
大家好,又见面了,我是你们的朋友全栈君。
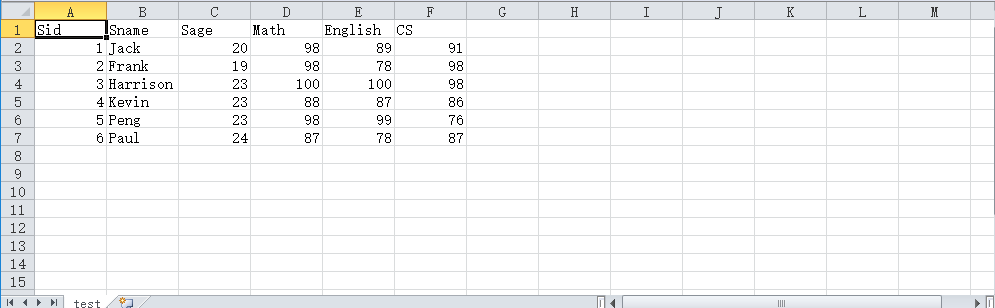
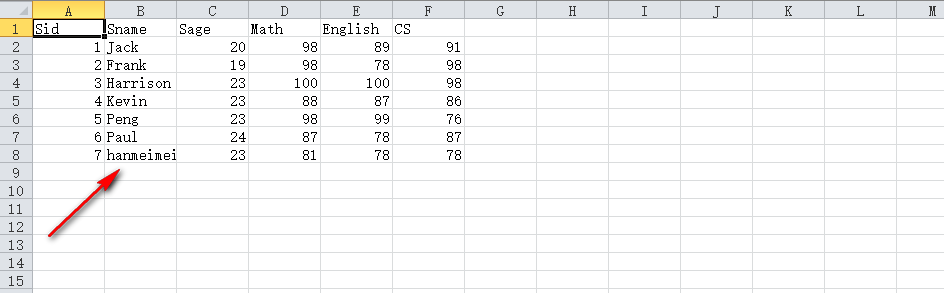
首先先简单说一下csv文件,csv的全称是Comma-Separated Values,意思是逗号分隔值,通俗点说就是一组用逗号分隔的数据。CSV文件可以用excel打开,会显示如下图所示:

这个文件用notepad打开显示是这样的,这是它原始的样子:

好了,下班我们来用python对csv文件进行读写操作
1.读文件
如何用Python像操作Excel一样提取其中的一列,即一个字段,利用Python自带的csv模块,有两种方法可以实现:
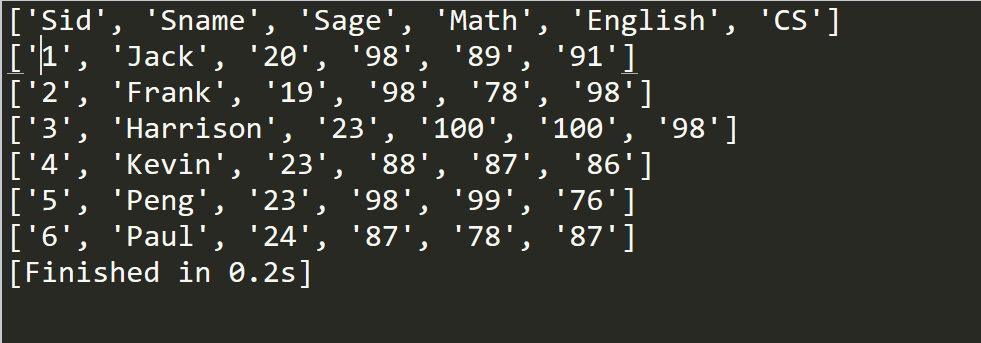
第一种方法使用reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:比如下面的代码可以读取csv的全部内容,以行为单位:
#-*-encoding:utf-8-*-
import csv
#读取csv文件
with open("C:\\Users\\A9050031\\Desktop\\test.csv", "r") as f:
reader = csv.reader(f)
for row in reader:
print(row)
可以得到如下所示结果:
使用这种方法读取某一列的数据必须指定列号,不能根据Sid、Sname这些属性来获取列信息。例子如下:

接下来说一下第二种方法,这种方法是使用csv的DictReader函数来进行数据的读取。
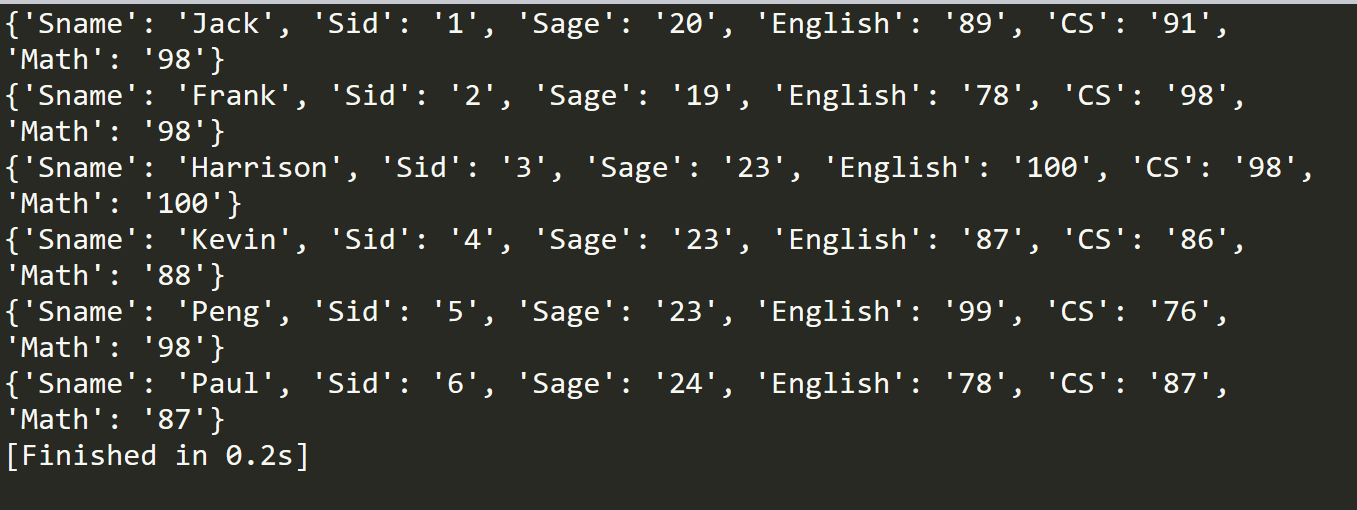
和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
#-*-encoding:utf-8-*-
import csv
#读取csv文件
with open("C:\\Users\\A9050031\\Desktop\\test.csv", "r") as f:
reader = csv.DictReader(f)
for row in reader:
print(row)
数据输出结果如下:
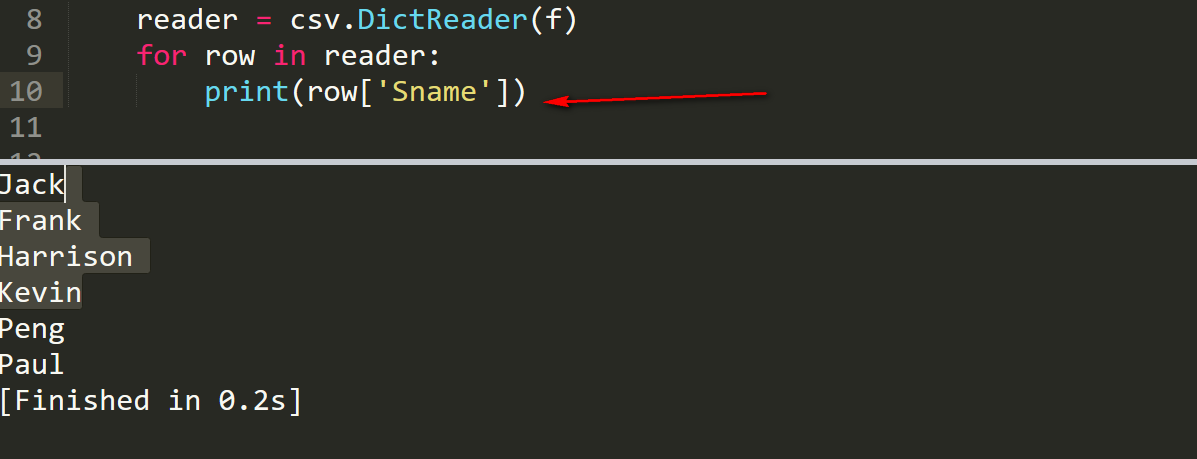
通过DictReader获取的数据可以通过每一列的标题来查询,示例如下所示:
2.写文件
写文件可以通过调用csv的writer函数来进行数据的写入,示例代码如下:
row = ['7', 'hanmeimei', '23', '81', '78', '78']
out = open("C:\\Users\\A9050031\\Desktop\\test.csv", "a")
csv_writer = csv.writer(out, dialect = "excel")
csv_writer.writerow(row)
结果如下图所示追加到了文件中
以上只是我浅显的学习,希望我们一起学习进步。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/162463.html原文链接:https://javaforall.net


