
大家好,又见面了,我是你们的朋友全栈君。
1.下载site-1.10.13-1.9.x
官方版:http://subclipse.tigris.org/files/documents/906/49486/site-1.10.13-1.9.x.zip (点击直接下载)
2.打开压缩包会发现目录结构如下:

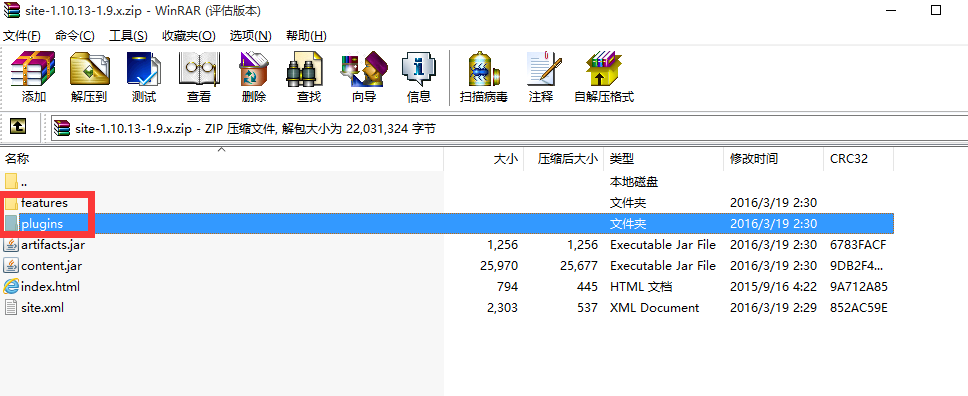
3.将features文件夹中的文件复制到Myeclipse安装目录中的features文件夹中,
将plugins文件夹中的文件复制到Myeclipse安装目录中的plugins文件夹中。
4.重启ME,打开Window–>Show View–>Other,就可以找到SVN插件了。
5 在之前导入到myeclipse中的项目, 这时还没显示版本信息, 操作一遍关闭项目,打开项目 close project, open project, 就会出现版本信息
引用 转发博客连接: https://blog.csdn.net/qq_39529566/article/details/81511910 ;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/162448.html原文链接:https://javaforall.net


