
大家好,又见面了,我是你们的朋友全栈君。
合理的缓存应用可以极大地提高系统性能,最简单的是在应用层面做缓存(越高层面做缓存,效果往往越好),直接将数据缓存到服务器中,以全局map方式存储。在使用的时候直接从缓存的map中取,而不用连接数据库,从而提升性能。这种方式简单易行,但是map常驻服务器内存,并且在数据变更(增删改)的时候要手动更新map。
还有一种方式比较通用,就是使用Hibernate二级缓存(SessionFactory级别的全局缓存,进程或集群级别),是一种通用缓存(一级缓存就不说了,Session级别缓存,hibernate自己管理),hibernate二级缓存多应用在多读少写的实体对象中,比如组织机构和系统字典。本文使用hibernate注解方式使用二级缓存,做一个说明(使用Ehcache)。
1、添加ehcache.xml配置文件
<ehcache>
<!-- maxElementsInMemory="10000" 缓存中最大允许创建的对象数 -->
<!-- eternal="false" 缓存中对象是否为永久的,如果是,超时设置将被忽略,对象从不过期 -->
<!-- timeToIdleSeconds="120" 缓存数据钝化时间(设置对象在它过期之前的空闲时间) -->
<!-- timeToLiveSeconds="120" 缓存数据的生存时间(设置对象在它过期之前的生存时间) -->
<!-- overflowToDisk="true" 内存不足时,是否启用磁盘缓存 -->
<diskStore path="c:\\ehcache\"/>
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
</ehcache> 2、hibernate配置文件中,配置Ehcache相关属性
<!-- 使用二级缓存:false -->
hibernate.cache.use_second_level_cache=true
<!-- 启动查询缓存:false -->
hibernate.cache.use_query_cache=true
<!-- 二级缓存插件:org.hibernate.cache.EhCacheProvider -->
hibernate.cache.provider_class=org.hibernate.cache.EhCacheProvider
<!-- 是否收集有助于性能调节的统计数据:true -->
hibernate.generate_statistics=true
调试的时候,可以设置log4j的log4j.logger.org.hibernate.cache=debug(记录二级缓存的活动),实际发布的时候,注释掉,以免影响性能。
3、pom文件中引入相应jar包(Maven项目,如果还在手动添加jar包的,可以尝试使用maven)
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-ehcache</artifactId>
<version>3.6.9.Final</version>
</dependency>这样就引入了hibernate-ehcache-3.6.9.jar及其依赖包ehcache-core-2.4.3.jar
4、注解方式配置实体
配置了二级缓存后,并不是对所有的实体使用,而是需要指定哪些实体需要用到。如果不配置查询缓存(查询缓存会在下面讲到),则只会在根据id查询的操作中,缓存对象。
在实体上配置@Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE) 并指定缓存并发策略。ehcache的四种缓存并发策略如下:
|
read-write (读写型) |
提供Read Committed事务隔离级别 在非集群的环境中适用 适用经常被读,很少修改的数据 可以防止脏读 更新缓存的时候会锁定缓存中的数据 |
|
nonstrict-read-write (非严格读写型) |
适用极少被修改,偶尔允许脏读的数据(两个事务同时修改数据的情况很少见) 不保证缓存和数据库中数据的一致性 为缓存数据设置很短的过期时间,从而尽量避免脏读 不锁定缓存中的数据 |
|
read-only (只读型) |
适用从来不会被修改的数据(如参考数据) 在此模式下,如果对数据进行更新操作,会有异常 事务隔离级别低,并发性能高 在集群环境中也能完美运作 |
@Entity
@Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
@Table(name = "base_dict")
@JsonIgnoreProperties(value = { "hibernateLazyInitializer", "handler", "fieldHandler", "parentDict" })
public class Dict implements Serializable {
/**
*
*/
private static final long serialVersionUID = 5569761987303812150L;
@Id
@Column(name = "id", length = 36)
@GeneratedValue(generator = "uuid")
@GenericGenerator(name = "uuid", strategy = "org.hibernate.id.UUIDGenerator")
@JsonProperty("id")
private String id;
/** 字典名称 */
@ForeignShow
@Column(name = "name", length = 200)
private String name;5、查询缓存的使用
Query query = session.createQuery(hql);
query.setCacheable(true); //启用查询缓存
query.setCacheRegion(“queryCacheRegion”); //设置查询缓存区域(数据过期策略)
query.list();
Query Cache只是在特定的条件下才会发挥作用,而且要求相当严格:
(1) 完全相同的HQL重复执行。(注意,只有hql)
(2) 重复执行期间,Query Cache对应的数据表不能有数据变动(比如添、删、改操作)
绝大多数的查询并不能从查询缓存中受益,所以Hibernate默认是不进行查询缓存的。
查询缓存适用于以下场合:
(1)在应用程序运行时经常使用的查询语句(参数相同)
(2)很少对与查询语句检索到的数据进行插入、删除或更新操作
6、不使用缓存、使用hibernate二级缓存性能对比
在人员信息列表,性别、政治面貌、职称、职位使用字典对象存储,使用缓存后,第一次将相应字典缓存,之后在交互将不会重新查询数据库,从而提升系统性能。见下图实验结果(单位ms)

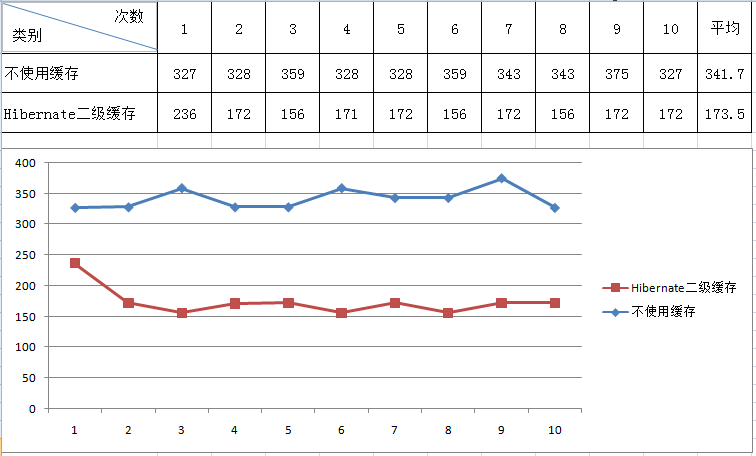
从图中可以看到,使用hibernate二级缓存后性能明显提升一倍。(第一次未使用缓存,所以第一次用时明显高)
7、应用缓存、hibernate二级缓存性能对比
为了验证“在应用层面越高的地方做缓存效果越好”这句话,我们来测试下两种缓存性能之间差别。
测试场景:初始化字典下拉框,下拉框有24个值。结果如下(单位ms)
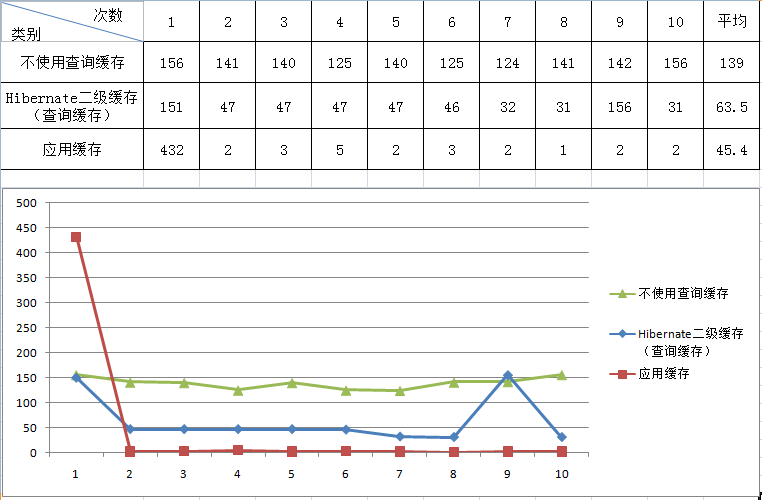
实验结果很明显,应用缓存的效果明显好于前两者,但是应用缓存在第一次的时候耗时较长,因为要做初始化操作。在更新数据时,要更新缓存,也会存在一定耗时,所以看到应用缓存的第一个点很高。另外一个时间点也比较特殊,就是hibernate查询缓存中倒数第二个点,这是因为缓存超时移除,所以重新从数据库中查询(从该值接近不使用查询缓存可看出)。
要看是否连接数据库查询,只需看控制台是否打印出sql语句。
下篇文章将会说下Hibernate一级缓存与懒加载,以上内容不正之处,请指正。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/142561.html原文链接:https://javaforall.net


