
大家好,又见面了,我是你们的朋友全栈君。
目录
Scrapy是啥
scrapy是一个使用python编写的开源网络爬虫框架。这里的框架实际上就是应用程序的骨架,是一个半成品,框架能够保证程序结构风格统一。
Scrapy的安装
pip install Scrapy。但在此之前要先安装几个包:
在cmd中运行以下语句:
(1) pip install wheel
(2) pip install lxml
(3) pip install twisted
(4) 最后 pip install scrapy
(5) 验证Scrapy框架是否安装成功:
打开python,试试import scrapy 和scrapy.version_info


如图看到Scrapy库的版本为2.4.1
实例:爬取美剧天堂new100:
(1)创建工程:
找一个文件夹,打开cmd进入该目录。
输入命令:
Scrapy startproject movie
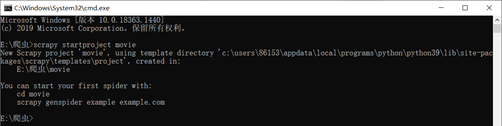
这时可以看到该目录下多了一个叫movie的文件夹,而这个文件夹里面还有一个叫movie的文件夹,里面是这样的:
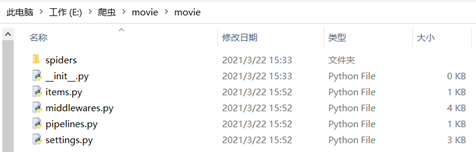
这样Scrapy项目就成功创建了。
(2) 创建爬虫程序
用cd先进入movie目录,输入命令:
Scrapy genspider meiju meijutt.tv

该命令创建了一个叫meiju的爬虫
这时查看spiders目录可以看到多了一个meiju.py,就是我们刚创建的爬虫。
(3) 编辑爬虫
用编辑器打开meiju.py
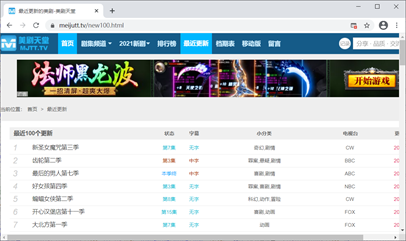
这个网站的内容是我们的爬取目标
import scrapy
from movie.items import MovieItem
class MeijuSpider(scrapy.Spider): # 继承这个类
name = 'meiju' #名字
allowed_domains = ['meijutt.tv'] # 域名
start_urls = ['https://www.meijutt.tv/new100.html'] # 要补充完整
def parse(self, response):
movies = response.xpath('//ul[@class="top-list fn-clear"]/li') # 看不懂
for each_movie in movies:
item = MovieItem()
item['name'] = each_movie.xpath('./h5/a/@title').extract()[0]
yield item # 一种特殊的循环
(4)设置item模板:
在items中输入:
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
(5) 设置配置文件
在settings.py中增加代码:
ITEM_PIPELINES = {
'movie.pipelines.MoviePipeline':100}
(6)设置数据处理脚本:
在pipelines.py中输入代码:
import json
class MoviePipeline(object):
def process_item(self, item, spider):
return item
(7)运行爬虫
在爬虫根目录执行命令:
Scrapy crawl meiju
Emm发现meiju.py有错误,看了一下是由于冒号后面的语句没有缩进。
现在看看那两个xpath选择器的内容:
movies = response.xpath('//ul[@class="top-list fn-clear"]/li')
# 意思是选中所有的属性class值为"top-list fn-clear"的ul下的li标签内容
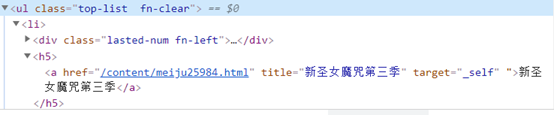
也就是说movies得到的是li标签之间的内容的列表
for each_movie in movies:
item = MovieItem()
item['name'] = each_movie.xpath('./h5/a/@title').extract()[0]
# .表示选取当前节点,也就是对每一项li,其下的h5下的a标签中title的属性值
yield item # 一种特殊的循环
修改增加缩进,并修改第一个xpath的内容后再次运行:
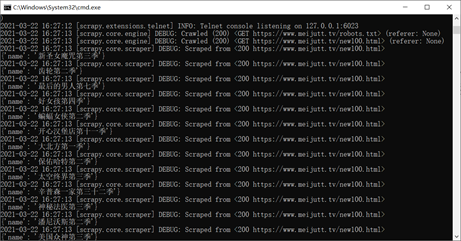
可以看到爬取成功
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/153134.html原文链接:https://javaforall.net

![基于量化交易回测的金融股票案例基础知识[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
