
大家好,又见面了,我是你们的朋友全栈君。
Pytorch 转置卷积
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. 转置卷积(transposed convolution)
卷积不会增大输入的高和宽,通常要么不变,要么减半。而转置卷积则可以用来增大输入高宽。
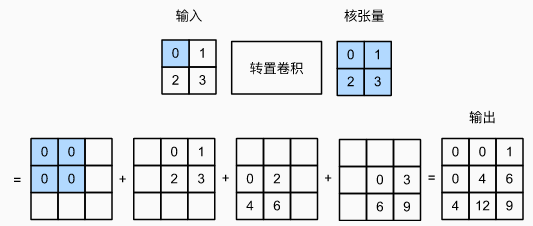

假设忽略通道,步幅为 1 且填充为 0。输入张量形状为 n h × n w n_h \times n_w nh×nw,卷积核形状为 k h × k w k_h \times k_w kh×kw。共产生 n h n w n_hn_w nhnw 个中间结果。每个中间结果都是一个 ( n h + k h − 1 ) × ( n w + k w − 1 ) (n_h+k_h-1)\times(n_w+k_w-1) (nh+kh−1)×(nw+kw−1) 的张量(初始化为 0)。计算中间张量的方法:输入张量中的每个元素乘以卷积核,得到 k h × k w k_h \times k_w kh×kw 的张量替换中间张量的一部分。
每个中间张量被替换部分的位置与输入张量中元素的位置相对应。 最后,所有中间结果相加以获得最终结果。
中间张量计算公式如下:
Y [ i : i + h , j : j + w ] + = X [ i , j ] ∗ K Y[i: i + h, j: j + w] += X[i, j] * K Y[i:i+h,j:j+w]+=X[i,j]∗K
1.1 为什么称之 “转置” ?
对于卷积 Y = X ★ W Y = X ★ W Y=X★W ( ★ ★ ★ 表示卷积操作)
- 可以对 W W W 构造一个 V V V,使得卷积等价于矩阵乘法 Y ′ = V X ′ Y^{\prime} = VX^{\prime} Y′=VX′
- 这里 Y ′ 和 X ′ Y^{\prime} 和 X^{\prime} Y′和X′ 是 Y , X Y, X Y,X 对应的向量版本。
转置卷积则等价于 Y ′ = V T X ′ Y^{\prime} = V^TX^{\prime} Y′=VTX′
如果卷积将输入从 ( h , w ) (h, w) (h,w) 变成了 ( h ′ , w ′ ) (h^{\prime}, w^{\prime}) (h′,w′)
- 同样超参数的转置卷积则从 ( h ′ , w ′ ) (h^{\prime}, w^{\prime}) (h′,w′) 变成了 ( h , w ) (h, w) (h,w)
2. 转置卷积实现
2.1 转置卷积
!pip install -U d2l
import torch
from torch import nn
from d2l import torch as d2l
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i: i + h, j: j + w] += X[i, j] * K
return Y
X = torch.tensor([[0.0, 1.0],
[2.0, 3.0]])
K = torch.tensor([[0.0, 1.0],
[2.0, 3.0]])
trans_conv(X, K)

2.2 API 实现
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
# 前两个参数代表输入通道数, 输出通道数
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
tconv(X)

2.3 填充,步幅和多通道
与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷积将填充应用于输入)。 例如,当将高和宽两侧的填充数指定为1时,转置卷积的输出中将删除第一和最后的行与列。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)
tconv.weight.data = K
tconv(X)
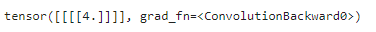
在转置卷积中,步幅被指定为中间结果(输出),而不是输入。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
tconv.weight.data = K
tconv(X)

输入 X X X 的形状,经过卷积后,再经过转置卷积后的形状与原形状相同:
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)
tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)
tconv(conv(X)).shape == X.shape

2.4 与矩阵变换的联系
X = torch.arange(9.0).reshape(3, 3)
K = torch.tensor([[1.0, 2.0],
[3.0, 4.0]])
Y = d2l.corr2d(X, K)
Y

将卷积核 K K K 重写为包含大量 0 0 0 的稀疏权重矩阵 W W W( 4 × 9 4 \times 9 4×9):
def kernel2matrix(K):
k, W = torch.zeros(5), torch.zeros((4, 9))
k[:2], k[3:5] = K[0, :], K[1, :]
W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k
return W
W = kernel2matrix(K)
W

Y == torch.matmul(W, X.reshape(-1)).reshape(2, 2)

Z = trans_conv(Y, K)
Z == torch.matmul(W.T, Y.reshape(-1)).reshape(3, 3)

3. 再谈转置卷积
转置卷积是一种卷积
- 它将输入和核进行了重新排列
- 同卷积一般是做下采样(将高和宽变得更小),而转置卷积通常用作上采样(输出高宽变大)
- 如果卷积将输入从 ( h , w ) (h, w) (h,w) 变成了 ( h ′ , w ′ ) (h^{\prime}, w^{\prime}) (h′,w′),同样超参数下转置卷积将 ( h ′ , w ′ ) (h^{\prime}, w^{\prime}) (h′,w′) 变成 ( h , w ) (h, w) (h,w)。
注:
下采样:由输入图片得到特征图
上采样:由特征图得到预测图
3.1 重新排列输入和核
当填充为 0 0 0,步幅为 1 1 1 时
- 将输入填充 k − 1 k-1 k−1 ( k k k 是核窗口)
- 将核矩阵上下、左右翻转
- 然后做正常卷积(填充 0 0 0, 步幅 1 1 1)
( p , s ) = ( 0 , 1 ) (p,s) = (0, 1) (p,s)=(0,1)
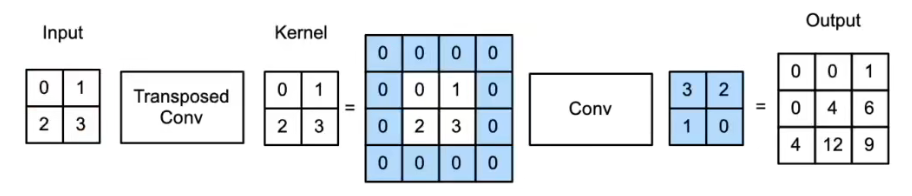
当填充为 p p p,步幅为 1 1 1 时
- 将输入填充 k − p − 1 k-p-1 k−p−1 ( k k k 是核窗口)
- 将核矩阵上下、左右翻转
- 然后做正常卷积(填充 0 0 0、步幅 1 1 1)
( p , s ) = ( 1 , 1 ) (p,s) = (1, 1) (p,s)=(1,1)

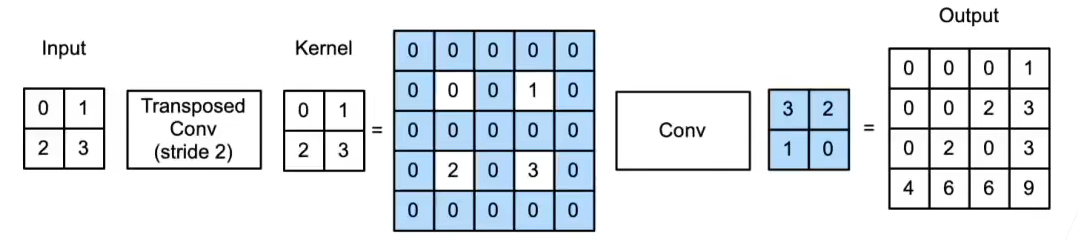
当填充为 p p p,步幅为 s s s 时
- 在行和列之间插入 s − 1 s-1 s−1 行和列
- 将输入填充 k − p − 1 k-p-1 k−p−1 ( k k k 是核窗口)
- 将核矩阵上下、左右翻转
- 然后做正常卷积(填充 0 0 0、步幅 1 1 1)
( p , s ) = ( 0 , 2 ) (p,s) = (0, 2) (p,s)=(0,2)
3.2 形状换算
输入高(宽)为 n n n,核 k k k,填充 p p p,步幅 s s s。
转置卷积: n ′ = s n + k − 2 p − s n^{\prime} = sn + k -2p – s n′=sn+k−2p−s
- 卷积: n ′ = ⌊ ( n − k − 2 p + s ) / s ⌋ → n ≥ s n ′ + k − 2 p − s n^{\prime} = \lfloor(n-k-2p+s)/s\rfloor \to n \ge sn^{\prime} +k -2p -s n′=⌊(n−k−2p+s)/s⌋→n≥sn′+k−2p−s
如果让高宽成倍增加,那么 k = 2 p + s k=2p+s k=2p+s
3.3 转置卷积与反卷积的关系
数学上的反卷积(deconvolution)是指卷积的逆运算
- 如果 Y = c o n v ( X , K ) Y=conv(X, K) Y=conv(X,K),那么 X = d e c o n v ( Y , K ) X = deconv(Y, K) X=deconv(Y,K)
反卷积很少用在深度学习中
- 我们说的反卷积神经网络指的是用了转置卷积的神经网络
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/151945.html原文链接:https://javaforall.net


