
大家好,又见面了,我是你们的朋友全栈君。
原帖地址: http://blog.csdn.net/nsrainbow/article/details/38515007
声明:
- 本文基于Centos 6.x + CDH 5.x
- 官方英文安装教程http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH5/latest/CDH5-Installation-Guide/cdh5ig_hbase_installation.html 。本文并不是简单翻译,而是再整理
- 因为之前说过了HA模式的部署,所以这边不会说单机版的安装,直接说分布式的安装
- 有一个基本常识需要知道,hadoop的配置文件基本上是所有机器都一样的,所以如果有改到配置文件方面基本都是要同步修改所有机器
介绍
Hbase是什么
Hbase的架构
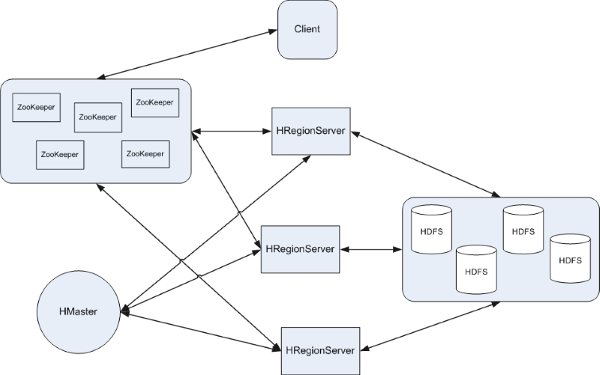

- HMaster— HBase中仅有一个Master server。
- HRegionServer—负责多个HRegion使之能向client端提供服务,在HBase cluster中会存在多个HRegionServer。
安装
配置最大文件数
centos 最大文件数
hdfs - nofile 32768
hbase - nofile 32768
hdfs最大文件数
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>如果不增加这个容易出现以下错误
10/12/08 20:10:31 INFO hdfs.DFSClient: Could not obtain block blk_XXXXXXXXXXXXXXXXXXXXXX_YYYYYYYY from any node:
java.io.IOException: No live nodes contain current block. Will get new block locations from namenode and retry...
安装hbase
host1 上安装吧(根据之前的课程
Alex 的 Hadoop 菜鸟教程: 第4课 Hadoop 安装教程 – HA方式 (2台服务器) 我们有两台机器 host1 和 host2 )
$ sudo yum install hbase -y 如果没有yum源请参考
Alex 的 Hadoop 菜鸟教程: 第2课 hadoop 安装教程 (CentOS6 CDH分支 yum方式)
用
rpm -ql hbase检验安装路径,会发现安装在 /usr/lib/hbase下
安装hbase-master
还是选择在 host1 上安装
yum install hbase-master -y
在 host1 和 host2 两台机子上都修改 /etc/hbase/conf/hbase-site.xml 在 <configuration> 和 </configuration> 之间增加以下2个属性
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>这里的mycluster 是我自己的集群id,具体名称看你在 hdfs-site.xml 里面的 dfs.nameservices 属性配的是什么名字了。
在hdfs上建立 hbase 使用的文件夹
sudo -u hdfs hdfs dfs -mkdir /hbase
sudo -u hdfs hdfs dfs -chown hbase /hbase启动 hbase-master 。 hbase-master 是需要zookeeper的,所以确保你的zookeeper启动了。
安装 RegionServer
官方建议在所有的 datanode 机器上安装 RegionServer 。所以在host1 和 host2 都安装 RegionServer 。
yum install hbase-regionserver -y 安装好后修改
两台机器的配置文件 /etc/hbase/conf/hbase-site.xml ,在 <configuration> 和 </configuration> 中增加以下属性
<property>
<name>hbase.zookeeper.quorum</name>
<value>mymasternode</value>
</property> 这里的 mymasternode 要替换成真实的地址。
这个东西其实我们在 Alex 的 Hadoop 菜鸟教程: 第4课 Hadoop 安装教程 – HA方式 (2台服务器) 中见过,在hdfs的HA配置中有一个属性叫 ha.zookeeper.quorum 配置的是 zookeeper 集群的地址,同理的,这边也是配置了hbase 的 RegionServer 需要的 zookeeper 地址,所以在本例中我们配置成
<property>
<name>hbase.zookeeper.quorum</name>
<value>host1:2181,host2:2181</value>
</property>
启动Hbase
service hbase-master start
service hbase-regionserver start 注意: 确保两台机器的hbase-site.xml的配置是一样的,别某台机器漏掉了某项配置就麻烦了
安装HBase Thrift Server
host1进行安装
yum install hbase-thrift -y启动服务
service hbase-thrift start
服务的启动顺序
- zookeeper
- hbase-master
- 各个regionserver
检验
web界面
shell命令行工具
$ hbase shell
......
hbase(main):001:0> list
TABLE
0 row(s) in 15.1010 seconds
=> []如果没有报任何异常,输出像这样,那么恭喜你成功了!
参考资料
- http://www.uml.org.cn/sjjm/201212141.asp
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/144828.html原文链接:https://javaforall.net


