
大家好,又见面了,我是你们的朋友全栈君。
自动编码器(Auto-Encoder,AE)
自动编码器(Auto-Encoder,AE)自编码器(autoencoder)是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器内部有一个隐藏层 h,可以产生编码(code)表示输入。该网络可以看作由两部分组成:一个由函数 h = f(x) 表示的编码器和一个生成重构的解码器 r = g(h)。我们不应该将自编码器设计成输入到输出完全相等。这通常需要向自编码器强加一些约束,使它只能近似地复制,并只能复制与训练数据相似的输入。
自动编码机由三层网络组成,其中输入层神经元数量与输出层神经元数量相等,中间层神经元数量少于输入层和输出层。搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息(自编码器是有损的)。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化。

自动编码机(Auto-encoder)是一个自监督的算法,并不是一个无监督算法,它不需要对训练样本进行标记,其标签产生自输入数据。因此自编码器很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。自动编码器是数据相关的,只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
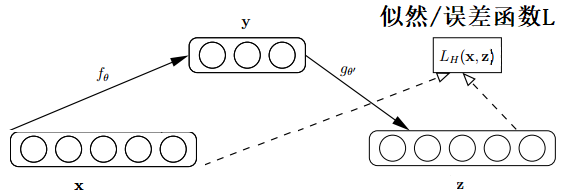
自动编码器运算过程:原始input(设为x)经过加权(W、b)、映射(Sigmoid)之后得到y,再对y反向加权映射回来成为z。通过反复迭代训练两组(W、b),目的就是使输出信号与输入信号尽量相似。训练结束之后自动编码器可以由两部分组成:
1.输入层和中间层,可以用这个网络来对信号进行压缩
2.中间层和输出层,我们可以将压缩的信号进行还原
降噪自动编码器(Denoising Auto Encoder,DAE)
降噪自动编码器就是在自动编码器的基础之上,为了防止过拟合问题而对输入层的输入数据加入噪音,使学习得到的编码器具有鲁棒性而改进的,是Bengio在08年论文:Extracting and composing robust features with denoising autoencoders提出的。
论文中关于降噪自动编码器的示意图如下,类似于dropout,其中x是原始的输入数据,降噪自动编码器以一定概率(通常使用二项分布)把输入层节点的值置为0,从而得到含有噪音的模型输入xˆ。
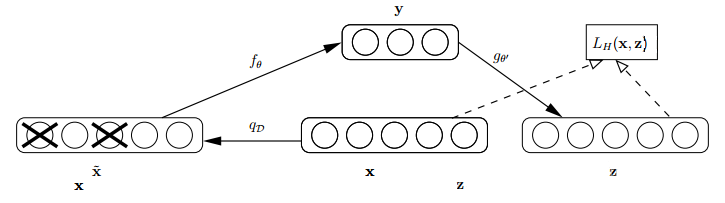
这个破损的数据是很有用的,原因有二:
1.通过与非破损数据训练的对比,破损数据训练出来的Weight噪声比较小。降噪因此得名。原因不难理解,因为擦除的时候不小心把输入噪声给×掉了。
2.破损数据一定程度上减轻了训练数据与测试数据的代沟。由于数据的部分被×掉了,因而这破损数据一定程度上比较接近测试数据。训练、测试肯定有同有异,当然我们要求同舍异。
堆叠降噪自动编码器(Stacked Denoising Auto Encoder,SDAE)
SDAE的思想就是将多个DAE堆叠在一起形成一个深度的架构。只有在训练的时候才会对输入进行腐蚀(加噪),训练完成就不需要在进行腐蚀。结构如下图所示:
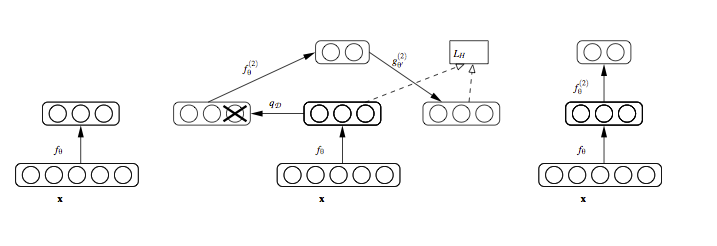
逐层贪婪训练:每层自编码层都单独进行非监督训练,以最小化输入(输入为前一层的隐层输出)与重构结果之间的误差为训练目标。前K层训练好了,就可以训练K+1层,因为已经前向传播求出K层的输出,再用K层的输出当作K+1的输入训练K+1层。
一旦SDAE训练完成, 其高层的特征就可以用做传统的监督算法的输入。当然,也可以在最顶层添加一层logistic regression layer(softmax层),然后使用带label的数据来进一步对网络进行微调(fine-tuning),即用样本进行有监督训练。
-
预测阶段:根据状态转移方程,每一个粒子得到一个预测粒子;
-
校正阶段:对预测粒子进行评价,越接近于真实状态的粒子,其权重越大;
-
重采样:根据粒子权重对粒子进行筛选,筛选过程中,既要大量保留权重大的粒子,又要有一小部分权重小的粒子;
-
滤波:将重采样后的粒子带入状态转移方程得到新的预测粒子,即步骤2。
学习更多编程知识,请关注我的公众号:

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/142807.html原文链接:https://javaforall.net


