
大家好,又见面了,我是你们的朋友全栈君。
展开全部
Scanner是一个类,nextDouble()是Scanner的成员函数,System.in作为参数传递给Scanner的构造函数,使Scanner用62616964757a686964616fe78988e69d8331333366303839键盘作为输入,然后用new在内存中实例化一个Scanner出来,使得其它变量能调用这块内存区。
Scanner类简介:
Java 5添加了java.util.Scanner类,这是一个用于扫描输入文本的新的实用程序。它是以前的StringTokenizer和Matcher类之间的某种结合。
由于任何数据都必须通过同一模式的捕获组检索或通过使用一个索引来检索文本的各个部分。于是可以结合使用正则表达式和从输入流中检索特定类型数据项的方法。
这样,除了能使用正则表达式之外,Scanner类还可以任意地对字符串和基本类型(如int和double)的数据进行分析。借助于Scanner,可以针对任何要处理的文本内容编写自定义的语法分析器。
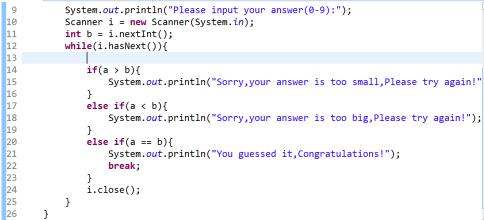

扩展资料
System.in作为InputStream类的对象实现标准输入,可以调用它的read方法来读取键盘数据。read方法如下:
int read()
从输入流中读取数据的下一个字节。
Java通过系统类System实现标准输入/输出的功能,定义了3个流变量:in,out,和err.这3个流在Java中都定义为静态变量,可以直接通过System类进行调用。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/162062.html原文链接:https://javaforall.net


