
大家好,又见面了,我是你们的朋友全栈君。
scrapy爬虫部部署服务器
时间:2020年5月27日18:28:30
作者:钟健
记录:scrapy爬虫
关键字:scrapy scrapyd scrapydweb
一、scrapy爬虫部署服务器
scrapy通过命令行运行一般只用于测试环境,而用于运用在生产环境则一般都部署在服务器中进行远程操作。
scrapy部署服务器有一套完整的开源项目:scrapy+scrapyd(服务端)+scrapy-client(客户端)+scrapydweb
1、scrapyd
1.介绍
Scrapyd是用于部署和运行Scrapy爬虫的应用程序。它使您可以使用JSON API部署(上传)项目并控制其爬虫。
是目前分布式爬虫的最好解决方法之一
官方文档 https://scrapyd.readthedocs.io/
2.安装
pip install scrapyd
安装过程中可能会遇到大量的错误,大部分都是所依赖的包没有安装,安装过程中要确保scrapy已经安装成功,只要耐心的将所有缺少的依赖包安装上就可以了
-
打开命令行,输入scrapyd,如下图:


-
浏览器访问:http://127.0.0.1:6800/
2、scrapy-client
1.介绍:
scrapy-client它允许我们将本地的scrapy项目打包发送到scrapyd 这个服务端(前提是服务器scrapyd正常运行)
官方文档https://pypi.org/project/scrapyd-client/
2.安装
pip install scrapy-client
和上面的scrapyd一样,可能会遇到各种错误,耐心一点,大部分都是安装依赖
3、scrapydweb(可选)
1.介绍
ScrapydWeb:用于Scrapyd集群管理的Web应用程序,支持Scrapy日志分析和可视化。
官方文档:https://pypi.org/project/scrapydweb/
2.安装
pip install scrapyd
在保持scrapyd挂起的情况下运行命令scrapydweb,也就是需要打开两个doc窗口
运行命令scrapydweb,首次启动将会在当前目录下生成配置文件“scrapydweb_settings_v*.py”
-
更改配置文件
编辑配置文件,将ENABLE_LOGPARSER更改为False -
添加访问权限
SCRAPYD_SERVERS = [ '127.0.0.1:6800', # 'username:password@localhost:6801#group', ('username', 'password', 'localhost', '6801', 'group'), ] -
HTTP基本认证
ENABLE_AUTH = True USERNAME = 'username' PASSWORD = 'password'
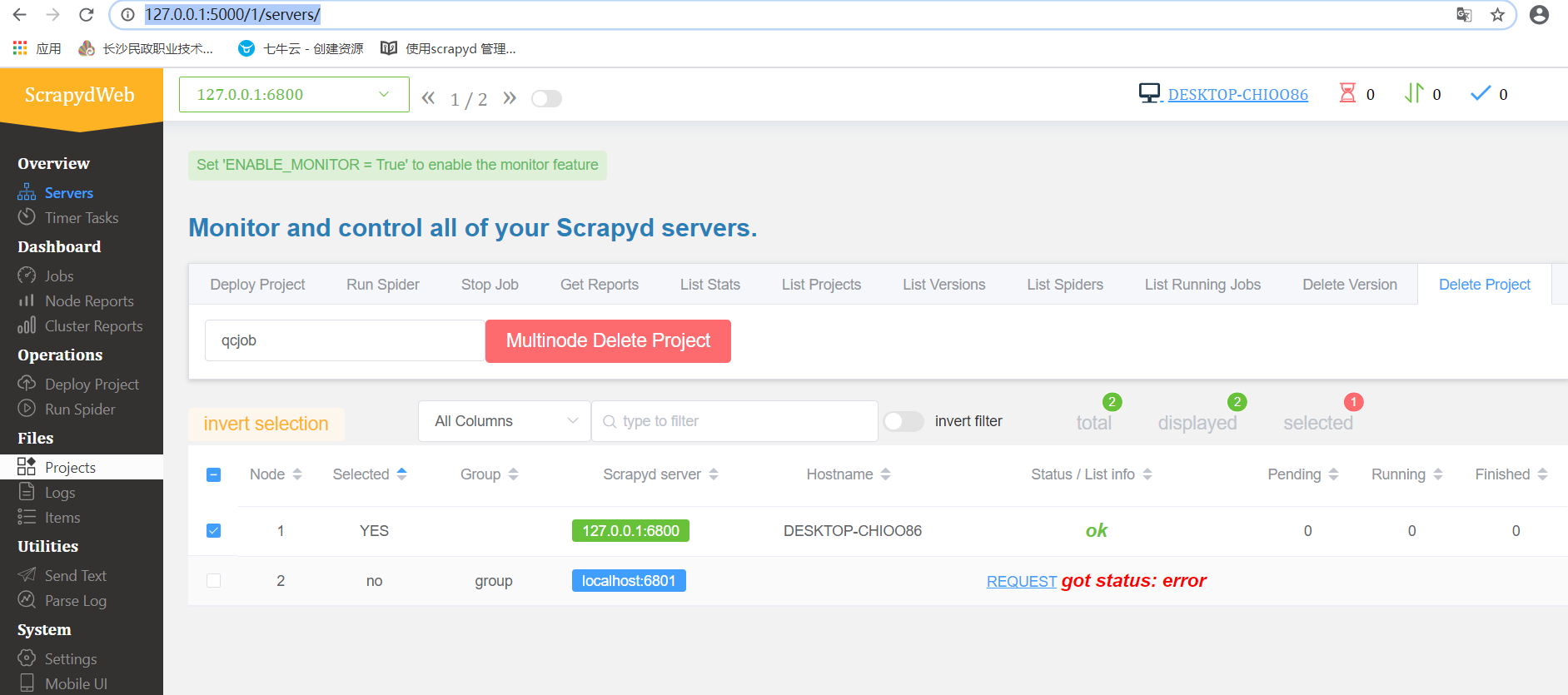
浏览器访问:http://127.0.0.1:5000/1/servers/
二、实际操作(一切的操作都在scrapyd启动的情况下)
1.上传爬虫
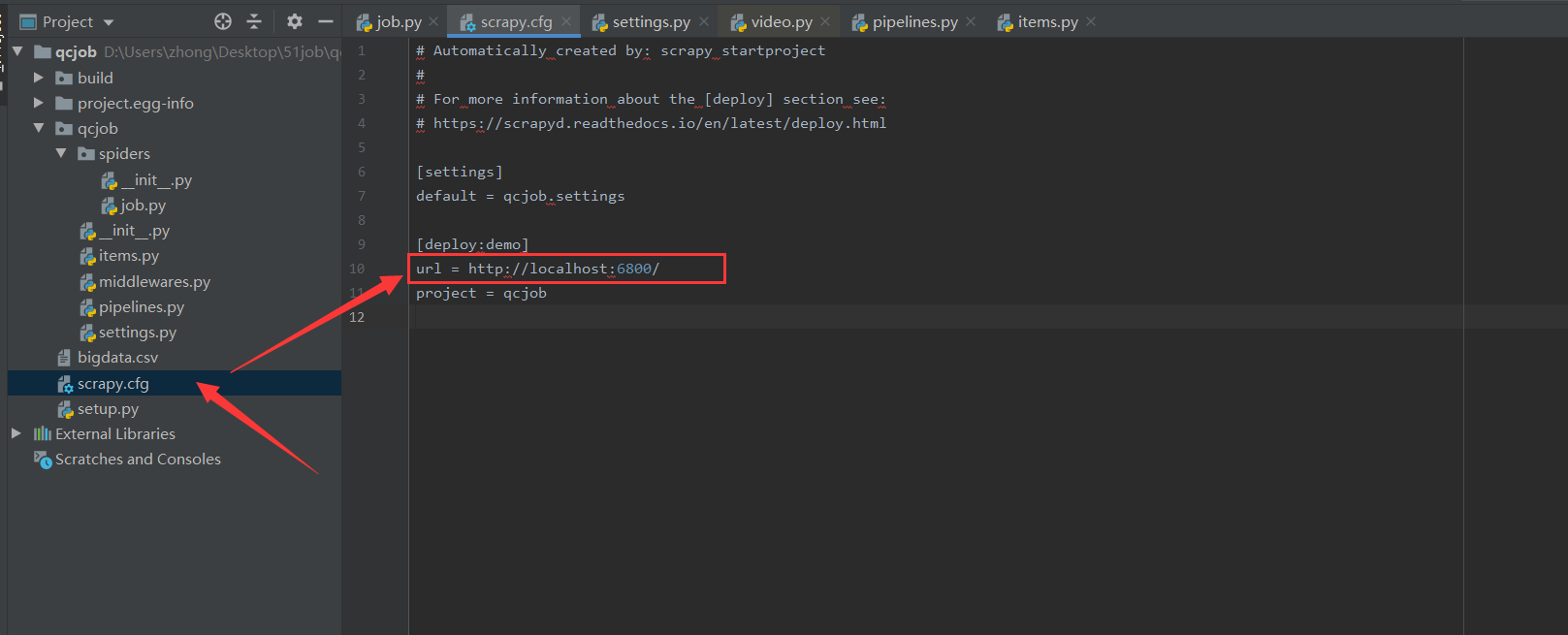
编辑scrapy.cfg,url是scrapyd服务器的位置,由于scrapyd在本地,所以是localhost。
注意:我们要切换到和scrapy.cfg同级目录下,继续以下操作
scrapyd-deploy

上图表示运行成功!
以上的文件夹是成功后自动创建的(为什么之前的截图有,我之前已经测试过)
然后输入以下命令上传服务器
scrapyd-deploy demo -p qcjob
结构:scrapyd-deploy -p (scrapyd-deploy <目标> -p <项目>)
运行成功的图片

2.启动爬虫
cmd输入(爬取一天内关于java的职业需求)
curl http://localhost:6800/schedule.json -d project=qcjob -d spider=job -d key = java time=0
我编写的爬虫可以根据用户输入的参数来爬取数据
key=表示关键字(默认是全部)
time=表示时间(0=24小时,1=3天内,2=一周内,3=一个月内,默认为0)
当然scrapyd强大之处在于可以用http方式控制爬虫
http://localhost:6800/schedule.json?project=qcjob&spider=job&key=java&time=0 #POST
以下是用postmain进行模拟post请求。
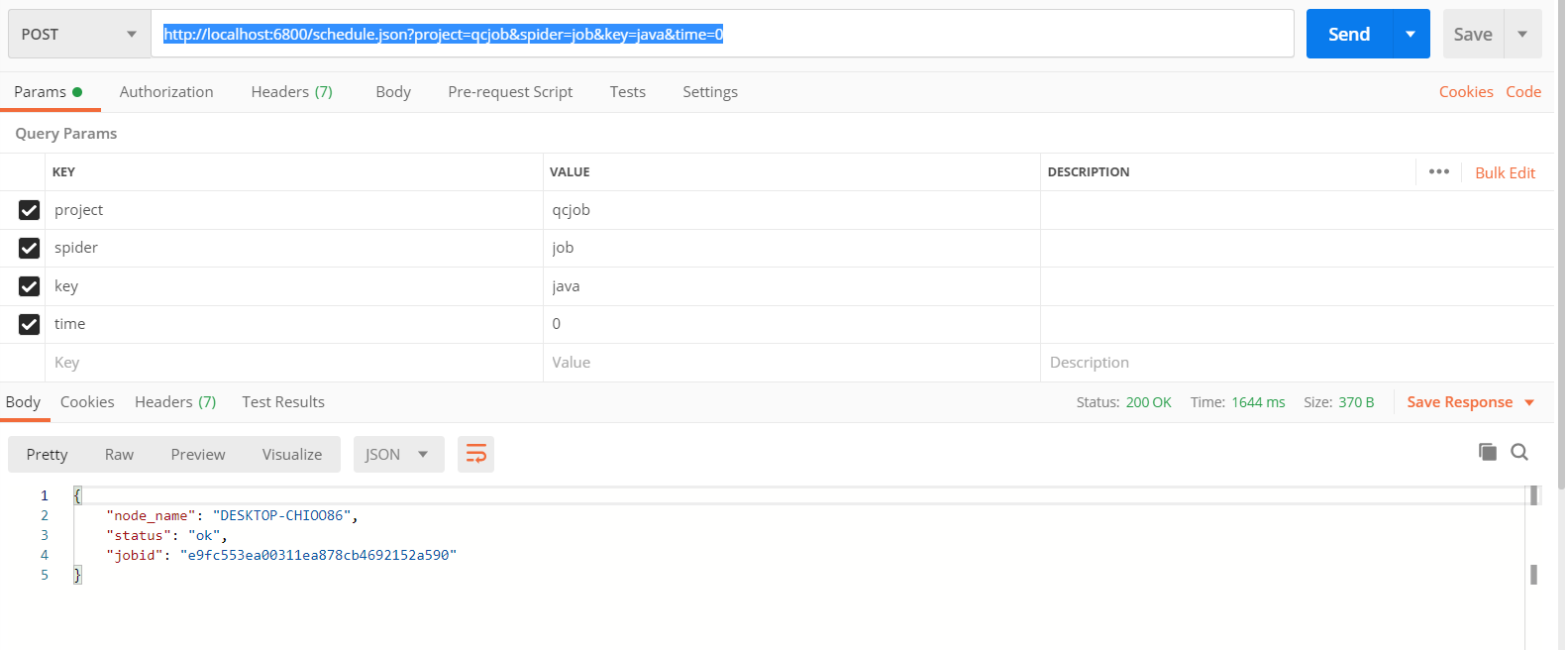
然后进入http://127.0.0.1:6800/
点击job,就可以查看爬虫是否运行,和运行时间
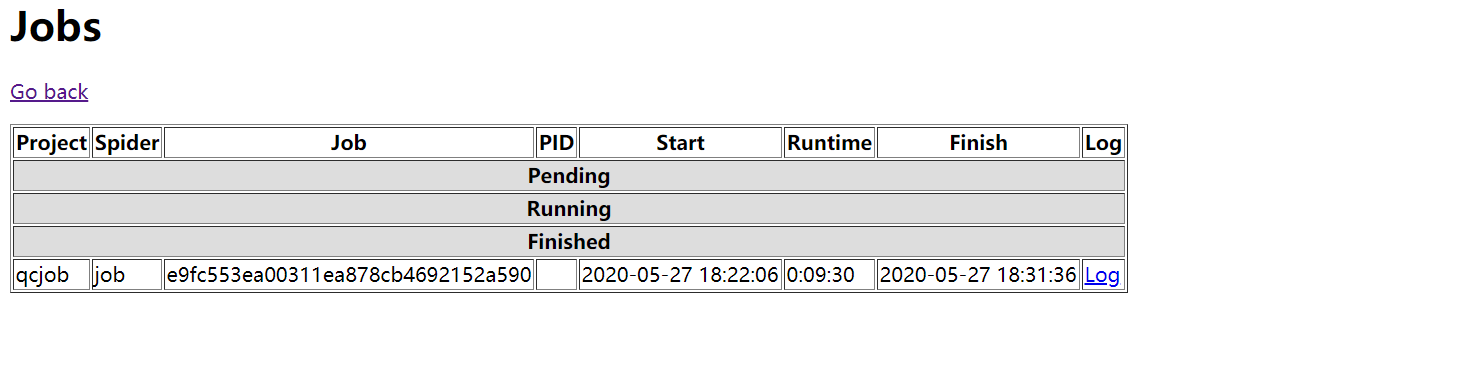
从图可以看出,这个爬虫运行了9分31秒。
当然我们也可以从scrapydweb中查看和管理爬虫浏览器访问:http://127.0.0.1:5000/1/servers/
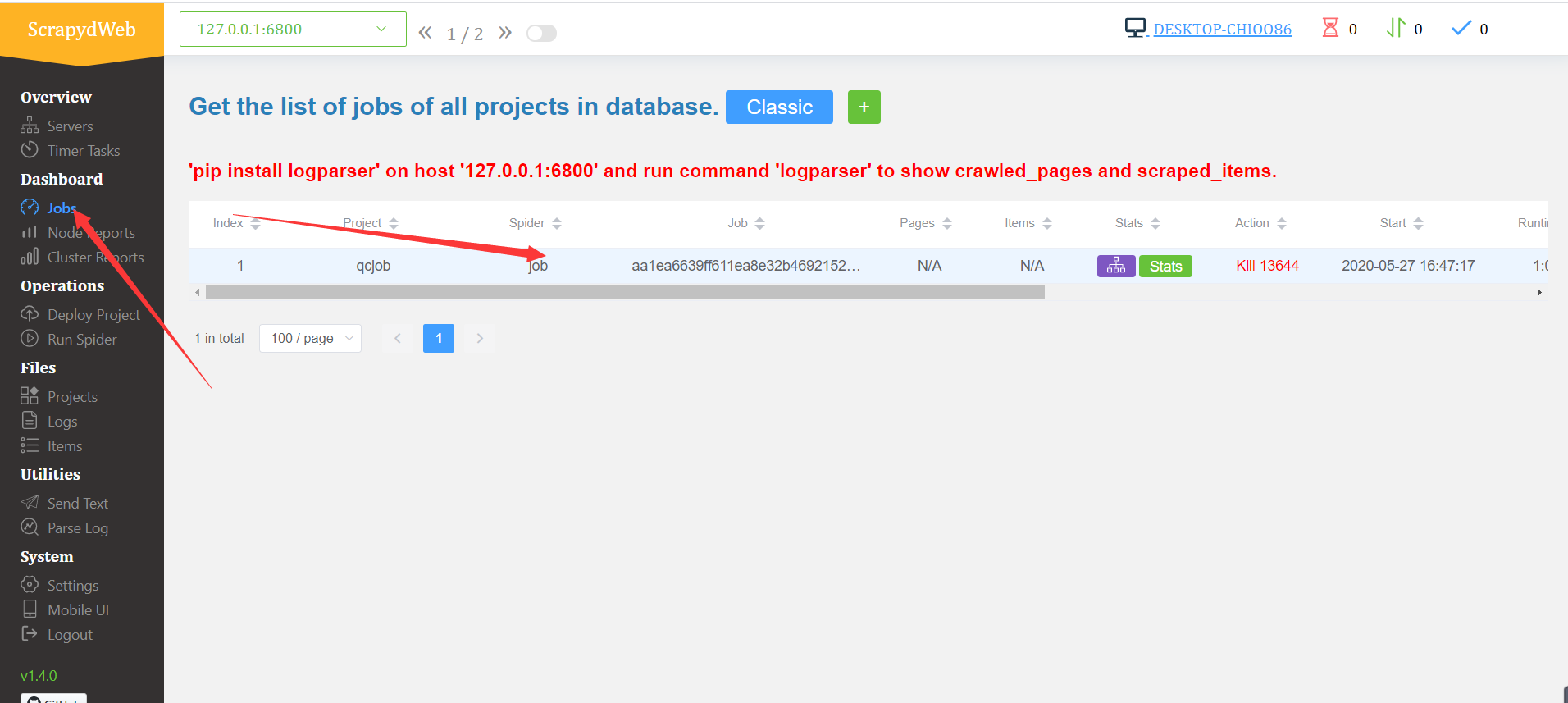
我们可以通过可视化界面来控制爬虫运行,scrapyd可以启动多个不同的爬虫,一个爬虫的多个版本启动。是目前分布式爬虫的最好解决方法!!!
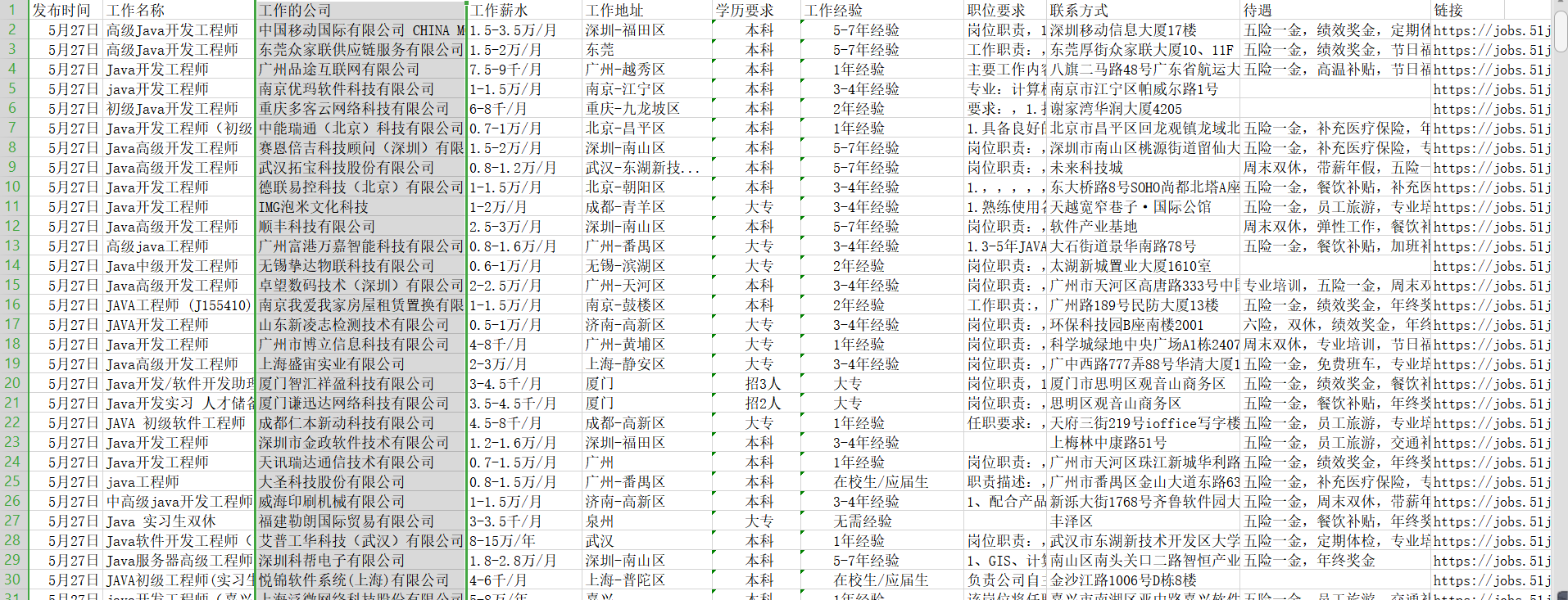
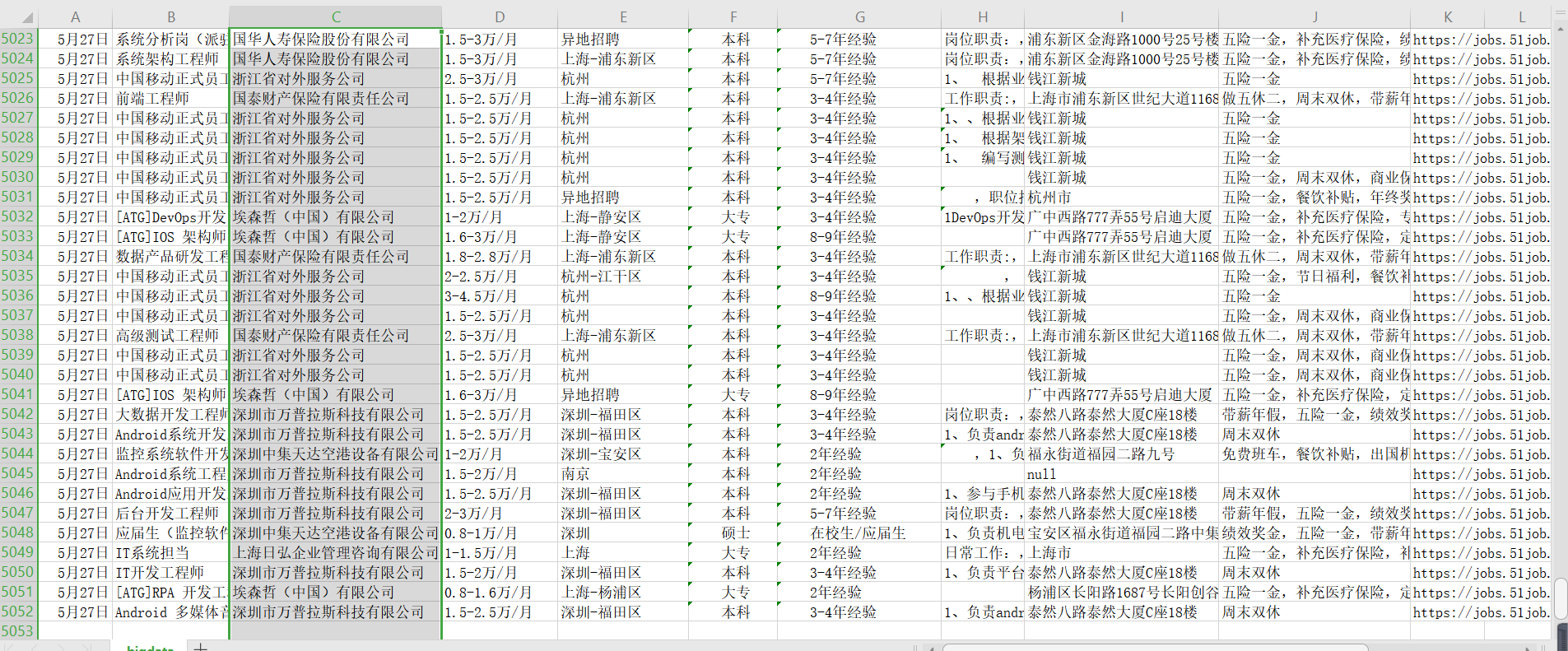
三、数据展示
本次爬取花费9分31秒,共爬去25,000余条数据,爬虫速度开至每秒8次访问,以他该服务器的最大访问量
其中部分数据存在有误,为了保证速度,没有进行过多的筛取和排查,错误率保持较低水平
四、问题与思考
- 通过爬去可以看得出,如果采用单一的爬虫的话,爬取速度还是比较慢的,如果采用多个爬虫,分布式爬取的话,就存在数据是否重复以及数据的共用问题。
- 如果采用分布式爬虫的话,就涉及到ip代理,因为一台机器如果大量访问的话经过测试会导致浏览器访问,该网页都无法打开,如果设置IP代理,就需要大量的代理IP
- 虽然爬虫已经部署在服务器上,但是还是无法做到,通过用户输入关键字时间等地址等多个参数进行爬取数据,无法做到实时展示,只能先运行爬虫,爬取大量数据储存与数据库,然后才能进行分析,做出图表。
- 关于数据的统计与展示,单一的sql语句,很难满足其对大量数据的分析,可能需要用Python的数据分析库,对数据进行处理,然后才能展示。
五、收获
已经可以通过http请求的方式来控制爬虫的启动停止,以及传递参数,就等于scrapy爬虫是可以集成于web应用里面的。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/150367.html原文链接:https://javaforall.net


