
大家好,又见面了,我是你们的朋友全栈君。
PG索引类型
- 索引类型
CREATE INDEX 在一个指定表或者物化视图的指定列上创建一个索引,索引主要用来提高数据库的效率(尽管不合理的使用将导致较慢的效率)
- btree
选择性越好(唯一值个数接近记录数)的列,越适合b-tree。
当被索引列存储相关性越接近1或-1时,数据存储越有序,范围查询扫描的HEAP PAGE越少。
支持多列索引,默认最多32列,编译可改。(通过调整pg_config_manual.h可以做到更大,但是还有另一个限制,indextuple不能超过约1/4的数据块(索引页)大小,也就是说复合索引列很多的情况下,可能会触发这个限制)
支持唯一索引。
索引策略 : <,<=,=,>=,>
PostgreSQL B-Tree是一种变种(high-concurrency B-tree management algorithm),算法详情请参考src/backend/access/nbtree/README
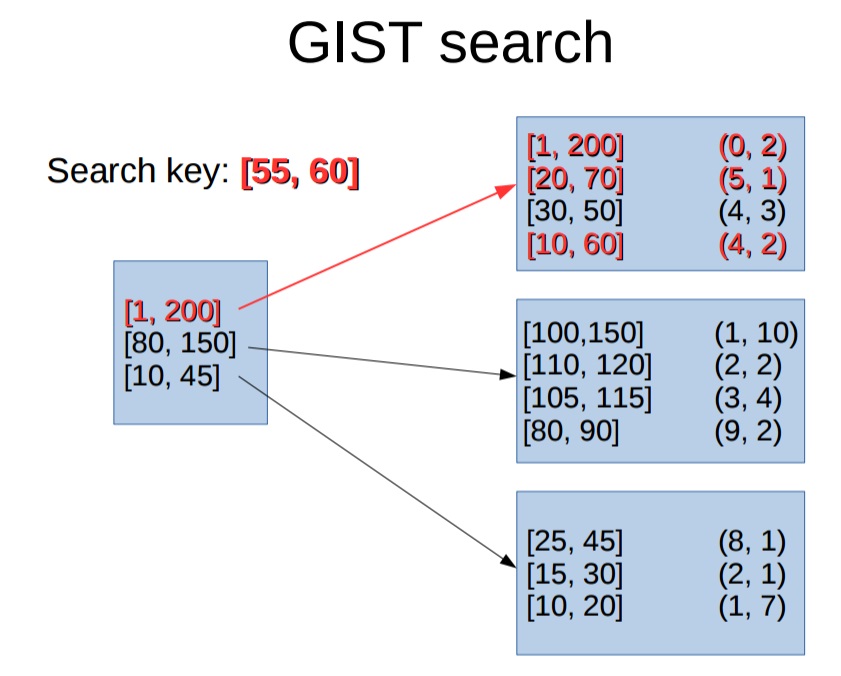
可以使用pageinspect插件,内窥B-Tree的结构。
https://github.com/digoal/blog/blob/master/201605/20160528_01.md
组合索引
虽然b-tree多列索引支持任意列的组合查询,但是最有效的查询还是包含驱动列条件的查询。
对于b-tree的多列索引来说,一个查询要扫描索引的哪些部分呢?
从驱动列开始算,按索引列的顺序算到非驱动列的第一个不相等条件为止(没有任何条件也算)。
(WHERE a = 5 AND b >= 42 AND c < 77),从a=5, b=42开始的所有索引条目,都会被扫描。
其他例子
(WHERE b >= 42 AND c < 77),所有索引条目,都会被扫描。只要不包含驱动列,则扫描所有索引条目。
(WHERE a = 5 AND c < 77),a=5的所有索引条目,都会被扫描。
(WHERE a >= 5 AND b=1 and c < 77),从a=5开始的所有索引条目,都会被扫描。
- hash
只有等值查询,并且被索引的列长度很长,可能超过数据库block的1/3时,建议使用hash索引。 PG 10 hash索引会产生WAL,确保了可靠性,同时支持流复制。PG 10 以前的版本,不建议使用hash index,crash后需要rebuild,不支持流复制。
不支持多列索引。
不支持唯一索引。
索引策略 :=
原理src/backend/access/hash/README
应用场景
hash索引存储的是被索引字段VALUE的哈希值,只支持等值查询。
hash索引特别适用于字段VALUE非常长(不适合b-tree索引,因为b-tree一个PAGE至少要存储3个ENTRY,所以不支持特别长的VALUE)的场景,例如很长的字符串,并且用户只需要等值搜索,建议使用hash index。
PG10之后的版本hash index会写wal日志了,同时支持流复制。
- gist
GIST是PG的一种通用索引接口,适合各种数据类型,特别适合异构的类型,例如几何类型,空间类型,范围类型等。
支持多列索引,默认最多32列,编译可改。
不支持唯一索引。
索引策略 :两维R-tree策略
严格地在…左边,
不扩展到…右边,
重叠,
不延伸到…左边,
严格地在…右边,
相同,
包含,
包含于,
不扩展到…上面,
严格地在…下面,
严格地在…上面,
不扩展到…下面
独有参数 BUFFERING
建立索引时决定是否缓存建立的方法.使用OFF 关闭这个功能,ON 打开这个功 能. 使用AUTO 它初始化时是关闭的,但是当索引的达到effective_cache_size将 会打开.默认使用AUTO.
GiST是一个通用的索引接口,可以使用GiST实现b-tree, r-tree等索引结构。
不同的类型,支持的索引检索也各不一样。例如:
1、几何类型,支持位置搜索(包含、相交、在上下左右等),按距离排序。
2、范围类型,支持位置搜索(包含、相交、在左右等)。
3、IP类型,支持位置搜索(包含、相交、在左右等)。
4、空间类型(PostGIS),支持位置搜索(包含、相交、在上下左右等),按距离排序。
5、标量类型,支持按距离排序。
Generalized Search Tree,或者叫归纳树,用于解决一些b-tree, gin难以解决的数据减少问题,例如,范围是否相交,是否包含,地理位置中的点面相交,或者按点搜索附近的点,当然,它能实现的功能还不仅于此。
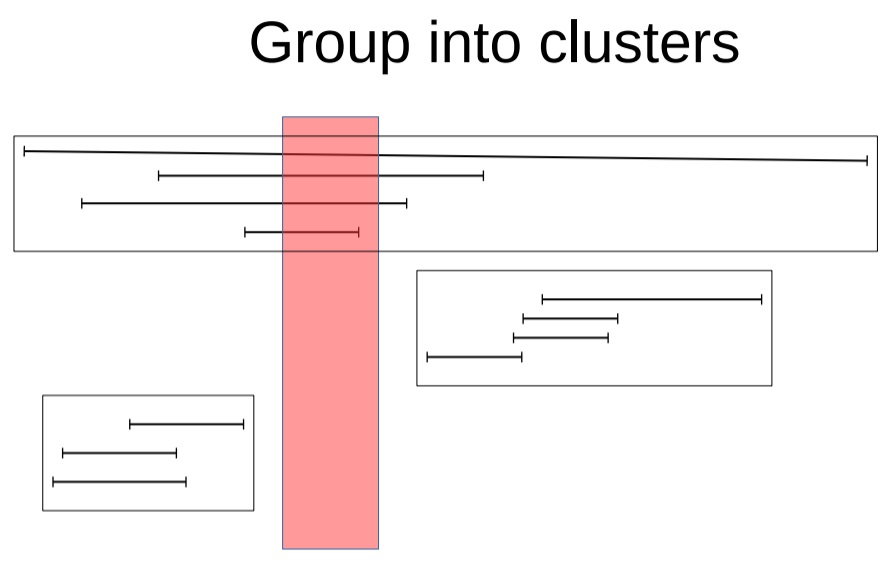

GiST的灵魂是聚集,所以首先是聚集的动作,聚集后,在单个组内包含的KEY+HEAP行号会放到单个INDEX PAGE中。
聚集的范围作为一级结构,存储在GiST的entry 中,便于检索。
既然灵魂是聚集,那么GiST的性能就和他的聚集算法息息相关,PostgreSQL把这个接口留给了用户,用户在自定义数据类型时,如果要自己实现对应的GIST索引,那么就好好考虑这个类型聚集怎么做吧。
PostgreSQL内置的range, geometry等类型的GIST已经帮你做好了,你只需要做新增的类型,比如你新增了一个存储人体结构的类型,存储图片的类型,或者存储X光片的类型,怎么快速检索它们,那就是你要实现的GIST索引聚集部分了。
- spgist
不支持多列索引。
不支持唯一索引。
索引策略 : 点策略
严格在左边,
严格在右边,
相同,
包含,
严格在下面,
严格在上面
Space-Partitioned GIST
可以理解为GiST的扩展,有以下特点
1. nodes无交叉,(GiST是有交叉的,只是做了聚集,但是nodes(不同的index page)包含的内容是有交叉的)。
2. 索引深度是可变的
应用场景
1、几何类型,支持位置搜索(包含、相交、在上下左右等),按距离排序。
2、范围类型,支持位置搜索(包含、相交、在左右等)。
3、IP类型,支持位置搜索(包含、相交、在左右等)。
- gin
与btree相反,选择性越差,采用GIN索引效率越高。
支持多列索引,默认最多32列,编译可改。
不支持唯一索引。
索引策略 : 数组策略
重叠,
包含,
包含于,
相等
独有参数 FASTUPDATE
快速更新技术.它是一个布尔类型参数:ON使能快速更新,OFF关闭这个功能
GIN的意思是通用倒排索引(Generalized Inverted Index)。 GIN被设计用于这样一种情况:被索引项是组合值,而被索引处理的查询需要搜索出现在这些组合值中的元素值。比如,项目可能是文档,查询可以是搜索包含多个特定单词的文档。
更新效率较差,比较适合静态数据。
gin索引,是将列(比如数组,全文检索类型)中的值拿出来,再存储到树形结构中(类似B+TREE,值+行号s),对于高频值,为了减少树的深度,行号s会存储在另外的页中。
由于GIN存储的是元素索引,所以当一条记录被插入或更新时,可能涉及到很多个元素,对GIN索引来说,就会涉及到很多ITEM的变更。
为了提升插入,更新,删除的性能,PostgreSQL支持类似MySQL的索引组织表类似的buffer ,先写入BUFFER,然后再合并到树里去。
而相比MySQL索引组织表更优一些的地方是,查询不会堵塞合并,也不会堵塞写入。因为查询时不需要等待BUFFER中的数据合并到树中,而是直接查询BUFFER(如果BUFFER非常大,可能查询速度会受到一定的影响)。
用户可通过参数来控制BUFFER的大小,GIN会在BUFFER增长到一定程度后自动进行合并。或者等VACUUM来合并。
所以一个完整的GIN索引长这样

使用注意
1. 为了提高更新速度,使用了FASTER UPDATE技术,当BUFFER很大时(可自己设置),查询速度可能会较慢。所以权衡插入和查询,建议设置合理的BUFFER大小。
2. 仅支持bitmap查询,也就是说取到所有的行号之后,排序,然后再去检索,好处显然是可以减少随机的HEAP PAGE扫描,但是坏处是,当涉及的行非常多(比如每行都包含了某个元素)很大时,排序耗费资源较多,耗时较长,从执行到获得第一条的时间较长,如果用户使用了LIMIT,也要等排序结束。
应用场景
1、当需要搜索多值类型内的VALUE时,适合多值类型,例如数组、全文检索、TOKEN。(根据不同的类型,支持相交、包含、大于、在左边、在右边等搜索)
2、当用户的数据比较稀疏时,如果要搜索某个VALUE的值,可以适应btree_gin支持普通btree支持的类型。(支持btree的操作符)
3、当用户需要按任意列进行搜索时,gin支持多列展开单独建立索引域,同时支持内部多域索引的bitmapAnd, bitmapOr合并,快速的返回按任意列搜索请求的数据。
gin多列索引支持任意列的组合查询。并且任意查询条件的查询效率都是一样的。
使用btree_gin插件,可以对任意标量数据类型创建GIN索引。
注意,目前gin还不支持sort,所以如果你有大数据量的ORDER BY limit 小数据输出需求,建议还是使用b-tree。
- BRIN
当数据与堆存储线性相关性很好时,可以采用BRIN索引。
支持多列索引,默认最多32列,编译可改。
对插入性能影响小于Btree索引。
brin多列索引支持任意列的组合查询。并且任意查询条件的查询效率都是一样的。
如果有brin组合查询的必要(比如多个与ctid线性相关的列的范围查询,无所谓线性的方向),任何时候都建议使用BRIN的multi column index,除非想针对不同的列使用不同的pages_per_range(比如有些列10个块的范围和另外一些列100个块的范围覆盖差不多,那么建议它们使用不同的pages_per_range)
BRIN 索引是块级索引,有别于B-TREE等索引,BRIN记录并不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息。因此BRIN索引空间占用特别的小,对数据写入、更新、删除的影响也很小。
BRIN属于LOSSLY索引,当被索引列的值与物理存储相关性很强时,BRIN索引的效果非常的好。
例如时序数据,在时间或序列字段创建BRIN索引,进行等值、范围查询时效果很棒。
- BLOOM
bloom filter是一个有损过滤器,使用有限的比特位存储一些唯一值集合所产生的bits。
通过这些bits可以满足这样的场景需求,给定一个值,判断这个值是否属于这个集合。
由于bloom filter是有损过滤器,并且真的不一定为真,但是假的一定为假。
目前已实现的场景是,支持=查询,但是这个=会包含一些假的值,所以需要recheck。
CREATE EXTENSION bloom;
CREATE INDEX score_idx ON score USING bloom(s1,s2,s3,s4);
SELECT * FROM score WHERE s1 = 86 AND s4 = 70;
对于Bloom索引的大小和精度有一个取舍。选择大的索引会花更长的时间去扫描,但是选择较少的列数以供后续检测。选择小的索引会使扫描变快但是选择的用于检测的行数较多。
使用Bloom索引的优势是与利用过滤器选择性的查询位数紧密相关的。如果选择性太低,例如只有一列用于查询,或者有太少的位数被分配到索引列中,数据库可能会选择回归到扫描整个表。
这个效果对于不同类型的硬盘(例如SSD和机械硬盘)来说差别很大。使用bloom索引的优势在SSD上被增强了,随机访问惩罚在SSD上会降低。
- btree_gist
对gist索引的补充扩展,支持标量类型建立btree_gist索引和排序
CREATE EXTENSION btree_gist;
- btree_gin
对GIN的补充扩展,支持标量数据
CREATE EXTENSION btree_gin;
直接使用原先的gin索引的定义方法即可定义标量数据的GIN索引。
create index idx_tbl_tmp_lpj_gin_c2 on tbl_tmp_lpj using gin(c2);
- rum(第三方索引插件)
https://github.com/postgrespro/rum
RUM 参考了GIN的实现,并改进了GIN在全文检索时的一些弱点,不过建立索引和数据变更的时间比GIN长。
rum检索支持近似度排行,通过相似度分值表示文本和检索条件的相似度。
- zombodb(第三方索引插件)
zombodb是PostgreSQL与ElasticSearch结合的一个索引接口,可以直接读写ES。
https://github.com/zombodb/zombodb
应用场景
与ES结合,实现SQL接口的搜索引擎,实现数据的透明搜索。
- 用户自定义索引
难度较大,暂不考虑。
下面是其他的一些第三方索引
bitmap索引是Greenplum的索引接口,类似GIN倒排,只是bitmap的KEY是列的值,VALUE是BIT(每个BIT对应一行),而不是行号list或tree。
varbitx是阿里云RDS的扩展包,丰富bit类型的函数接口,实际上并不是索引接口,但是在PostgreSQL中使用varbitx可以代替bitmap索引,达到同样的效果。
- 验证性能
- hash索引和b-tree索引在等值检索时的性能差异
|
数据量 |
索引类型 |
平均耗时ms |
|
28W |
btree |
76.5 |
|
28W |
hash |
56.6 |
|
99W |
btree |
51 |
|
99W |
hash |
43.5 |
结论等值检索上hash索引效率高于btree索引,不过hash索引因为不记录wal日志不建议使用。
PG10的hash索引会写wal日志。
- 使用场景
- 全文搜索
CREATE INDEX name ON table USING gist(column);
创建以GiST(通用搜索树)为基础的索引,column可以是tsvector or tsquery 类型。
CREATE INDEX name ON table USING gin(column);
创建以GIN(倒排索引)为基础的索引,column必须是tsvector类型。
GiST索引是有损耗的,这意味着该索引可能会产生错误的匹配,并且有必要检查实际的表行消除这种错误匹配(PostgreSQL需要时自动执行)。
GIN索引并没有损耗标准查询,但它们的性能取决于对数独特的单词数。(然而,GIN索引只存储tsvector值的字(词),而不是它们的权重标签。因此,当使用涉及权重的查询时,需要复查一个表行。)
在选择要使用的索引类型时,GiST或者GIN考虑这些性能上的差异:
- GIN索引查找比GiST快约三倍
- GIN索引建立比GIST需要大约三倍的时间。
- GIN索引更新比GiST索引速度慢,但如果快速更新支持无效,则慢了大约10倍
- GIN索引比GiST索引大两到三倍
一般来说,GIN索引对静态数据是最好的,因为查找速度很快。对于动态数据, GiST索引更新比较快。具体而言,GiST索引非常适合动态数据,并且如果独特的字(词)在100,000以下,则比较快,而GIN索引将处理100,000+词汇,但是更新比较慢。
- 模糊查询
模糊查询,是一个需求量很大,同时也是一个对数据库来说非常难缠的需求。
对于前模糊(like ‘%xxx’),可以使用倒排B-TREE索引解决,对于后模糊(like ‘xxx%’),可以使用B-TREE索引解决。
B-TREE索引通常支持的查询包括 > , < , = , <= , >= 以及排序。 目前大多数数据库都支持B-TREE索引方法。
但是对于前后模糊(like ‘%xxxx%’),对于以及前后模糊的正则表达式(~ ‘.ab?cd[e-f]{1,10}-0.‘),则很多数据库无从下手,无法优化,只能全表扫描,对每条记录进行单独的处理。
PostgreSQL数据库的开放性使得这一切成为了可能,在数据库中进行前后模糊,正则表达查询的索引检索成为可能。
原因是PostgreSQL开放的索引接口,数据类型。(比如支持GIN, GIST, RUM, 自定义索引方法,你可以认为这是PG的独门绝技之一,目前还没有其他数据库支持这一特性 2016-12-31)。
前后模糊:
gin, gist, rum
正则表达:
gin, gist
- 执行计划改变插件pg_hint_plan
https://github.com/ossc-db/pg_hint_plan/releases
安装
# export PATH= /home/postgres/pgsql/bin:$PATH
# gmake clean
# gmake
# gmake install
vi $PGDATA/postgresql.conf
shared_preload_libraries = 'pg_hint_plan'
pg_hint_plan.enable_hint = on
pg_hint_plan.debug_print = on
pg_hint_plan.message_level = log
postgres=# create extension pg_hint_plan;
- 表达式索引
表达式索引也是PostgreSQL特有的特性,例如用户的数据需要转换后查询,例如某些设备上传的地理坐标的坐标系不符合国标,需要转换为国内的空间坐标来查询。
那么可以针对这类字段,创建表达式索引,将转换过程放到表达式中,查询时也使用表达式进行查询。
create index idx_t_express_1 on t_express using gist ( ( ST_Transform(pos, 26986) ) ); select * from t_express order by ST_Transform(pos, 26986) <-> ST_Transform(ST_GeomFromText('POINT(108.50000000001 22.8)', 4326), 26986) limit 10;
- 函数索引
必须是IMMUTABLE的函数,STABLE和VOLATILE无法创建索引
- 部分索引
应对常用组合筛选条件或是只对热数据加索引
create index idx_test_id on test(id) where active; select * from test where active and id=?; --可以使用部分索引
- 多列索引
多列索引每个列的operator class必须和实际查询匹配,在创建索引时可以指定。
b-tree, gin都支持任意组合查询。
但是b-tree推荐使用包含驱动列的查询条件,如果查询条件未包含驱动列,则需要扫描整个复合索引。
而gin则通吃,可以输入任意组合列作为查询条件,并且效率一致。
例如
index on (a,b,c)
b-tree 对于包含驱动列a查询条件的SQL,效率可能比较好,不包括a查询条件的SQL,即使走索引,也要扫描整个索引的所有条目。
而gin 则无论任何查询条件,效果都一样。
仅仅当多列组合查询时,gin效率可能比不上b-tree的带驱动列的查询(因为b-tree索引不需要bitmapAnd,而gin需要内部bitmapAnd)。
- PG的数据扫描方法
PostgreSQL中数据的扫描方法很多,常见的有:
1、全表顺序扫描(seqscan)
2、索引+回表扫描(index scan)
3、索引扫描(index only scan)
4、bitmap扫描(bitmap index + block sorted heap scan)
那么对于同一张表,返回同样的记录数,不同的索引,效率有什么差别呢?
回答是和数据的存储线性相关性有关。(PostgreSQL的bitmap scan就是用来解这个问题的)
除了考虑数据存储的离散性,索引页本身的组织也是离散的
- 读取数据页面内容的插件pageinspect
PG自带,可用于读取索引页信息,用于调试,仅超级用户使用。
详见官方文档。
- 参考文档
https://yq.aliyun.com/articles/68244#1
https://github.com/digoal/blog/blob/master/201809/20180903_03.md
https://github.com/digoal/blog/blob/master/201602/20160203_01.md?spm=a2c4e.11153940.blogcont68244.70.29035625nnzqPA&file=20160203_01.md
https://github.com/ossc-db/pg_hint_plan/releases
https://github.com/digoal/blog/blob/master/201804/20180402_01.md
https://github.com/digoal/blog/blob/master/201706/20170627_01.md
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/139707.html原文链接:https://javaforall.net


