
大家好,又见面了,我是你们的朋友全栈君。
merge函数的作用是:将两个已经排好序的序列合并为一个有序的序列。
函数参数:merge(first1,last1,first2,last2,result,compare);
firs1t为第一个容器的首迭代器,last1为第一个容器的末迭代器;
first2为第二个容器的首迭代器,last2为容器的末迭代器;
result为存放结果的容器,comapre为比较函数(可略写,默认为合并为一个升序序列)。
注意
使用的时候result,如果用的vector,必须先resize一下,比如:(注意到此时a和b都已经是有序的啦!)
默认升序:
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
#include<cstring>
#include<queue>
#include<stack>
#include<cmath>
#include<set>
#include<map>
using namespace std;
#define ll long long
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
typedef pair<int,int>P;
const int INF=0x3f3f3f3f;
const int N=100005;
vector<int>a,b,c;
int main(){
a.push_back(1);
a.push_back(3);
a.push_back(5);
a.push_back(7);
b.push_back(2);
b.push_back(4);
b.push_back(6);
b.push_back(8);
c.resize(8);
merge(a.begin(),a.end(),b.begin(),b.end(),c.begin());
for(int i=0;i<c.size();i++){
printf("%d ",c[i]);
}
printf("\n");
}
运行结果:


若a,b数组不是有序的,则出来的结果是错的哦!
自定义排序规则
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
#include<cstring>
#include<queue>
#include<stack>
#include<cmath>
#include<set>
#include<map>
using namespace std;
#define ll long long
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
typedef pair<int,int>P;
const int INF=0x3f3f3f3f;
const int N=100005;
struct A{
int x,y;
};
vector<A>a,b,c;
bool cmp(A a,A b){
return a.x<b.x;
}
int main(){
a.push_back({1,9});
a.push_back({3,8});
a.push_back({5,7});
b.push_back({2,1});
b.push_back({4,2});
b.push_back({6,4});
c.resize(6);
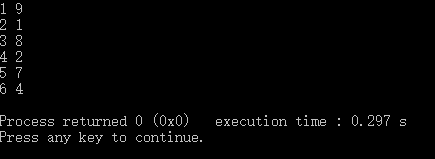
merge(a.begin(),a.end(),b.begin(),b.end(),c.begin(),cmp);
for(int i=0;i<c.size();i++){
printf("%d %d\n",c[i].x,c[i].y);
}
}
运行结果:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/133491.html原文链接:https://javaforall.net


