
大家好,又见面了,我是你们的朋友全栈君。
推导Lasso回归
一、推导过程
Lasso方法是在普通线性模型中增加 L 1 L_1 L1惩罚项,有助于降低过拟合风险,更容易获得稀疏解,求得的 θ \theta θ会有更少的非零分量。与岭回归的不同在于,此约束条件使用了绝对值的一阶惩罚函数代替了平方和的二阶函数。
Lasso回归原式: arg min θ ∣ ∣ A θ − y ∣ ∣ 2 2 + λ ∣ ∣ θ ∣ ∣ 1 \mathop{\arg\min}\limits_{\theta}||A\theta-y||_2^2+\lambda||\theta||_1 θargmin∣∣Aθ−y∣∣22+λ∣∣θ∣∣1
公式转换为: arg min θ 1 2 ∣ ∣ A θ − y ∣ ∣ 2 2 + 1 2 λ ∣ ∣ W θ ∣ ∣ 2 2 \mathop{\arg\min}\limits_{\theta}\frac{1}{2}||A\theta-y||_2^2+\frac{1}{2}\lambda||W\theta||_2^2 θargmin21∣∣Aθ−y∣∣22+21λ∣∣Wθ∣∣22
= arg min θ 1 2 ( A θ − y ) T ( A θ − y ) + 1 2 λ ( W θ ) T W θ \mathop{\arg\min}\limits_{\theta}\frac{1}{2}(A\theta-y)^T(A\theta-y)+\frac{1}{2}\lambda(W\theta)^TW\theta θargmin21(Aθ−y)T(Aθ−y)+21λ(Wθ)TWθ
上式对求导,
= 1 2 ( 2 A T A θ − 2 A T y ) + λ W T W θ =\frac{1}{2}(2A^TA\theta-2A^Ty)+\lambda W^TW\theta =21(2ATAθ−2ATy)+λWTWθ
= A T A θ − A T y + λ W T W θ =A^TA\theta-A^Ty+\lambda W^TW\theta =ATAθ−ATy+λWTWθ
令求导结果等于0,
θ = ( A T A + λ W T W ) − 1 A T y , 其 中 w i = 1 ∣ e i ∣ + ϵ , ϵ 是 一 个 接 近 于 0 的 数 ( 例 1 e − 5 ) \theta=(A^TA+\lambda W^TW)^{-1}A^Ty, 其中w_i=\frac{1}{\sqrt{|e_i|}+\epsilon},\epsilon 是一个接近于0的数(例1e-5) θ=(ATA+λWTW)−1ATy,其中wi=∣ei∣+ϵ1,ϵ是一个接近于0的数(例1e−5)
二、用python编写求解函数
def lasso(X, W, lr, Y):
A = np.mat(X.copy())
Y = np.mat(Y).reshape(-1,1)
for i in range(10):
seta = (A.T * A + lr* W.T *W).I*(A.T*Y)
W = np.diag(1/(np.sqrt(np.abs(seta)) + 1e-5))
return seta
三、Lasso求解稀疏表示做人脸识别
数据集的大小为(867,897),数据一共有867个样本,每个样本有896个属性,数据最后一列为标签,表示此样本属于某个人的,数据集一共有38个人的人脸数据。测试样本为,每人抽取两个人脸数据作为测试样本,即数据集表示为[A1, A2, …, A75, A76],y从总的数据集中随机抽选一个。
用lasso回归函数求解数据集的稀疏表示:
理论公式如下:
θ = ( A T A + λ W T W ) − 1 A T y , \theta=(A^TA+\lambda W^TW)^{-1}A^Ty, θ=(ATA+λWTW)−1ATy,
其 中 w i = 1 ∣ e i ∣ + ϵ , ϵ 是 一 个 接 近 于 0 的 数 ( 例 1 e − 5 ) 其中w_i=\frac{1}{\sqrt{|e_i|}+\epsilon},\epsilon 是一个接近于0的数(例1e-5) 其中wi=∣ei∣+ϵ1,ϵ是一个接近于0的数(例1e−5)
其中W为系数矩阵。
代码展示:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
csv_data = pd.read_csv('test_YB_32_28.csv', header = None) #读取训练数据集,数据类型dataframe
csv_data = csv_data.values #将数据转换为矩阵形式
print(csv_data.shape)#输出数据大小
#选取训练数据编号
x = [] #生成列表,每个人选择前两张照片作为数据集
t = -1
for i in range(76):
if i % 2 == 0 and i != 0:
t +=22
else:
t += 1
x.append(t)
#print(x)
y = np.random.randint(0,867) #随机挑选一张照片作为目标数据y
#print(y)
#提取训练数据X,y
train_data = csv_data[x, :896]/255 #提取训练数据
train_target = csv_data[y, :896]/255 #提取目标数据
train_label = csv_data[y, -1]#提取y的标签
#np.savetxt('data.csv', train_data, delimiter = ',')
#np.savetxt('target.csv', train_target, delimiter = ',')
#对系数矩阵进行处理
train_data = train_data.T #对数据进行转置
#print(train_data.shape)
#print(train_target.shape)
W = np.eye(76) #生成对角矩阵
#print(W.shape)
#print(W)
#lasso求解函数
def lasso(X, W, lr, Y):
A = np.mat(X.copy())
Y = np.mat(Y).reshape(-1,1)
for i in range(10):
seta = (A.T * A + lr* W.T *W).I*(A.T*Y) #lasso系数表示
W = np.diag(1/(np.sqrt(np.abs(seta)) + 1e-5)) #权重对角矩阵更新
return seta
#调用lasso函数,代入数据
seta = lasso(train_data, W, 1e-8, train_target)
#print(seta) #打印出seta系数表示
i = range(1,77, 1)
plt.plot(i, seta)
plt.show() #输出seta稀疏表示的图像
#将一维矩阵转为数组,求当前y对应人的稀疏表示稀疏
seta = list(seta)
print('当前y对应人的系数表示:')
print(seta[train_label*2-2])
print(seta[train_label*2-1])
# print(max(seta))
# print(seta[seta.index(max(seta))+1])
print('预测值:', math.ceil((seta.index(max(seta)) +1)/2)) #系数最大为预测值
print('真实值:', train_label) #真实值
运行结果
第一种情况:
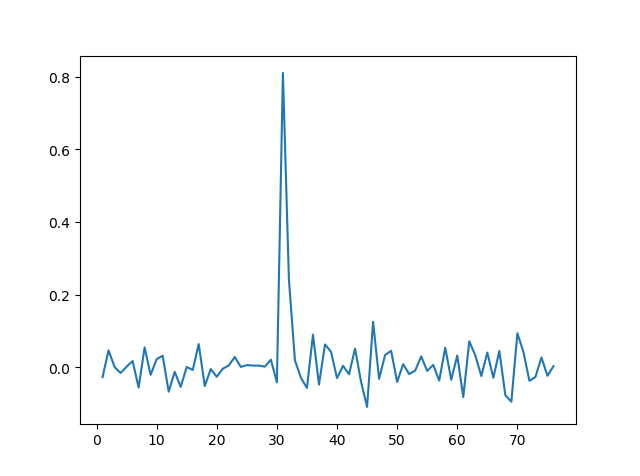

图一 seta数据表示图
输出结果:
当前y对应人的系数表示:
[[0.81046264]]
[[0.24147223]]
预测值: 16(稀疏表示系数最大处)
真实值: 16
Seta稀疏表示具有稀疏性,预测结果满足预期要求。原因是,测试的样本y能够由当前的测试样本很好的表示出来,对于选取的测试集样本,能够获得具有代表性的稀疏表示。
另一种情况:
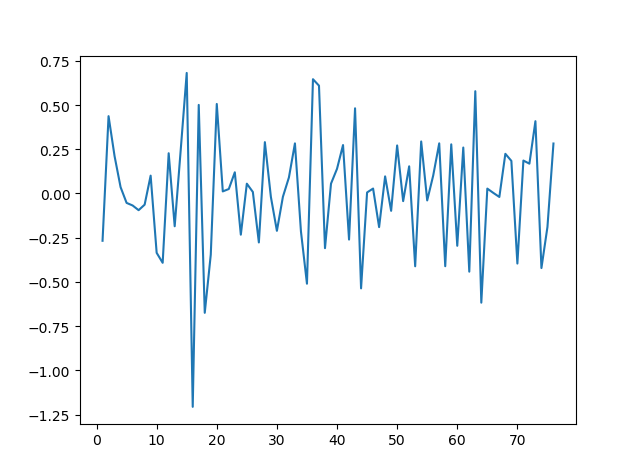
图二 seta数据表示图
输出结果:
当前y对应人的系数表示:
[[0.6094047]]
[[-0.30913317]]
预测值: 8(稀疏表示系数最大处)
真实值: 19
Seta稀疏表示表现出的稀疏性不强,预测结果不满足预期要求。产生的原因可能是某个个体的样本数量太少,测试集样本太过于特殊,还不足以能用稀疏表示来代表这个个体。解决结果是增加每个个体的训练样本,能让训练出来的稀疏表示更加具有代表性。
四、调整不同的超参lambda,对seta的影响
选择不同的lambda作为惩罚项系数,在本代码中,选择lambda = [10000, 10, 0.01, 0.00001]这四种情况进行比较。此次实验每人选取两个样本共78张图片作为测试集y,剩下的691个样本作为数据集。
代码展示
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
csv_data = pd.read_csv('test_YB_32_28.csv', header = None) #读取训练数据集,数据类型dataframe
csv_data = csv_data.values #将数据转换为矩阵形式
print(csv_data.shape)#输出数据大小
#选取训练数据编号
y = [] #生成列表,每个人选择前两张照片作为测试数据集
t = -1
X = list(range(0, 867, 1)) #训练数据
3#print(X)
for i in range(76):
if i % 2 == 0 and i != 0:
t +=22
else:
t += 1
X.remove(t) #剔除掉用于测试的数据y
y.append(t) #生成用于测试的数据集Y
#print(x)
#y = np.random.randint(0, 867) #随机挑选一张照片作为目标数据y
#print(y)
#提取训练数据X,y
train_data = csv_data[X, :896]/255 #提取训练数据
train_target = csv_data[y, :896]/255 #提取目标数据
#train_label = csv_data[x, -1]#提取y的标签
#np.savetxt('data.csv', train_data, delimiter = ',')
#np.savetxt('target.csv', train_target, delimiter = ',')
#对系数矩阵进行处理
train_data = train_data.T #对数据进行转置
#print(train_data.shape)
#print(train_target.shape)
#print(W.shape)
#print(W)
lambda = [10000, 10, 1e-2, 1e-5]
s_seta = []
#lasso求解函数
def lasso(X, W, lb, Y):
A = np.mat(X.copy())
Y = np.mat(Y).reshape(-1,1)
for i in range(10):
seta = (A.T * A + lb* W.T *W).I*(A.T*Y) #lasso系数表示
W = 1/(np.sqrt(np.abs(seta)) + 1e-5)#权重对角矩阵更新
W = np.diag(W/sum(W))
return seta
#调用lasso函数,代入数据
for i in range(4):
W = np.eye(791) #生成对角矩阵
lb = lambd[i]
seta = lasso(train_data, W, lb, train_target)
s_seta.append(seta)
#print(seta) #打印出seta系数表示
i = range(1,101, 1)
plt.plot(i, s_seta[0][:100], label = '1e4') #选取前100个数据进行打印
plt.plot(i, s_seta[1][:100], label = '10')
plt.plot(i, s_seta[2][:100], label = '1e-2')
plt.plot(i, s_seta[3][:100], label = '1e-5')
plt.xlabel('number')
plt.ylabel('weight')
plt.legend()
plt.show() #输出seta稀疏表示的图像
输出结果:
本测试结果选取第一张图片的输出结果,Lambda值分别选取10000, 10, 0.01, 0.00001,选取seta稀疏表示的前100个系数,实验运行结果如下图所示,
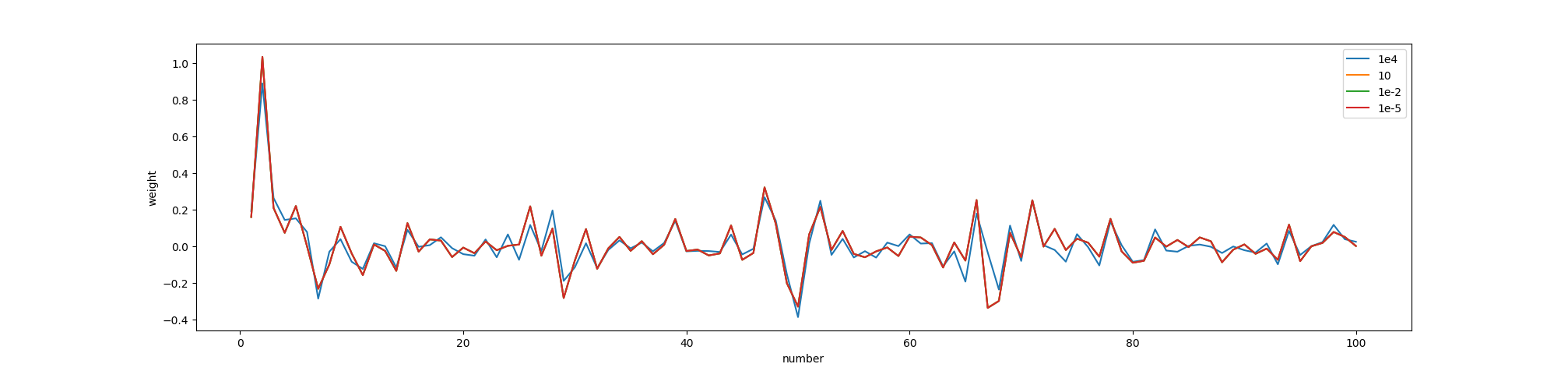
图三 不同lambda下的稀疏表示seta
结论:
Lasso的主要思想是构造一个一阶惩罚函数获得一个精炼的模型, 通过最终确定一些变量的系数为0进行特征筛选。Lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,会压缩一些回归系数,从而最终获得一个变量较少,较为精炼的模型。当λ较大时,获得的稀疏表示就越稀疏。在上述实验过程中,选择一个较大的lambda值即可获得一个理想的seta结果输出。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/139730.html原文链接:https://javaforall.net


