
大家好,又见面了,我是你们的朋友全栈君。
一、简介
RDN——Residual Dense Network—— 残差深度网络
RDN是基于深度学习的超分方法之一,发表于CVPR 2018
二、结构
RDN网络结构分为4个部分:
1、SFENet(Shallow Feature Extraction Net, 浅层特征提取网络)
2、RDBs( Residual Dense Blocks, 残差稠密块)
3、DFF(Dense Feature Fusion, 稠密特征块 )
4、Up-Sampling Net(上采样网络)
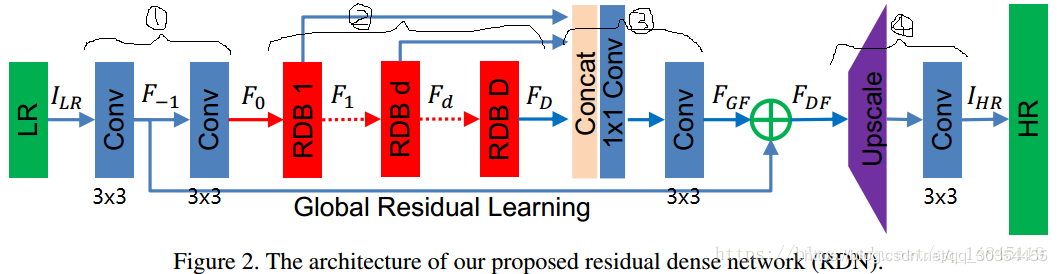

2.1 SFENet
包含两个CONV层,用于提取浅层特征
2.2 RDBs
包含D个RDB,用于提取各层特征,一个RDB提取出一个局部特征。RDB结构如下图(c)所示:
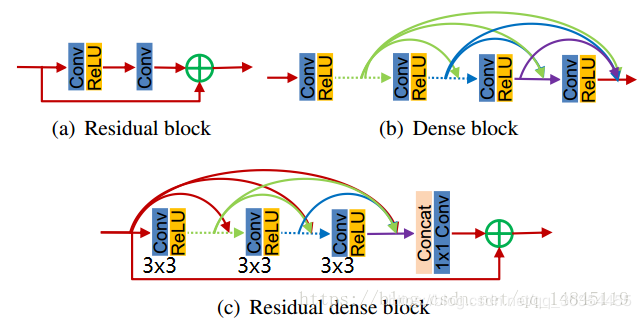
可以看出,RDB = Residual block(残缺块) + Dense block(稠密块)
由于网络深度的增加,每层CONV层的特征会逐渐分级(得到hierarchical features),因为有不同的感受野(receptive fileds)。而Hierarchical features对图像重建提供了重要信息, 我们要充分利用所有层的信息和特征。
一个RDB结构分为3个部分:
2.2.1 CM(Contiguous Memory 近邻记忆)
RDB含有C个[CONV+ReLU],CM机制会将上一个RDB的状态发送到当前RDB中的每一个CONV层,也就是图(c)的小桥们
2.2.2 LFF(Local Feature Fusion 局部特征融合)
LLF将前一个RDB的各个状态与当前RDB的所有CONV层融合在一起。
RDN中,前一个RDB输出的feature-map 是直接与当前RDB串联起来的,这时,减少feature的数量就很有必要了。
我们使用一个11的CONV来减少feature的数量/控制输出信息:11CONV用于减少通道数,并保持nh,nw不变(具体看吴恩达深度学习4.2.5笔记)
2.2.3 LRL(Local Residual Learning 局部残差学习)
也就是将以下两者加起来,看c图下部的红箭头以及绿色加号:
前一RDB的输出 + 上面LFF的1*1CONV的输出
引入LRL以进一步提高信息流、提高网络表示能力,以达到更好的性能
2.3 DFF(Dense Feature Fusion, 稠密特征块 )
DFF在全局上提取各层特征。
包含两个部分:
2.3.1. GFF(global feature fusion 全局特征融合)
GFF 用于将所有RDB提取到的特征融合在一起,得到全局特征。GFF分为两部分:
1x1 CONV 融合一系列的特征(1*1CONV的作用就是减少通道数,并保持Nh, Nw,详见吴恩达4.2.5)
3x3 CONV 为下一步的GRL进一步提取特征
2.3.2. GRL(global residual learning 全局残差学习)
就是RDN结构图中的绿色加号
就是实现:
浅层特征 + 所有RDB提取到的特征
2.4 UPNet(Up-Sampling Net 上采样网络)
该模块表示网络最后的上采样+卷积操作。实现了输入图片的放大操作。
三、实现细节
- 除了用于融合局部或全局特征的CONV层的kernel size = 1×1 外,其他的CONV层都是 3×3的
- kernel size = 3×3的CONV层,都用SAME padding 以保持inputsize不变
- 浅层特征提取层、局部全局特征融合层的CONV的filter数量都是G0 = 64
- 其他层(RDB中)的CONV的filter数量都是G,并使用ReLU作为其激活函数
- 使用ESPCNN来提高粗分辨率特征,从而使得UPNet性能更好(???)
- RDN最后的CONV,若需要输出彩色高清图像,则可设置其输出的channel = 3;若需要输出灰度高清图像,可设置其输出的channel = 1
四、讨论(与其他网络的区别)
4.1 Difference to DenseNet
- 受DenseNet的启发,将局部密集连接加入到了RDB中
- 与DenseNet不同:移除了BN层,以提高运算速度降低计算复杂度和GPU内存的消耗
- 与DenseNet不同:移除了Pooling层,防止其将像素级的信息给去除掉
- 在RDN中,我们使用了局部残差学习,来将密集连接层和局部特征融合(LFF)结合起来
- 在RDN中,前一个RDB提取到的特征会与当前RDB的每一个CONV直接连接起来(局部特征融合LFF),更好地保障了信息流的贯通
- 与DenseNet不同:使用GFF将各RDB提取的特征全部concat起来,充分利用。而DenseNet 整个网络中只使用每一个DenseBlock最后的输出。
4.2 Difference to SRDenseNet
- RDN在三个方面对SRDenseNet的DenseNet进行了改进:
1)加入了CM机制,使得先前的RDB模块和当前的RDB模块都有直接接触
2)使用了LFF,使得RDB可以用更大的增长率
3)RDB中的LRL模块增加了信息和梯度的流动 - 在RDB中,提取全局特征时不使用Dense Connection,取而代之的是DFF(Dense Feature Fusion, 稠密特征块,包含GFF和GRL)
- 损失函数:SRDenseNet使用L2 ;RDN使用L1(提高了性能,加快了收敛)
4.3 Difference to MemNet
- 损失函数:MemNet使用L2 ;RDN使用L1(提高了性能,加快了收敛)
- MemNet要用Bicubic插值方式对LR图片进行上采样,从而使LR图片达到所需的大小,这就导致特征提取和重建过程都在HR空间(高分辨率空间)中进行;而RDN从原始的LR图片(低分辨率图片)提取各层特征,很大程度上减少了计算的复杂度,并提高了性能
- MemNet中包含了递归和门限单元,这使得当前层不能接收上一层的输入,而RDB的前后模块是有交互的
- MemNet 没有全部利用中间的特征信息,而RDN通过Global Residual Learning 将所有信息都利用起来。
五、实验及结果
5.1 实验设置:
数据集
- 数据集: DIV2K(800 training imgs + 100 vali imgs + 100 testing imgs)
- 训练:DIV2K——800 training img + 5 vali img
- 测试:五个standard benchmark datasets:Set5 [1], Set14 [33], B100 [18], Urban100 [8], and Manga109 [19].
退化模型
训练的输入图片(LR)使用DIV2K的高清图片通过下面3种退化模型得到:
- BI模型:Bicubic插值方式对高清图片进行下采样, 缩小比例为x2,x3,x4
- BD模型:先对高清图片做(7*7卷积,1.6方差)高斯滤波,再对滤波后图片做下采样, 缩小比例为x3。
- DN模型:①Bicubic插值方式对高清图片进行下采样, 缩小比例为x3,②再加30%的高斯噪声。
训练设置
- 在每个训练batch中,随机取出16张RGB的LR patches(shape = 32 * 32)作为输入
- 随机地对patches做数据增强——上下翻转,垂直翻转90°等
- 一个epoch包含1000个iteration
- 使用Touch7框架来写RDN,并使用Adam作为优化器
- 所有层的学习率初始化都是10-4,并且每200个epoch就减少至一半
- 训练RDN需要一天的时间,泰坦GPU,200个epoch
超参D/C/G的设置
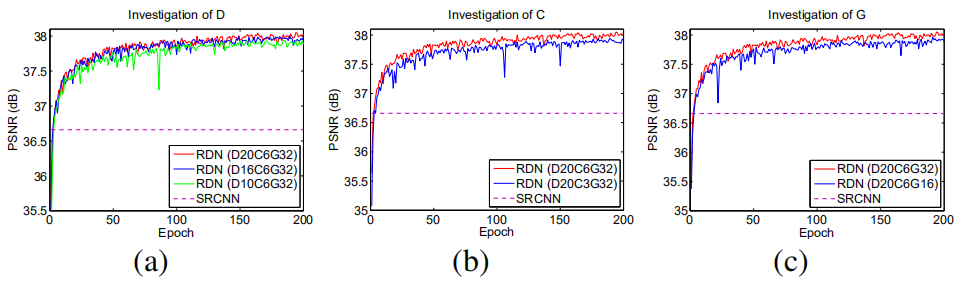
从上图看出,大的D/C/G值能提升性能,原因是加深了网络深度
Ablation Investigation(消融研究)

可看出, CM, LRL, and GFF 缺一不可,缺一个性能就下降
实验结果(退化模型下)
- 在BI退化模型下:
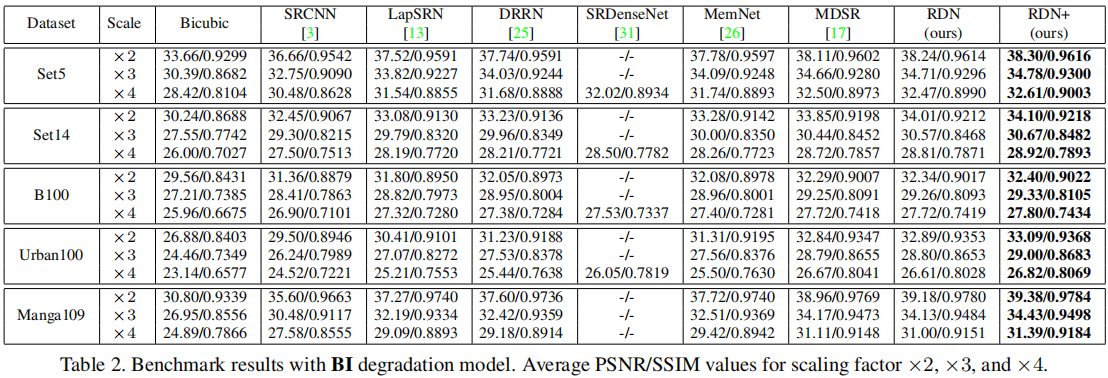
可看出,RDN的重建效果最佳 - 在BD和DN退化模型下:
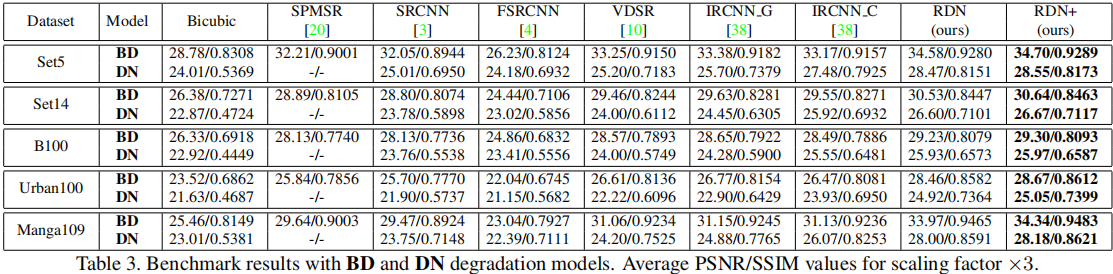


可看出,依然是RDN的重建效果最佳
实验结果(真是图片下)
在真实图片下,不再有原始的高清图片(如DIV2K),因此也当然没有退化模型,真实图片的退化模型(比如湍流大气和视宁度造成的模糊)都是未知规律的

从结果可以看出,分层特征对于不同或未知的退化模型执行依然有鲁棒性(强健)
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/150421.html原文链接:https://javaforall.net


