
大家好,又见面了,我是你们的朋友全栈君。
在数据挖掘或机器学习建模后往往会面临一个问题,就是该模型是否可靠?可靠性如何?也就是说模型的性能如何我们暂时不得而知。
如果模型不加验证就使用,那后续出现的问题将会是不可估计的。所以通常建模后我们都会使用模型评估方法进行验证,当验证结果处于我们的可控范围之内或者效果更佳,那该模型便可以进行后续的进一步操作。
这里又将面临一个新的问题——如何选择评估方法,其实通常很多人都会使用比较简单的错误率来衡量模型的性能,错误率指的是在所有测试样例中错分的样例比例。实际上,这样的度量错误掩盖了样例如何被分错的事实。其实相对于不同的问题会有不同的评估思路:
回归模型:
对于回归模型的评估方法,我们通常会采用平均绝对误差(MAE)、均方误差(MSE)、平均绝对百分比误差(MAPE)等方法。
聚类模型:
对于聚类模型的评估方法,较为常见的一种方法为轮廓系数(Silhouette Coefficient ),该方法从内聚度和分离度两个方面入手,用以评价相同数据基础上不同聚类算法的优劣。
分类模型:
本篇文章将会主要描述分类模型的一种评估方法——混淆矩阵。对于二分类问题,除了计算正确率方法外,我们常常会定义正类和负类,由真实类别(行名)与预测类别(列名)构成混淆矩阵。
首先直观的来看看(混淆矩阵图):
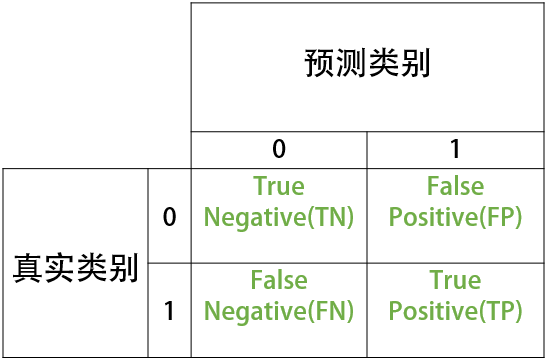

文字详细说明:
- TN:将负类预测为负类(真负类)
- FN:将正类预测为负类(假负类)
- TP:将正类预测为正类(真正类)
- FP:将负类预测为正类(假正类)
最后根据混淆矩阵得出分类模型常用的分类评估指标:
准确率 Accuracy:
测试样本中正确分类的样本数占总测试的样本数的比例。公式如下:
scikit-learn 准确率的计算方法:sklearn.metrics.accuracy_score(y_true, y_pred)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)精确率 Precision:
准确率又叫查准率,测试样本中正确分类为正类的样本数占分类为正类样本数的比例。公式如下:
scikit-learn 精确率的计算方法:sklearn.metrics.precision_score(y_true, y_pred)
from sklearn.metrics import precision_score
precision_score(y_test, y_predict)召回率 Recall:
召回率又称查全率,测试样本中正确分类为正类的样本数占实际为正类样本数的比例。公式如下:
scikit-learn 召回率的计算方法:sklearn.metrics.recall_score(y_true, y_pred)
from sklearn.metrics import recall_score
recall_score(y_test, y_predict)F1 值:
F1 值是查准率和召回率的加权平均数。F1 相当于精确率和召回率的综合评价指标,对衡量数据更有利,更为常用。 公式如下:
scikit-learn F1的计算方法:sklearn.metrics.f1_score(y_true, y_pred)
from sklearn.metrics import f1_score
f1_score(y_test, y_predict)ROC 曲线:
在部分分类模型中(如:逻辑回归),通常会设置一个阈值如0.5,当大于0.5归为正类,小于则归为负类。因此,当减小阈值如0.4时,模型将会划分更多测试样本为正类。这样的结果是提高了正类的分类率,但同时也会使得更多负类被错分为正类。
在ROC 曲线中有两个参数指标——TPR、FPR,公式如下:
TPR 代表能将正例分对的概率(召回率),而 FPR 则代表将负例错分为正例的概率。
TPR作为ROC 曲线的纵坐标,FPR作为ROC曲线的横坐标,如下图:
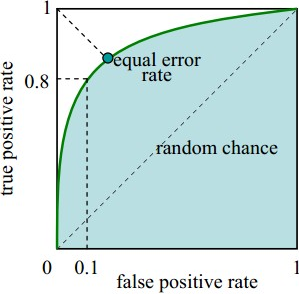
由图可得:
-
当 FPR=0,TPR=0 时,意味着将每一个实例都预测为负例。
-
当 FPR=1,TPR=1 时,意味着将每一个实例都预测为正例。
-
当 FPR=0,TPR=1 时,意味着为最优分类器点。
所以一个优秀的分类器对应的ROC曲线应该尽量靠近左上角,越接近45度直线时效果越差。
scikit-learn ROC曲线的计算方法:
sklearn.metrics.roc_curve(y_true, y_score)AUC 值:
AUC 的全称为 Area Under Curve,意思是曲线下面积,即 ROC 曲线下面积 。通过AUC我们能得到一个准确的数值,用来衡量分类器好坏。
-
AUC=1:最佳分类器。
-
0.5<AUC<1:分类器优于随机猜测。
-
AUC=0.5:分类器和随机猜测的结果接近。
-
AUC<0.5:分类器比随机猜测的结果还差。
scikit-learn AUC的计算方法:
sklearn.metrics.auc(y_true, y_score)from matplotlib import pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
model = LogisticRegression()
model.fit(X_train,y_train.ravel())
y_score = model.decision_function(X_test) # model训练好的分类模型
fpr, tpr, _ = roc_curve(y_test, y_score) # 获得FPR、TPR值
roc_auc = auc(fpr, tpr) # 计算AUC值
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend()
plt.show()
由于(精准率、召回率)与(偏差、方差)很相似,都是一对需要平衡的衡量值,(偏差、方差)衡量模型的拟合能力与泛化能力,而(精准率、召回率)则需要考虑的情况更多,主要如下3点:
1:如果某个业务需要控制一定的成本,同时还想要最大限制的预测出更多的问题。(精确率、召回率 平衡)
2:(极端情况)如果某个业务成本可以最大化,只要得出所有的可能性。(牺牲精确率,提高召回率)
3:(极端情况)如果某个业务成本需要最小化,只要模型不出错即可。(牺牲召回率,提高精确率)
提高阈值,如逻辑回归中修改sigmoid函数的判断阈值k=0.5,我们来看看精确率与召回率的变化情况:
1:提高k大于0.5,精确率提高,召回率下降
2:降低k小于0.5,精确率下降,召回率提高
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/146475.html原文链接:https://javaforall.net


