
大家好,又见面了,我是你们的朋友全栈君。
论文:
Residual Dense Network for Image Super-Resolution
Github:
https://github.com/yulunzhang/RDN
https://github.com/hengchuan/RDN-TensorFlow
整体结构:

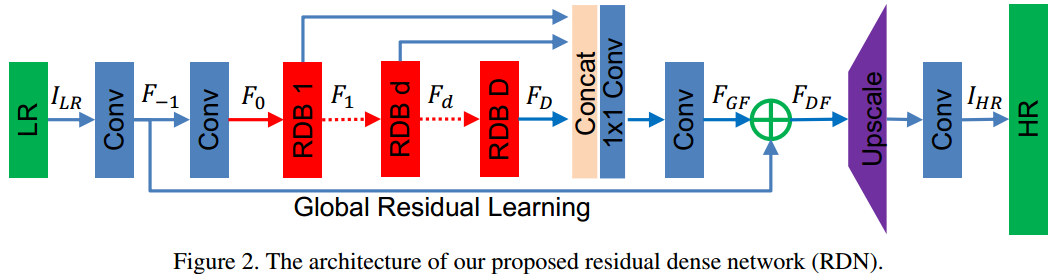
RDN(Residual Dense Network)主要包含4个模块。
(1)shallow feature extraction net (SFENet)
该模块主要表示前2个卷积层。
(2)redidual dense blocks (RDBs)
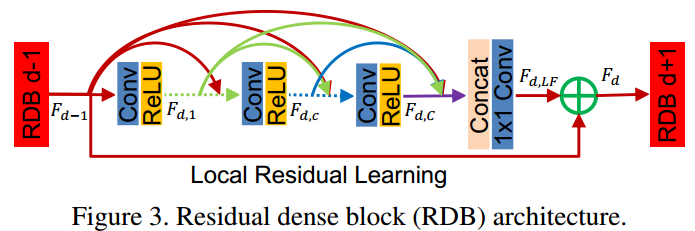
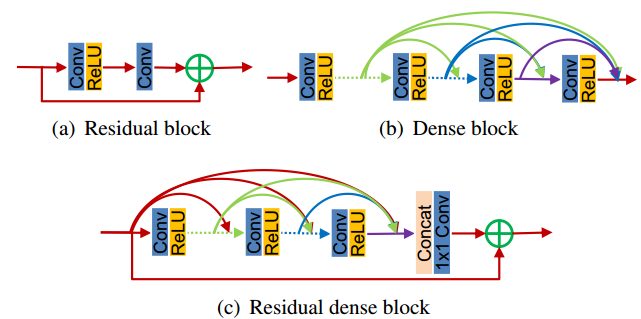
RDB模块主要将残差模块residual block和dense block模块进行了整合,将两者集合起来,形成了residual dense block 。3个模块的区别如下图所示。
其中,Contiguous memory 表示将Fd-1,Fd,1,Fdc,FdC的特征都利用起来。Local feature fusion 表示concat后的1*1卷积操作,该操作有助于更大增长率的RDB模块的训练。Local residual learning表示将Fd-1和Fd,LF的特征进行融合,该操作有助于提升模型的表达能力。
(3)dense feature fusion (DFF)
该模块包含Global feature fusion 和Global residual learning 两部分。Global feature fusion表示对F1,F2……FD特征的利用。Global residual learning表示F-1和FGF的加和操作。其实和RDB一样的套路。
(4)up-sampling net (UPNet)
该模块表示网络最后的上采样+卷积操作。实现了输入图片的放大操作。
RDN和DenseNet block的区别:
(1)RDN中的RDB模块去掉了DenseNet每个block中的batchnorm
(2)RDN中的RDB模块去掉了DenseNet每个block中的pooling
(3)DenseNet中每一个dense block的输出都是concat起来的。而RDB将d-1层的特征也和1到d层的特征做了局部特征融合(local feature fusion (LFF)),更好的保证了信息流的贯通。
(4)在整个RDN网络上,每一个RDB模块的输出都会最终被concat起来利用。而DenseNet 整个网络中只使用每一个DenseBlock最后的输出。
RDN和SRDenseNet 的区别:
(1)RDN通过3个方面改进SRDenseNet 中使用的传统DenseBlock模块。1,加入了contiguous memory (CM) mechanism 使得先前的RDB模块和当前的RDB模块都有直接接触。2,得益于local feature fusion (LFF) ,RDB模块可以容许更大的增长率。3,RDB中Local residual
learning (LRL) 的应用增加了信息和梯度的流动。
(2)RDB内部没有稠密连接。
(3)SRDenseNet 使用L2 loss,RDB使用L1 loss。
RDN和MemNet 的区别:
(1)MemNet 需要对原始图片使用Bicubic插值方式进行上采样,而RDN直接使用原始低分辨图片,优势就是可以减少计算量和提高效果。
(2)MemNet 中包含逆向和门限单元的模块就不再接受先前模块的输入,而RDB各个模块之间是有信息流交互的。
(3)MemNet 没有全部利用中间的特征信息,而RDN通过Global Residual Learning 将所有信息都利用起来。
数据集DIV2K :
https://data.vision.ee.ethz.ch/cvl/DIV2K/
图片为高质量的2k图片,包含800张训练集,100张测试集,100张验证集。
训练的输入图片使用该2k图片通过下面3种处理得到。
(1)BI方式:主要通过Bicubic下采样得到,缩小比例为x2,x3,x4
(2)BD方式:先对原始图片做(7*7卷积,1.6方差)高斯滤波,再对滤波后图片做下采样。
(3)DN方式:先做Bicubic下采样,再加30%的高斯噪声。
总结:
(1)RDB这种集合Residual Block和DenseBlock的思想并进行改进做的很好。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/150425.html原文链接:https://javaforall.net


