
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1、前言
最近在看《云数据中心网络技术》,学习了企业数据中心网络建设过程,看到有ToR和EoR两种布线方式,之前没有接触过,今天总结一下。
2、布线方式
ToR:(Top of Rack)接入方式就是在服务器机柜的最上面安装接入交换机。
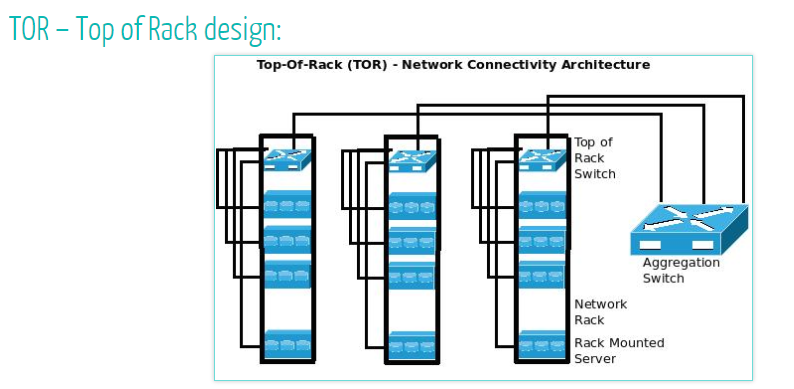

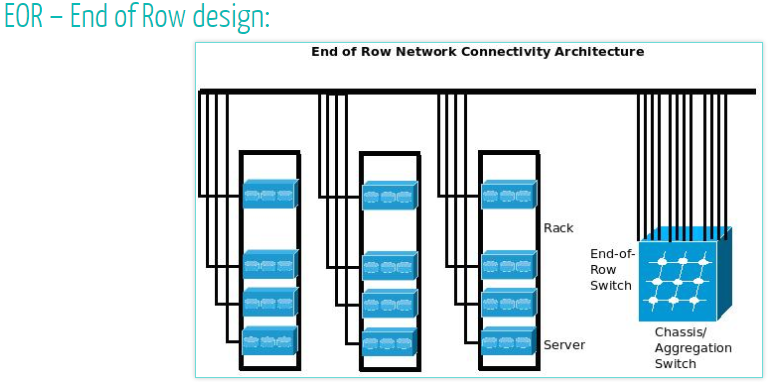
EoR:(End of Row)接入交换机集中安装在一列机柜端部的机柜内,通过水平缆线以永久链路方式连接设备柜内的主机/服务器/小型机设备。EoR 对设备机柜需要敷设大量的水平缆线连接到交换机。
3、对比
EOR布线方式的缺点:从服务器机柜到网络机柜的铜缆多(约有20-40根铜缆),且距网络机柜越远的服务器机柜的铜缆,在机房中的布线距离越长,由此导致线缆管理维护工作量大、灵活性差。
TOR布线的缺点:每个服务器机柜受电源输出功率限制,可部署的服务器数量有限,由此导致机柜内交换机的接入端口利用率不足。在几个服务器机柜间共用1-2台接入交换机,可解决交换机端口利用率不足的问题,但这种方式增加了线缆管理工作量。
从网络设计考虑,TOR布线方式的每台接入交换机上的VLAN量不会很多,在网络规划的时候也要尽量避免使一个VLAN通过汇聚交换机跨多台接入交换机,因此采用TOR布线方式的网络拓扑中,每个VLAN的范围不会太大,包含的端口数量不会太多。但对于EOR布线方式来说,接入交换机的端口密度高,在网路最初设计时,就可能存在包含较多端口数的VLAN。
TOR方式的接入交换机数量多,EOR方式的接入交换机数量少,所以TOR方式的网络设备管理维护工作量大
随着用户数据业务需求的猛增,数据中心机房服务器密度越来越高,虚拟化和云计算等新技术趋势日益流行,使得服务器对应的网络端口大大增加,并且增加了管理的复杂性,另外以太网(LAN)与光纤存储区域网络(SAN)的融合也越来越常见,这就必然要求一种新的网络拓扑结构与之相对应。在云计算的大潮下,这种分布式架构的业务扩展性极强,要求的服务器数量也越来越多。例如新的Apache Hadoop 0.23支持6000~10000台服务器在一个集群内,海量的服务器数量要求充分利用数据中心机柜空间的同时,海量的业务数据也需要更快更直接的高性能链路把数据传送到网络核心。在这样的趋势下,显然ToR更加适用,在业务迅速扩展的压力下,ToR的方式可以更好的实现网络的更快速扩展。
4、参考资料
http://blog.51cto.com/dannyswallow/1731777
Data Center Network – Top of Rack (TOR) vs End of Row (EOR) Design
http://blog.51cto.com/cteam/674194
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/166503.html原文链接:https://javaforall.net


