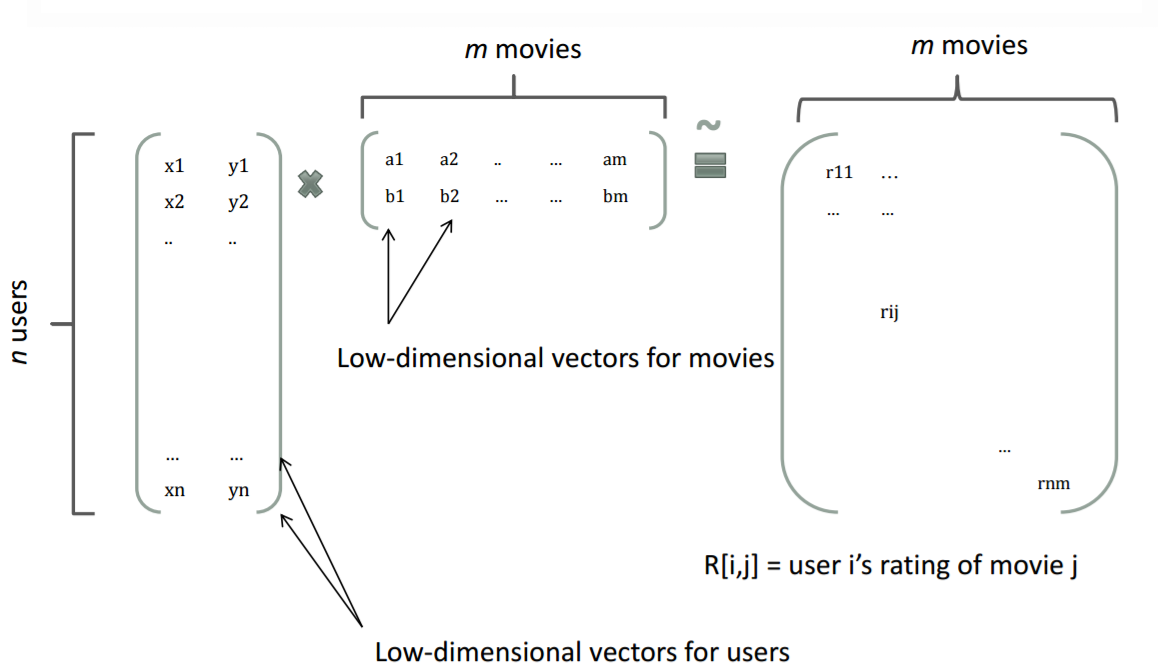
类似的,所有的二次项系数 wij w i j 可以组成一个对称阵W,那么这个矩阵就可以分解为 VTV V T V ,V的第j列就是第j维特征的隐向量。因此,FM的模型方程为
其中,
vi v i
是第
i i
维特征的隐向量,<·,·>代表点积。隐向量的长度为
k(k<<n)
包含
k k
个描述特征的因子。
这样变换后,二次项的参数减少到
个,远少于多项式模型的参数数量。而且参数之间有了联系,比如
xhxi x h x i
和
xixj x i x j
的系数分别是
<vh,vi> < v h , v i > <script type="math/tex" id="MathJax-Element-22"> </script> 和
<vi,vj> < v i , v j > <script type="math/tex" id="MathJax-Element-23"> </script> 他们之间有共同项
vi v i
,这样所有包含
xi x i
的非零组合特征的样本都可以用来学习隐向量
vi v i
,很大程度上避免了数据稀疏造成的影响。
直观上看,FM的复杂度是
O(kn2) O ( k n 2 )
。通过下面式子化简,复杂度可以优化到
O(kn) O ( k n )
推导过程如下
利用SGD(Stochastic Gradient Descent)训练模型,梯度如下
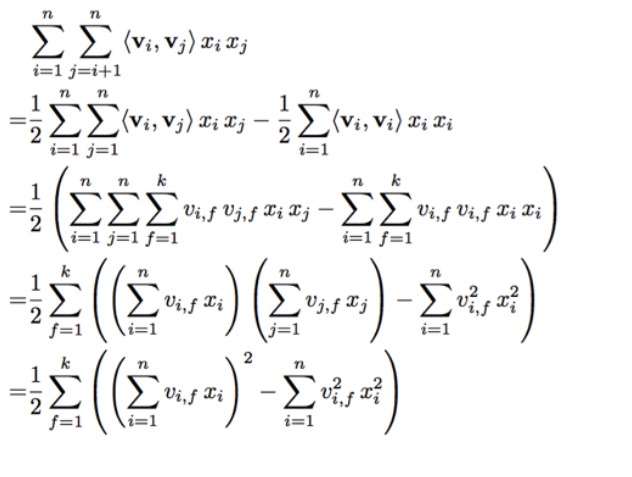
其中,
vj,f v j , f
是隐向量
vj v j
的第
f f
个元素,由于
只与
f f
有关,在每次迭代时只需计算一下所有
的
∑nj=1vj,fxj ∑ j = 1 n v j , f x j
就能够方便的得到所有
vj,f v j , f
的梯度,复杂度为
O(kn) O ( k n )
;已知
∑nj=1vj,fxj ∑ j = 1 n v j , f x j
时,计算每个参数梯度的复杂度是
O(1) O ( 1 )
;得到梯度后,更新每个参数的复杂度是
O(1) O ( 1 )
;模型参数一共有
nk+n+1 n k + n + 1
个。因此,FM参数训练的复杂度也是
O(kn) O ( k n )
。综上,FM可以在线性时间训练和预测,是一个非常高效的模型。
FFM原理
ffm引入了field的概念。不同field之间的隐因子变得不同。用 <vi,f(j),vj,f(i)> < v i , f ( j ) , v j , f ( i ) > <script type="math/tex" id="MathJax-Element-45"> </script> 代替 <vi,vj> < v i , v j > <script type="math/tex" id="MathJax-Element-46"> </script>,其中 f(i) f ( i ) 是特征 i i 所属的field。
简单来说,同一个类别型特征经过one-hot编码后的都可以放到同一个field中。
为什么要引入field这个概念呢?我的理解是FM模型的二次项参数是一个个相互独立的数,但是特征之间在根本上还是有原始类别的,FM模型并没有体现出这一点。现在把之前一个个的数变成了一个个的向量
这样特征之间就有了域的概念了。
假设样本的n个特征属于f个field,那么FFM的二次项有nf个隐向量。而在FM中,每一维特征的隐向量只有一个。FM可以看做是只有一个field的FFM模型。FFM的模型方程如下
其中,
fj f j
是第
j j
个特征所属的field。如果隐向量的长度为
, 那么FFM的二次参数有
nfk n f k
个,远多于FM模型的
nk n k
个。此外,由于隐向量与field相关,FFM的二次项不能化简,其预测的复杂度是
O(kn2) O ( k n 2 )
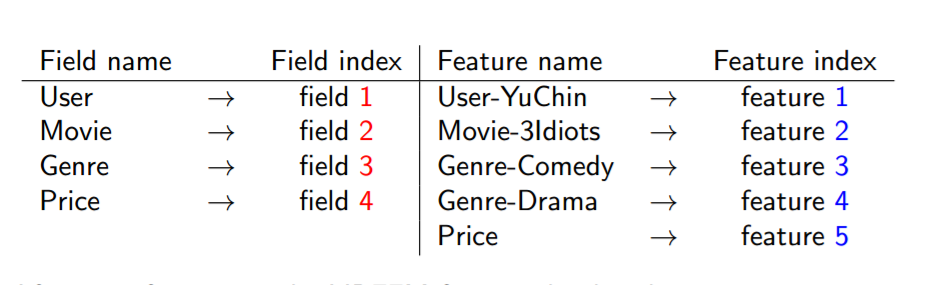
FFM的编码格式如下
数据
| User | Movie | Genre | Price |
|---|---|---|---|
| YuChin | 3Idiots | Comedy,Drama | $9,99 |
FFM格式
转换成LIBFFM格式为
1:1:1 2:2:2 3:3:1 3:4:1 4:5:9.99
FFM的组合有10项,如下图所示

LIBFFM
台湾大学开发的libffm网址 http://www.csie.ntu.edu.tw/~cjlin/libffm/
这个版本的ffm省略了常数项和一次项。模型方程如下
其中
C2 C 2
是非零特征的二元组合,
j1 j 1
是特征。属于field
f1 f 1
,
wj1,f2 w j 1 , f 2
是特征
j1 j 1
对field
f2 f 2
的隐向量。此FFM模型采用Logistic loss作为损失函数,L2惩罚项,因此只能用于二元分类
−yiϕ(w,xi)})+λ2||w||2 min w ∑ i = 1 L l o g ( 1 + e x p { − y i ϕ ( w , x i ) } ) + λ 2 | | w | | 2
算法采用SGD优化过程,在寻优时,采用了一些小技巧
第一,梯度分布计算。采用SGD训练FFM模型时,只采用单个样本的损失函数来计算模型参数的梯度。
−yiϕ(w,xi)})+λ2||w||2 L = L e r r + L r e g = l o g ( 1 + e x p ( { − y i ϕ ( w , x i ) } ) + λ 2 | | w | | 2
上面公式表明,
∂err∂ϕ ∂ L e r r ∂ ϕ
与具体模型参数无关,因此每次更新模型时,只需计算一次,之后每次调用值即可。
第二,自适应学习率。此版本的FFM实现没有采用常用的指数递减的学习率更新策略,而是利用
nfk n f k
个浮点数的临时空间,自适应地更新学习率。学习率是参考AdaGrad算法计算的,按如下更新
其中,
wj1,f2 w j 1 , f 2
是特征
j1 j 1
对field
f2 f 2
隐向量的一个元素,
gwj1,f2 g w j 1 , f 2
是损失函数对参数
wj1,f2 w j 1 , f 2
的梯度;
gtwj1,f2 g w j 1 , f 2 t
是第t次迭代的梯度;
η η
是初始学习速率。可以看出,随着迭代的进行,每个参数的历史梯度会慢慢累加,导致每个参数的学习率逐渐减小。另外,每个参数的学习率更新速度是不同的,与其历史梯度有关,根据AdaGrad的特点,对于样本比较稀疏的特征,学习率高于样本比较密集的特征,因此每个参数既可以比较快速达到最优,也不会导致验证误差出现很大的震荡。
第三,OpenMP多核并行计算。OpenMP是用于共享内存并行系统的多处理器程序设计的编译方案,便于移植和多核扩展。FFM的源码采用了OpenMP的API,对参数训练过程SGD进行了多线程扩展,支持多线程编译。因此,OpenMP技术极大地提高了FFM的训练效率和多核CPU的利用率。在训练模型时,输入的训练参数ns_threads指定了线程数量,一般设定为CPU的核心数,便于完全利用CPU资源。
第四,SSE3指令并行编程。
除了上面的技巧之外,FFM的实现中还有很多调优技巧需要探索。例如,代码是按field和特征的编号申请参数空间的,如果选取了非连续或过大的编号,就会造成大量的内存浪费;在每个样本中加入值为1的新特征,相当于引入了因子化的一次项,避免了缺少一次项带来的模型偏差等。
使用LIBFFM的时候,注意不同的版本参数有些许不同,在最新的一些版本中没有-on-disk命令,模型默认使用硬盘训练。
源码分析
http://blog.csdn.net/zc02051126/article/details/54614230 介绍的很详细
应用
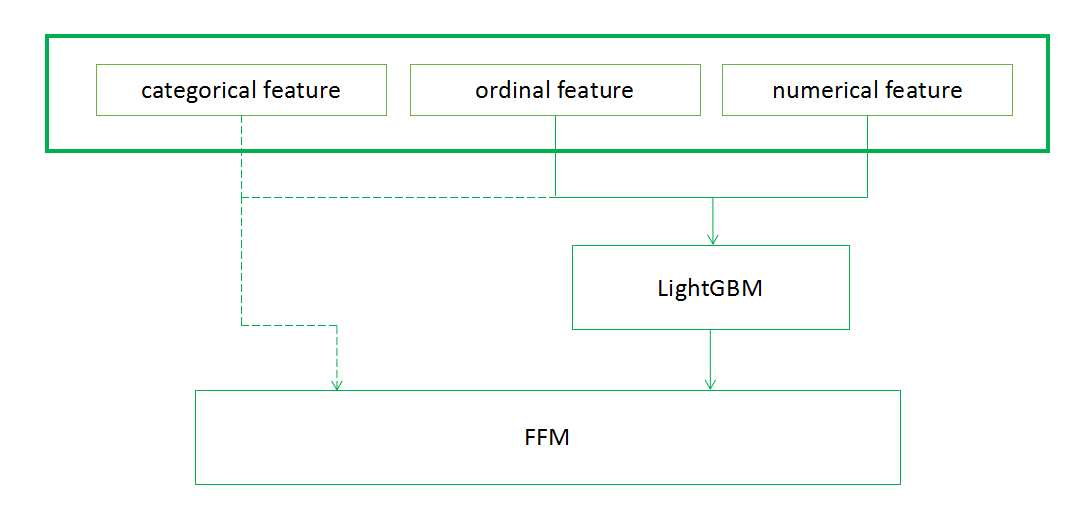
这次腾讯比赛中我们所构造的特征有原始类别型特征和一些统计量特征。
FFM更适用于类别特征,将类别特征onehot编码后输入到FFM中效果更好。
基于GBDT的树模型更适合数值型特征。
当同时拥有这两类特征时,将这两个模型组合起来效果会更好。如下如所示
代码戳
https://github.com/leisurehippo/txbs/blob/master/FFM_train.py
FM和树模型都能自动学习特征交叉组合,树模型适合连续中低度稀疏数据,容易学到高阶组合;FM适合高度稀疏数据。
树模型和简单二阶多项式模型中存在共同问题:不能学习到数据中不存在的模式,但FM可以。这是FM在高度稀疏数据建模优势的关键。
神经网络处理高维稀疏离散特征的一种手段:词向量。FM可以看做一种embedding的方法。word2vec词出现在上下文的概率和两个词向量内积正相关;FM用户和商品的偏好与用户向量和商品向量内积正相关。
FM和embedding都是通过将高维稀疏的离散特征映射为低维向量来增强其特征的泛化能力的。
deep&wide模型
将离散特征做低维嵌入,和连续特征一起放到神经网络里学习高度非线性的特征交叉。wide是将类别特征和数值特征一起学习,deep是一个深度网络,其实就是一些简单的relu和dense。
有点像上面操作的对偶形式?上面最终是用FFM学习类别特征,用xgb将数值特征提取类别特征。这个是用深度网络学习连续数值特征。用embedding的方式将离散高维特征提取低维表示。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/131849.html原文链接:https://javaforall.net


