
大家好,又见面了,我是你们的朋友全栈君。
文章目录
今天是五一假期第一天,这里先给大家拜个晚 咳咳!!祝大家五一快乐,我这里给大家奉上一篇硬核教程。首先声明,这篇文章不是教你如何写正则表达式,而是教你写一个能执行正则表达式的
执行引擎。 网上教你写正则表达式的文章、教程很多,但教你写引擎的并不多。很多人认为我就是用用而已,没必要理解那么深,但知道原理是在修炼内功,正则表达式底层原理并不单单是用在这,而是出现在计算机领域的各个角落。理解原理可以让你以后写字符串匹配时正则表达式能够信手拈来,理解原理也是触类旁通的基础。废话不多说,直接开始正式内容。
本文是我个人做的动手实践性项目,所以未完整支持所有语法,而且因为是用NFA实现的所以性能比生产级的执行引擎差好多。目前源码已开放至https://github.com/xindoo/regex,后续会继续更新,欢迎Star、Fork 提PR。
目前支持的正则语义如下:
- 基本语法: . ? * + () |
- 字符集合: []
- 特殊类型符号: \d \D \s \S \w \W
前置知识
声明:本文不是入门级的文章,所以如果你想看懂后文的内容,需要具备以下的基本知识。
- 基本的编程知识,虽然这里我是用java写的,但并不要求懂java,懂其他语法也行,基本流程都是类似,就是语法细节不同。
- 了解正则表达式,知道简单的正则表达式如何写。
- 基本的数据结构知识,知道有向图的概念,知道什么是递归和回溯。
有限状态机
有限状态机(Finite-state machine),也被称为有限状态自动机(finite-state automation),是表示有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型(From 维基百科 状态机) 。 听起来晦涩难懂,我用大白话描述一遍,状态机其实就是用图把状态和状态之间的关系描述出来,状态机中的一个状态可以在某些给定条件下变成另外一种状态。举个很简单的例子你就懂了。
比如我今年18岁,我现在就是处于18岁的状态,如果时间过了一年,我就变成19岁的状态了,再过一年就20了。当然我20岁时时光倒流2年我又可以回到18岁的状态。这里我们就可以把我的年龄状态和时间流逝之间的关系用一个自动机表示出来,如下。
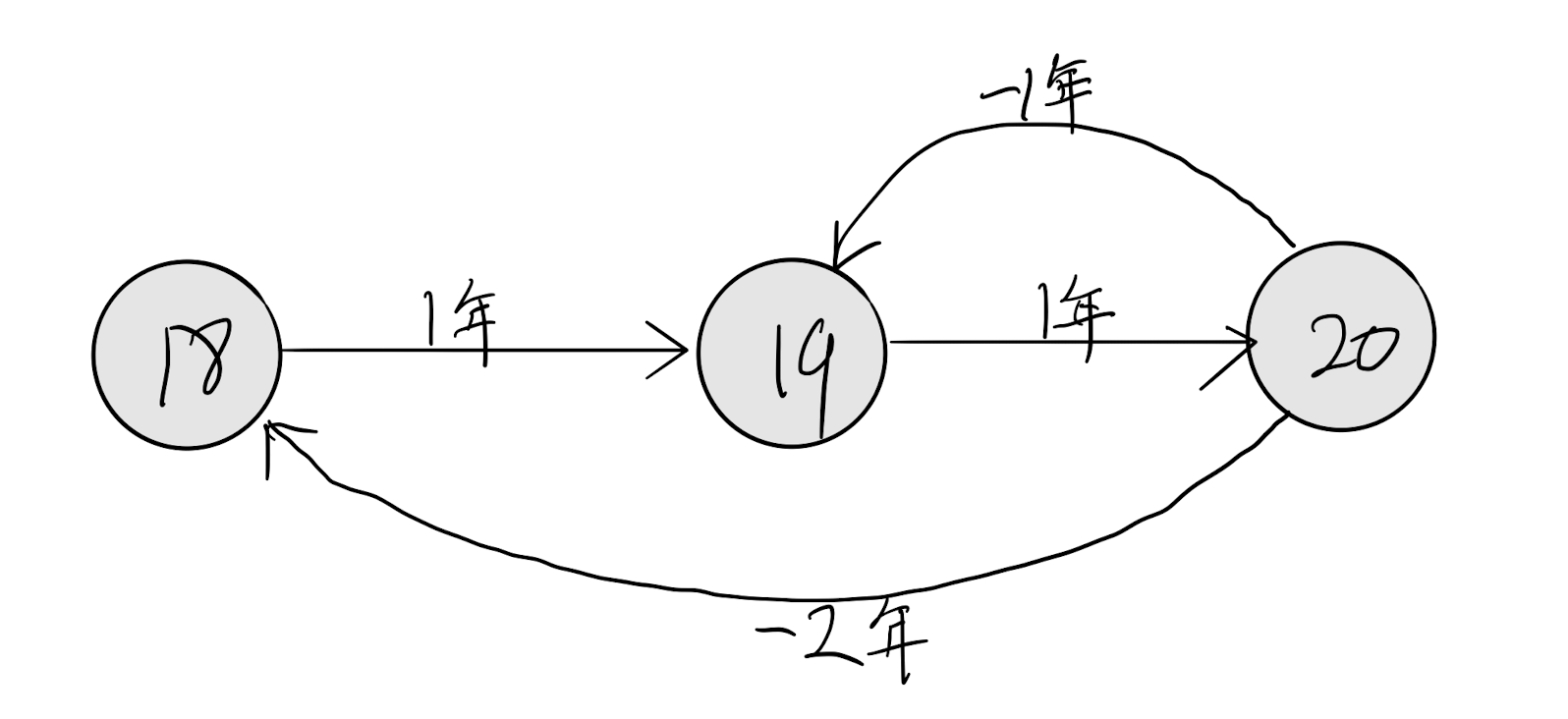

每个圈代表一个节点表示一种状态,每条有向边表示一个状态到另一个状态的转移条件。上图中状态是我的年龄,边表示时间正向或者逆向流逝。
有了状态机之后,我们就可以用状态机来描述特定的模式,比如上图就是年龄随时间增长的模式。如果有人说我今年18岁,1年后就20岁了。照着上面的状态机我们来算下,1年后你才19岁,你这不是瞎说吗! 没错,状态机可以来判定某些内容是否符合你状态机描述的模式了。哟,一不小心就快扯到正则表达式上了。
我们这里再引入两种特殊的状态:起始态和接受态(终止态),见名知意,不用我过多介绍了吧,起始态和终止态的符号如下。

我们拿状态机来做个简单的字符串匹配。比如我们有个字符串“zsx”,要判断其他字符串是否和”zxs”是一致的,我们可以为”zxs”先建立一个自动机,如下。

对于任意一个其他的字符串,我们从起始态0开始,如果下一个字符能匹配到0后边的边上就往后走,匹配不上就停止,一直重复,如果走到终止态3说明这个字符串和”zxs“一样。任意字符串都可以转化成上述的状态机,其实到这里你就知道如何实现一个只支持字符串匹配的正则表达式引擎了,如果想支持更多的正则语义,我们要做的更多。
状态机下的正则表达式
我们再来引入一条特殊的边,学名叫 ϵ \epsilon ϵ闭包(emm!看到这些符号我就回想起上学时被数学支配的恐惧),其实就是一条不需要任何条件就能转移状态的边。

没错,就只这条红边本边了,它在正则表达式状态机中起着非常重要的连接作用,可以不依赖其他条件直接跳转状态,也就是说在上图中你可以直接从1到2。
有了 ϵ \epsilon ϵ闭包的加持,我们就可以开始学如何画正则表达式文法对应的状态机了。
串联匹配
首先来看下纯字符匹配的自动机,其实上面已经给过一个”zxs”的例子了,这里再贴一下,其实就是简单地用字符串在一起而已,如果还有其他字符,就继续往后串。
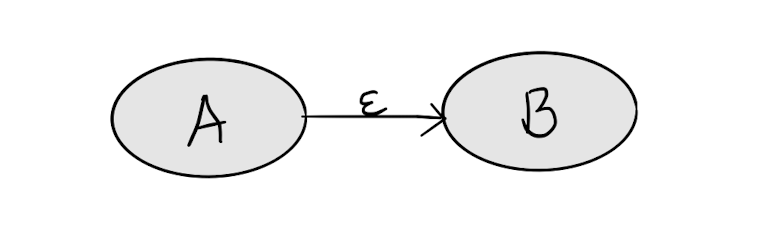
两个表达式如何传在一起,也很简单,假如我们已经有两个表达式A B对应的状态机,我们只需要将其用 ϵ \epsilon ϵ串一起就行了。
并联匹配 (正则表达式中的 |)
正则表达式中的**|** 标识二选一都可以,比如A|B A能匹配 B也能匹配,那么A|B就可以表示为下面这样的状态图。
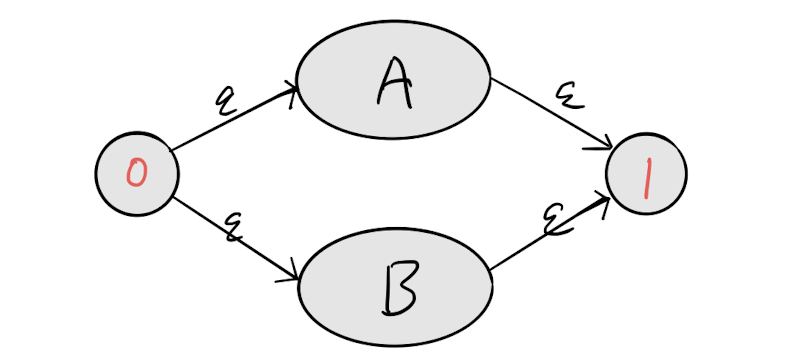
从0状态走A或B都可以到1状态,完美的诠释了A|B语义。
重复匹配(正则表达式中的 ? + *)
正则表达式里有4种表示重复的方式,分别是:
- ?重复0-1次
-
- 重复1次以上
-
- 重复0次以上
- {n,m} 重复n到m次
我来分别画下这4种方式如何在状态机里表示。
重复0-1次 ?
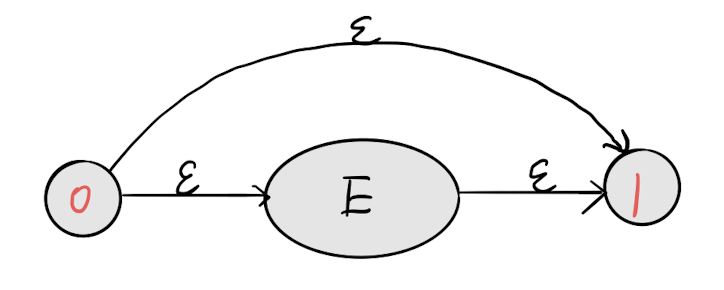
0状态可以通过E也可以依赖 ϵ \epsilon ϵ直接跳过E到达1状态,实现E的0次匹配。
重复1次以上
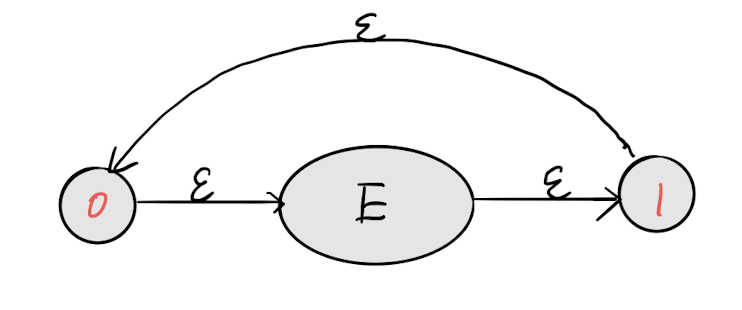
0到1后可以再通过 ϵ \epsilon ϵ跳回来,就可以实现E的1次以上匹配了。
重复0次以上
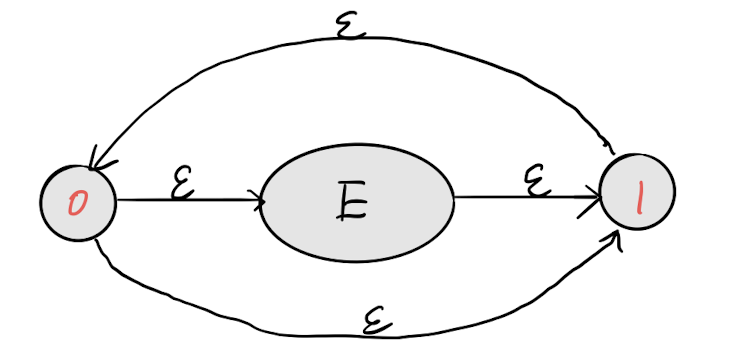
仔细看其实就是**? +**的结合。
匹配指定次数
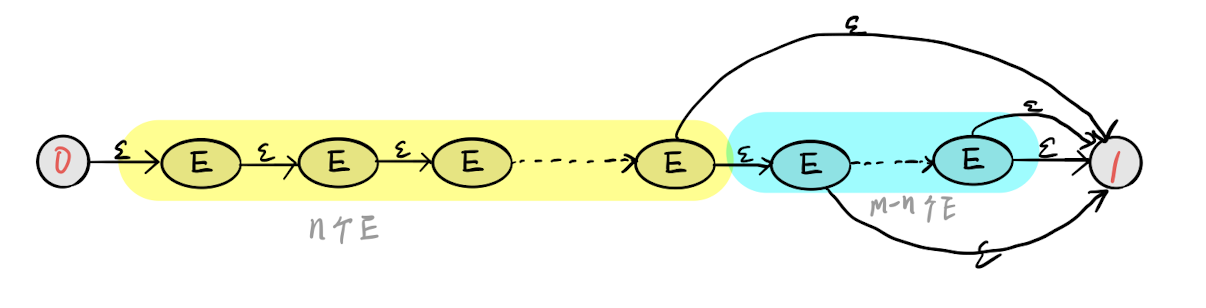
这种建图方式简单粗暴,但问题就是如果n和m很大的话,最后生成的状态图也会很大。其实可以把指定次数的匹配做成一条特殊的边,可以极大减小图的大小。
特殊符号(正则表达式中的 . \d \s……)
正则表达式中还支持很多某类的字符,比如**.表示任意非换行符,\d标识数字,[]**可以指定字符集…… ,其实这些都和图的形态无关,只是某调特殊的边而已,自己实现的时候可以选择具体的实现方式,比如后面代码中我用了策略模式来实现不同的匹配策略,简化了正则引擎的代码。
子表达式(正则表达式 () )
子表达可以Tompson算法,其实就是用递归去生成**()**中的子图,然后把子图拼接到当前图上面。(什么Tompson说的那么高大上,不就是递归吗!)
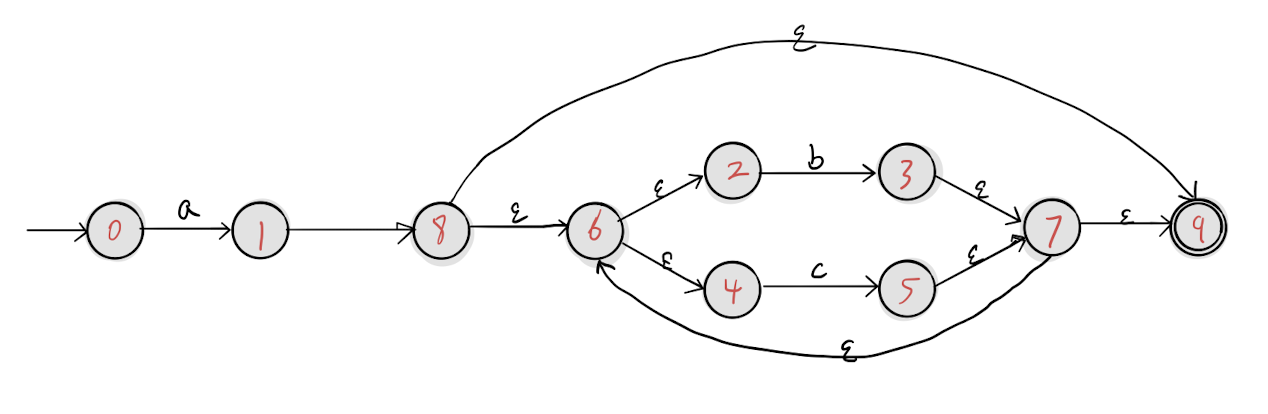
练习题
来练习画下 a(a|b)* 的状态图,这里我也给出我画的,你可以参考下。
代码实现
建图
看完上文之后相信你一直知道如果将一个正则表达式转化为状态机的方法了,这里我们要将理论转化为代码。首先我们要将图转化为代码标识,我用State表示一个节点,其中用了Map<MatchStrategy, List> next表示其后继节点,next中有个key-value就是一条边,MatchStrategy用来描述边的信息。
public class State {
private static int idCnt = 0;
private int id;
private int stateType;
public State() {
this.id = idCnt++;
}
Map<MatchStrategy, List<State>> next = new HashMap<>();
public void addNext(MatchStrategy path, State state) {
List<State> list = next.get(path);
if (list == null) {
list = new ArrayList<>();
next.put(path, list);
}
list.add(state);
}
protected void setStateType() {
stateType = 1;
}
protected boolean isEndState() {
return stateType == 1;
}
}
NFAGraph表示一个完整的图,其中封装了对图的操作,比如其中就实现了上文中图串 并联和重复的操作(注意我没有实现{})。
public class NFAGraph {
public State start;
public State end;
public NFAGraph(State start, State end) {
this.start = start;
this.end = end;
}
// |
public void addParallelGraph(NFAGraph NFAGraph) {
State newStart = new State();
State newEnd = new State();
MatchStrategy path = new EpsilonMatchStrategy();
newStart.addNext(path, this.start);
newStart.addNext(path, NFAGraph.start);
this.end.addNext(path, newEnd);
NFAGraph.end.addNext(path, newEnd);
this.start = newStart;
this.end = newEnd;
}
//
public void addSeriesGraph(NFAGraph NFAGraph) {
MatchStrategy path = new EpsilonMatchStrategy();
this.end.addNext(path, NFAGraph.start);
this.end = NFAGraph.end;
}
// * 重复0-n次
public void repeatStar() {
repeatPlus();
addSToE(); // 重复0
}
// ? 重复0次哦
public void addSToE() {
MatchStrategy path = new EpsilonMatchStrategy();
start.addNext(path, end);
}
// + 重复1-n次
public void repeatPlus() {
State newStart = new State();
State newEnd = new State();
MatchStrategy path = new EpsilonMatchStrategy();
newStart.addNext(path, this.start);
end.addNext(path, newEnd);
end.addNext(path, start);
this.start = newStart;
this.end = newEnd;
}
}
整个建图的过程就是依照输入的字符建立边和节点之间的关系,并完成图的拼接。
private static NFAGraph regex2nfa(String regex) {
Reader reader = new Reader(regex);
NFAGraph nfaGraph = null;
while (reader.hasNext()) {
char ch = reader.next();
String edge = null;
switch (ch) {
// 子表达式特殊处理
case '(' : {
String subRegex = reader.getSubRegex(reader);
NFAGraph newNFAGraph = regex2nfa(subRegex);
checkRepeat(reader, newNFAGraph);
if (nfaGraph == null) {
nfaGraph = newNFAGraph;
} else {
nfaGraph.addSeriesGraph(newNFAGraph);
}
break;
}
// 或表达式特殊处理
case '|' : {
String remainRegex = reader.getRemainRegex(reader);
NFAGraph newNFAGraph = regex2nfa(remainRegex);
if (nfaGraph == null) {
nfaGraph = newNFAGraph;
} else {
nfaGraph.addParallelGraph(newNFAGraph);
}
break;
}
case '[' : {
edge = getCharSetMatch(reader);
break;
}
case '^' : {
break;
}
case '$' : {
break;
}
case '.' : {
edge = ".";
break;
}
// 处理特殊占位符
case '\\' : {
char nextCh = reader.next();
switch (nextCh) {
case 'd': {
edge = "\\d";
break;
}
case 'D': {
edge = "\\D";
break;
}
case 'w': {
edge = "\\w";
break;
}
case 'W': {
edge = "\\W";
break;
}
case 's': {
edge = "\\s";
break;
}
case 'S': {
edge = "\\S";
break;
}
// 转义后的字符匹配
default:{
edge = String.valueOf(nextCh);
break;
}
}
break;
}
default : {
// 处理普通字符
edge = String.valueOf(ch);
break;
}
}
if (edge != null) {
NFAState start = new NFAState();
NFAState end = new NFAState();
start.addNext(edge, end);
NFAGraph newNFAGraph = new NFAGraph(start, end);
checkRepeat(reader, newNFAGraph);
if (nfaGraph == null) {
nfaGraph = newNFAGraph;
} else {
nfaGraph.addSeriesGraph(newNFAGraph);
}
}
}
return nfaGraph;
}
这里我用了设计模式中的策略模式将不同的匹配规则封装到不同的MatchStrategy类里,目前我实现了**. \d \D \s \S \w \w**,具体细节请参考代码。这么设计的好处就是简化了匹配策略的添加,比如如果我想加一个**\x** 只匹配16进制字符,我只需要加个策略类就好了,不必改很多代码。
匹配
其实匹配的过程就出从起始态开始,用输入作为边,一直往后走,如果能走到终止态就说明可以匹配,代码主要依赖于递归和回溯,代码如下。
public boolean isMatch(String text) {
return isMatch(text, 0, nfaGraph.start);
}
private boolean isMatch(String text, int pos, State curState) {
if (pos == text.length()) {
if (curState.isEndState()) {
return true;
}
return false;
}
for (Map.Entry<MatchStrategy, List<State>> entry : curState.next.entrySet()) {
MatchStrategy matchStrategy = entry.getKey();
if (matchStrategy instanceof EpsilonMatchStrategy) {
for (State nextState : entry.getValue()) {
if (isMatch(text, pos, nextState)) {
return true;
}
}
} else {
if (!matchStrategy.isMatch(text.charAt(pos))) {
continue;
}
// 遍历匹配策略
for (State nextState : entry.getValue()) {
if (isMatch(text, pos + 1, nextState)) {
return true;
}
}
}
}
return false;
}
下集预告
还有下集?没错,虽然到这里已经是实现了一个基本的正则表达式引擎,但距离可用在生产环境还差很远,预告如下。
功能完善化
本身上面的引擎对正则语义支持不是很完善,后续我会继续完善代码,有兴趣可以收藏下源码https://github.com/xindoo/regex,但应该不会出一篇新博客了,因为原理性的东西都在这里,剩下的就是只是一些编码工作 。
DFA引擎
上文只是实现了NFA引擎,NFA的引擎建图时间复杂度是O(n),但匹配一个长度为m的字符串时因为涉及到大量的递归和回溯,最坏时间复杂度是O(mn)。与之对比DFA引擎的建图时间复杂度O(n^2),但匹配时没有回溯,所以匹配复杂度只有O(m),性能差距还是挺大的。
DFA引擎实现的大体流程是先构造NFA(本文内容),然后用子集构造法将NFA转化为DFA,预计未来我会出一篇博客讲解细节和具体实现。
正则引擎优化
首先DFA引擎是可以继续优化的,使用Hopcroft算法可以进一步将DFA图压缩,更少的状态节点更少的转移边可以实现更好的性能。其次,目前生产级的正则引擎很多都不是单纯用NFA或者DFA实现的,而是二者的结合,不同正则表达式下用不同的引擎可以达到更好的综合性能,简单说NFA图小但要回溯,DFA不需要回溯但有些情况图会特别大。敬请期待我后续博文。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/161607.html原文链接:https://javaforall.net


