
大家好,又见面了,我是你们的朋友全栈君。
一.前言
在最近的开发中用到了dom4j来解析xml文件,以前听说过来解析xml文件的几种标准方式;但是从来的没有应用过来,所以可以在google中搜索dmo4j解析xml文件的方式,学习一下dom4j解析xml的具体操作。
二.代码详情
dom4j是一个第三方开发组开发出的插件,所以在我们使用dom4jf的时候我们要去下载一下dom4j对应版本的jar导入在我们项目中。
1)xml文件:
|
1 2 3 4 5 6 7 8 9 10 11 |
|
示例一:用List列表的方式来解析xml
SAXReader就是一个管道,用一个流的方式,把xml文件读出来
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
|
示例二:使用Iterator迭代器的方式来解析xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
运行结果:
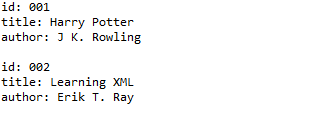

示例三:创建xml文档并输出到文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
运行结果:

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/152021.html原文链接:https://javaforall.net


