
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
以下为一个最简单的HTTP服务器,在浏览器中输入地址后,就能够访问到通目录下的HTML文件,
实现效果:



import socket
""" TCP 的服务端 1,socket 创建socket 2.bind 绑定IP和端口 3.listen 处于监听状态 4.accept 接进来客户端的连接 5.recv/send 接受或者发送信息 6.close 关闭 """
def tcp_creat_socket():
tcp_ser = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
return tcp_ser
def tcp_bind_listern_info(tcp_socket):
SER_IP = "127.0.0.1"
# SER_PORT = int(input("服务器绑定的端口:"))
SER_PORT = 7080
SER_INFO = (SER_IP, SER_PORT)
tcp_socket.bind(SER_INFO)
LISTEN_NUM = 10
tcp_socket.listen(LISTEN_NUM)
return SER_INFO
def tcp_accept(tcp_socket,ser_info):
# accept 1默认会阻塞,2并返回一个新的套接字用于和接进来的客户端进行数据传输,3并记录客户端的信息,为用户进行服务
print("服务器的IP:%s,端口:%d,正在等待新的客户端的到来" % (ser_info[0], ser_info[1]))
tcp_ser_new_socket, client_addr = tcp_socket.accept()
print("客户端已经到来,信息如下:%s" % str(client_addr))
return tcp_ser_new_socket
def tcp_recv_message(tcp_socket):
# recv 返回值为空时,则客户端调用了close
tcp_ser_recv_info = tcp_socket.recv(1024)
if "exit" == tcp_ser_recv_info or None == tcp_ser_recv_info:
print("recv_info error")
# GET / HTTP/1.1
# Host: www.baidu.com
# Connection: keep-alive
# sec-ch-ua: "Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"
# sec-ch-ua-mobile: ?0
print(">"*120)
print("服务端接收:%s" % tcp_ser_recv_info.decode("utf-8"))
def tcp_send_message(tcp_socket):
# send_info = str(input("输入服务端发送的信息:"))
header = "HTTP/1.1 200 OK\r\n" # 相应头部
respone = "\r\n" # 空行
http_headr = header + respone
f = open("./pass.html", "rb") # 二进制文件
html_file = f.read()
f.close()
http_body = html_file
tcp_socket.send(http_headr.encode("utf-8"))
tcp_socket.send(http_body)
tcp_socket.close()
def tcp_close(tcp_socket):
tcp_socket.close()
def CC_server():
# 创建
tcp_ser =tcp_creat_socket()
# bind and listen
ser_info = tcp_bind_listern_info(tcp_socket=tcp_ser)
while True: # 循环为多个客户端服务,一直处于监听状态
new_socket = tcp_accept(tcp_socket=tcp_ser, ser_info=ser_info)
while True: # 循环为同一个用户服务多次
# recv 返回值为空时,则客户端调用了close
tcp_recv_message(tcp_socket=new_socket)
# send
tcp_send_message(tcp_socket=new_socket)
break
# close 关闭发送数据的客户端的连接
tcp_close(tcp_socket=new_socket)
# close
tcp_close(tcp_socket=tcp_ser)
if __name__ == "__main__":
CC_server()
``
效果如下:

后面部分是扩展部分,能够实现从HTTP服务器的指定网页信息,在浏览器中需要加入需要获取的网页的名称
```python
import socket
import re
""" TCP 的服务端 1,socket 创建socket 2.bind 绑定IP和端口 3.listen 处于监听状态 4.accept 接进来客户端的连接 5.recv/send 接受或者发送信息 6.close 关闭 """
def tcp_creat_socket():
tcp_ser = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
return tcp_ser
def tcp_bind_listern_info(tcp_socket):
SER_IP = "127.0.0.1"
# SER_PORT = int(input("服务器绑定的端口:"))
SER_PORT = 7080
SER_INFO = (SER_IP, SER_PORT)
tcp_socket.bind(SER_INFO)
LISTEN_NUM = 10
tcp_socket.listen(LISTEN_NUM)
return SER_INFO
def tcp_accept(tcp_socket,ser_info):
# accept 1默认会阻塞,2并返回一个新的套接字用于和接进来的客户端进行数据传输,3并记录客户端的信息,为用户进行服务
print("服务器的IP:%s,端口:%d,正在等待新的客户端的到来" % (ser_info[0], ser_info[1]))
tcp_ser_new_socket, client_addr = tcp_socket.accept()
print("客户端已经到来,信息如下:%s" % str(client_addr))
return tcp_ser_new_socket
def tcp_recv_message(tcp_socket):
# recv 返回值为空时,则客户端调用了close
tcp_ser_recv_info = tcp_socket.recv(1024)
if "exit" == tcp_ser_recv_info or None == tcp_ser_recv_info:
print("recv_info error")
# GET / HTTP/1.1
# Host: www.baidu.com
# Connection: keep-alive
# sec-ch-ua: "Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"
# sec-ch-ua-mobile: ?0
print(">"*120)
print("服务端接收:%s" % tcp_ser_recv_info.decode("utf-8").splitlines()[0])
ret = re.match(r"[^/]+(/[^ ]*)", tcp_ser_recv_info.decode("utf-8").splitlines()[0])
if ret:
http_page_name = ret.group(1)
return http_page_name
def tcp_send_message(tcp_socket, page_name):
# send_info = str(input("输入服务端发送的信息:"))
if "/" == page_name:
page_name = "index" # 默认的页面
try:
f = open(f"./{
page_name}.html", "rb") # 二进制文件
html_file = f.read()
f.close()
except:
header = "HTTP/1.1 404 NOT FOUND\r\n" # 相应头部
respone = "\r\n" # 空行
http_headr = header + respone + f"{
page_name} not fount ,please again"
tcp_socket.send(http_headr.encode("utf-8"))
else:
header = "HTTP/1.1 200 OK\r\n" # 相应头部
respone = "\r\n" # 空行
http_headr = header + respone
http_body = html_file
tcp_socket.send(http_headr.encode("utf-8"))
tcp_socket.send(http_body)
tcp_socket.close()
def tcp_close(tcp_socket):
tcp_socket.close()
def CC_server():
# 创建
tcp_ser =tcp_creat_socket()
# bind and listen
ser_info = tcp_bind_listern_info(tcp_socket=tcp_ser)
while True: # 循环为多个客户端服务,一直处于监听状态
new_socket = tcp_accept(tcp_socket=tcp_ser, ser_info=ser_info)
while True: # 循环为同一个用户服务多次
# recv 返回值为空时,则客户端调用了close
page_name = tcp_recv_message(tcp_socket=new_socket)
# send
tcp_send_message(tcp_socket=new_socket, page_name=page_name)
break
# close 关闭发送数据的客户端的连接
tcp_close(tcp_socket=new_socket)
# close
tcp_close(tcp_socket=tcp_ser)
if __name__ == "__main__":
CC_server()
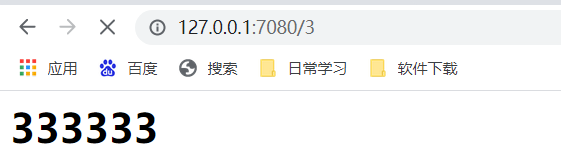
例如该PY文件下面存在一个3.html文件,只需要在浏览器中输入http://127.0.0.1:7080/3 就能够看到服务端返回的数据,并将html中的内容显示在浏览器上,
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/168451.html原文链接:https://javaforall.net


