
大家好,又见面了,我是你们的朋友全栈君。一.java NIO和堵塞I/O的区别
1.阻塞I/O通信模型:
阻塞I/O在调用InputStream.read()方法时是阻塞的,它会一直等到数据到来时才会返回
2.java NIO原理及通信模型
Java NIO是在jdk1.4开始使用的,是一种非阻塞式的I/O
java NIO的工作原理:
(1)Java NIO的服务端由一个专门的线程来处理所有的I/O事件,并负责分发
(2)线程通讯:线程之间通过wait,notify等方式通讯。保证每次上下文切换都是有意义的。减少无谓的线程切换。
二.Okio概述
1.概述:
Okio补充了io包和nio包的内容,使得数据访问和处理更加便捷,主要功能封装在ByteString和Buffer这两个类中;
Okio使用起来是很简单的,减少了很多io操作的基本代码,并且对内存和cpu使用做了优化
2.ByteString
ByteString(字节串)代表一个immutable字节序列。对于字符数据来说,String是非常基础的,但在二进制数据的处理中,
则没有与之对应的存在。ByteString应运而生。它为我们提供了对串操作所需要的各种 API,例如子串、判等、查找等,也
能把二进制数据编解码为十六进制(hex),base64和UTF-8格式。
3.Source和Sink
Source和Sink,它们和InputStream与OutputStream类似,Source相对应于InpuStream,Sink相对应于OutputStream
但它们还有一些新特性:
a.超时机制,所有的流都有超时机制;
b.API非常简洁,易于实现;
c.Source和Sink的API非常简洁,为了应对更复杂的需求,Okio还提供了BufferedSource和BufferedSink
接口,便于使用(按照任意类型进行读写,BufferedSource 还能进行查找和判等);
d.不再区分字节流和字符流,它们都是数据,可以按照任意类型去读写;
e.便于测试,Buffer 同时实现了 BufferedSource 和 BufferedSink 接口,便于测试;
4.Buffer-(Read和Write数据缓冲区)
Buffer实现了BufferSource接口和BufferSink接口,它集BufferedSource和BufferedSink的功能于一身,
为我们提供了访问数据缓冲区所需要的一切API
Buffer是一个可变的字节序列,包含一个双端链表Segment。我们使用时只管从它的头部读取数据,往它的尾部写入数据就行了,
而无需考虑容量、大小、位置等其他因素。
三.Okio使用
1.Okio的使用
(0)简单的步骤:
a.构建缓冲池,缓冲源对象
b.读写操作
c.关闭缓冲池
(1)ButteredSink
<span style="font-size:14px;"> File file=new File("xx.txt");
//1.构建缓冲池
BufferedSink sink = Okio.buffer(Okio.sink(file));
//2.向缓存池写入信息
sink.writeUtf8("写入数据");
//3.重新构建缓冲池对象,会清空之前write的信息
sink = Okio.buffer(Okio.appendingSink(file));
//4.重写输入信息
sink.writeUtf8("java.io file!");
//5.关闭缓冲区
sink.close();</span>
(2)BufferedSource
<span style="font-size:14px;"> //1.构建缓冲区
BufferedSource source=Okio.buffer(Okio.source(file));
//2.读文件
source.readUtf8();
//3.关闭缓冲源
source.close(); </span>
(3)Buffer
Sink中写入Buffer
<span style="font-size:14px;"> //1.构建buffer对象
Buffer data = new Buffer();
//2.向缓冲中写入文本
data.writeUtf8("a");
//3.可以连续追加,类似StringBuffer
data.writeUtf8("c");
//4.构建字节数组流对象
ByteArrayOutputStream out = new ByteArrayOutputStream();
//5.构建写缓冲池
Sink sink = Okio.sink(out);
//6.向池中写入buffer
sink.write(data, 3);</span>
Source读取Buffer
<span style="font-size:14px;"> InputStream in = new ByteArrayInputStream(("a" + repeat('b', Segment.SIZE * 2) + "c").getBytes(UTF_8));
//2.缓冲源
Source source = Okio.source(in);
//3.buffer
Buffer sink = new Buffer();
//4.将数据读入buffer
sink.readUtf8(3);</span>
四.Okio源码解析
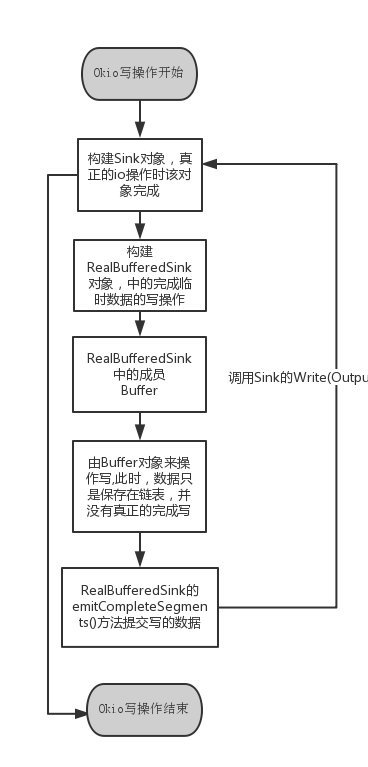
Sink,Source在Okio中的实现只是对OutputStream和Inp0utStream的简单封装
Sink->Okio.sink(OutputStream os)方法实现了write(Buffer buffer,long byteCount)方法
->Okio.buffer(sink)->RealBufferedSinked.writeUtf8(String string)->buffer.writeUtf8();sink.write(buffer,bytCount);
Buffer就相当于一个存储数据的缓冲区, 当调用Okio.buffer(Okio.sink(file));写数据操作时,会写调用buffer.write方法将数据存到Segment双向链表中
然后调用sink.write(buffer,byteCount);传入buffer,将数据从链表取出,完成真正的io操作

五.Okio高效在哪里?
Okio之所以高效是因为在底层的数据结构上,它维护了一个由Segment构成的链表循环队列,一个Segment相当于一个数据块。这样的好处很明显。
因为在一块数据块的进行IO的过程中是没有中断的,相比于每次只读一个byte,单位时间内IO的数据量当然更高。那是不是Segment越大越好?
当然不是。因为Segment内数据的IO还是以byte为单位的,如果Segment过大的话,数据就不能很好的进行分块。想象下把数据只分为一个大的Segment,
那每次IO不就是以byte为单位了吗?那一个Segment的大小为多少比较合适,在我看来,最好和计算机中的一个页面大小一致。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/143979.html原文链接:https://javaforall.net


