
大家好,又见面了,我是你们的朋友全栈君。
前言
在大型的企业应用或企业级的数据库应用中,要处理的数据量通常达到TB级,对于这样的大型表执行全表扫描或者DML操作时,效率是非常低的。
为了提高数据库在大数据量读写操作和查询时的效率,达梦数据库提供了对表和索引进行分区的技术,把表和索引等数据库对象中的数据分割成小的单位,分别存放在一个个单独的段中,用户对表的访问转化为对较小段的访问,以改善大型应用系统的性能。
达梦数据库分区表主要包括范围分区、哈希分区和列表分区三种方式, 企业可以使用合适的分区方法,如日期(范围)、区域(列表),对大量数据进行分区。由于达梦数据库划分的分区是相互独立且可以存储于不同的存储介质上的,完全可满足企业高可用性、 均衡IO、降低维护成本、提高查询性能的要求。今天我们主要讨论水平分区
一 创建分区表
1.创建范围分区表
create table r_t1 (pid int primary key ,id int)
partition by range (pid)
(partition p1 values less than (101),
partition p2 values less than (201));
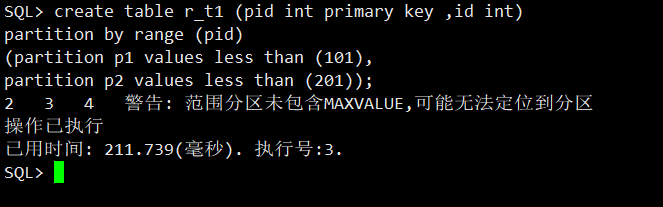

将1-200的值录入到t_r1中。
begin
for i in 1..200 loop
insert into r_t1 values (i,i+1);
end loop;
end;
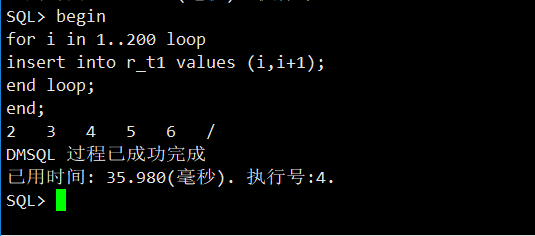
查看表r_t1的类型,显示为分区表。
select table_name,PARTITIONED from dba_tables where table_name='R_T1';
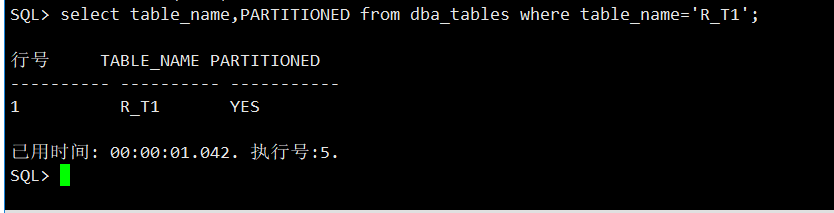
查看分区表的分区,显示为二个分区p1和p2。
select table_name,partition_name from dba_tab_partitions where table_name='R_T1';
查询分区表中的记录数。
SQL> select count(*) from r_t1 partition (p1);
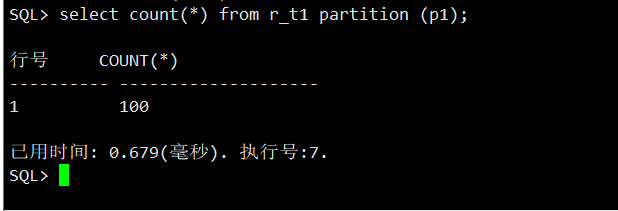
这样一个范围分区就建立好了。
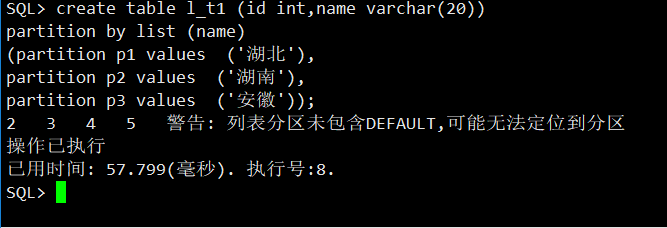
2.创建列表分区
create table l_t1 (id int,name varchar(20))
partition by list (name)
(partition p1 values ('湖北'),
partition p2 values ('湖南'),
partition p3 values ('安徽'));
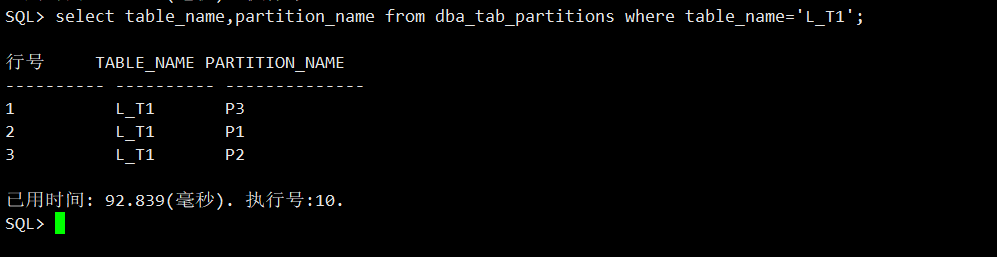
查看分区表的分区,显示为三个分区p1,p2,p3
SQL>select table_name,partition_name from dba_tab_partitions where table_name='L_T1';
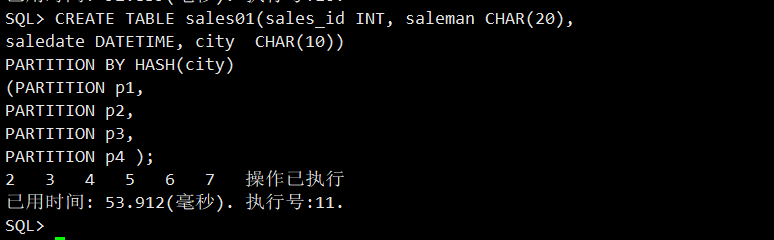
3.创建哈希分区
SQL>CREATE TABLE sales01(sales_id INT, saleman CHAR(20),
saledate DATETIME, city CHAR(10))
PARTITION BY HASH(city)
(PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4 );
如果不需指定分区表名,可以通过指定哈希分区个数来建立哈希分区表。
SQL>CREATE TABLE sales02(sales_id int, saleman char(20),
saledate DATETIME, city CHAR(10)) PARTITION BYHASH(city)
PARTITIONS 4;

PARTITIONS后的数字表示哈希分区的分区数,STORE IN 子句中指定了哈希分区依 次使用的表空间。使用这种方式建立的哈希分区表分区名是匿名的,DM7 统一使用 DMHASHPART+分区号(从 0 开始)作为分区名。例如,需要查询 sales02第一个分区的数据,可执行以下语句:
SQL>SELECT* FROM sales02 PARTITION (DMHASHPART1);

二 增加分区
SQL> alter table r_t1 add partition p3 values less than(301);

查看分区数,可以看到新增了一个分区p3

三 删除分区
SQL> alter table r_t1 drop partition p3;
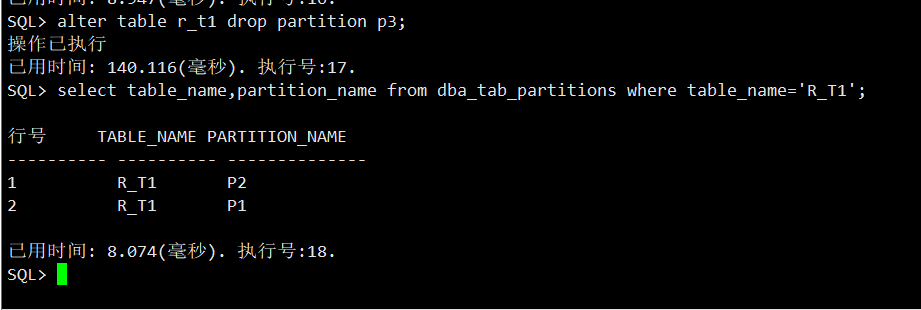
可以看到,新增的分区P3被删除了。
四 合并分区
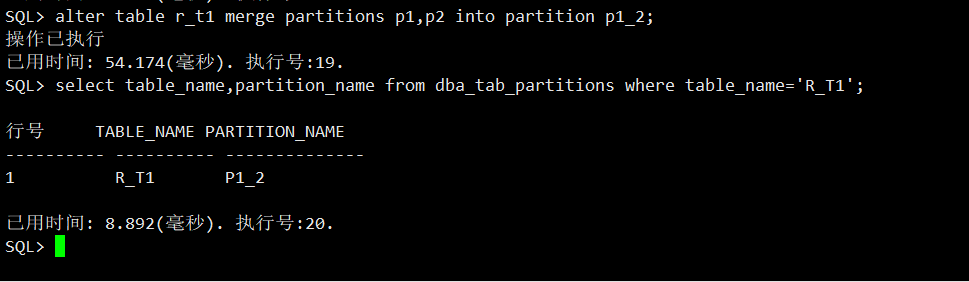
Sql> alter table r_t1 merge partitions p1,p2 into partition p1_2;
五 拆分分区
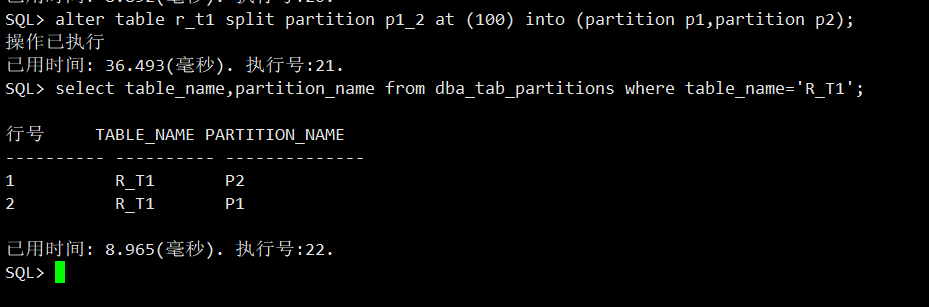
SQL> alter table r_t1 split partition p1_2 at (100) into (partition p1,partition p2);
六 水平分区表的限制
- 分区列类型必须是数值型、字符型或日期型,不支持BLOB、CLOB、IMAGE、TEXT、 LONGVARCHAR、BIT、BINARY、VARBINARY、LONGVARBINARY、时间间隔类型和用户自定义类型为分区列。
- 范围分区和哈希分区的分区键可以多个,最多不超过16列;LIST分区的分区键 必须唯一。
- 水平分区表指定主键和唯一约束时,分区键必须都包含在主键和唯一约束中。
- 水平分区表不支持临时表。
- 不能在水平分区表上建立自引用约束。
- 普通环境中,水平分区表的各级分区数的总和上限是 65535;MPP 环境下,水平 分区表的各级分区总数上限取决于INI参数MAX_EP_SITES,上限为2 ^( 16 – log2MAX_EP_SITES)。比如:当MAX_EP_SITES为默认值64时,分区总数上 限为1024。
- 不允许对分区子表执行任何DDL操作。
- 哈希分区支持重命名、删除约束、设置触发器是否启用的修改操作。
- 范围分区支持分区合并、拆分、增加、删除、交换、重命名、删除约束、设置触发 器是否生效操作。
- LIST分区支持分区增加、删除、交换、重命名、删除约束、设置触发器是否生效操作。
- LIST分区范围值不能为NULL。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/140892.html原文链接:https://javaforall.net


