
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
感知机
1. 感知机模型
定义:假设输入空间(特征空间)是 χ ⊆ R n \chi\subseteq R^n χ⊆Rn,输出空间是 Y = { + 1 , − 1 } Y=\{+1,-1\} Y={
+1,−1}。输入 x ∈ χ x\in \chi x∈χ表示实例的特征向量,对应于输入空间的点;输出 y ∈ Y y\in Y y∈Y表示实例的类别。由输入空间到输出空间的如下函数
f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w\cdot x+b) f(x)=sign(w⋅x+b)
称为感知机。其中, w w w和 b b b为感知机模型参数, w ∈ R n w\in R^n w∈Rn叫做权值, b ∈ R b\in R b∈R叫做偏置, w ⋅ x w\cdot x w⋅x表示 w w w和 x x x的内积。 s i g n sign sign为符号函数。
2. 感知机学习策略
2.1数据集的线性可分性定义:
给定一个数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } , T = \{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\}, T={
(x1,y1),(x2,y2),⋯,(xn,yn)},
其中, x i ∈ χ = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N , x_i\in\chi=R^n,y_i\in Y=\{+1,-1\},i=1,2,\cdots,N, xi∈χ=Rn,yi∈Y={
+1,−1},i=1,2,⋯,N,如果存在某个超平面S
w ⋅ x + b = 0 w\cdot x+b=0 w⋅x+b=0
能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有的 y i = + 1 y_i=+1 yi=+1的实例 i i i,有 w ⋅ x i + b > 0 w\cdot x_i+b>0 w⋅xi+b>0,对所有的 y i = − 1 y_i=-1 yi=−1的实例 i i i,有 w ⋅ x i + b < 0 , w\cdot x_i+b<0, w⋅xi+b<0,则成数据集 T T T为线性可分数据集;否则,成数据集 T T T为线性不可分。
2.2感知机学习策略的损失函数
感知机 s i g n ( w ⋅ x + b ) sign(w\cdot x+b) sign(w⋅x+b)学习的损失函数定义为
L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum_{x_i\in M}y_i(w\cdot x_i+b) L(w,b)=−xi∈M∑yi(w⋅xi+b)
其中, M M M为误分类点的集合。这个损失函数就是感知机学习的经验风险函数。损失函数 L ( w , b ) L(w,b) L(w,b)是 w w w, b b b的连续可导函数。
3. 感知机学习算法
3.1 算法(感知机学习算法的原始形式)
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={
(x1,y1),(x2,y2),⋯,(xN,yN)},其中 x i ∈ χ = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N x_i \in\chi=R^n,y_i\in Y=\{+1,-1\},i=1,2,\cdots,N xi∈χ=Rn,yi∈Y={
+1,−1},i=1,2,⋯,N;学习率 η ( 0 < η ≤ 1 ) ; \eta(0<\eta\le1); η(0<η≤1);
输出: w , b w,b w,b;感知机模型 f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w\cdot x+b) f(x)=sign(w⋅x+b).
(1)选取初值 w 0 , b 0 w_0,b_0 w0,b0
(2)在训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
(3)如果 y i ( w ⋅ x i + b ) ≤ 0 y_i(w\cdot x_i +b)\le 0 yi(w⋅xi+b)≤0
w ← w + η y i x i b ← b + η y i w\leftarrow w +\eta y_ix_i\\ b\leftarrow b +\eta y_i w←w+ηyixib←b+ηyi
(4)转至(2),直至训练集中没有误分类点。
3.2 R语言实现(感知机学习算法的原始形式)
percept <- function(data = data,eta = eta ){
x <- data[,-dim(data)[2]]
y <- data[,dim(data)[2]]
w <- c(0,0)
b <- 0
len <- length(y)
i <- 1
while(i <= len){
if(y[i] * (x[i,] %*% w + b) <= 0){
## update w and b
w <- w + eta * y[i] * x[i,]
b <- b + eta * y[i]
i <- 1 ##important, for traversing every point
}
else{
i <- i + 1
}
}
return(list(w=w,b=b))
}
data <- matrix(c(3,3,1,4,3,1,1,1,-1),nr=3,byrow=T)
percept(data = data,eta = 1)
最终结果为
$w
[1] 1 1
$b
[1] -3
再换一个数据:
dat <-matrix(c(1,1,-1,.5,.5,-1,4,1,1,3,2,1,1.5,1,-1,2,3,1,4,3,1,2,3.5,1),nc=3,byrow=T)
perceptron <- percept(data=dat,eta=1)
perceptron
最后结果为:
$w
[1] 4 0
$b
[1] -7
我们试着画出它的图形
dat1 <- dat[,1:2]
dat1 <- as.data.frame(dat1)
names(dat1) <- c("x1","x2")
plot(x2~x1,data=dat1,col=ifelse(4*x1-7<=0,"red","blue"),pch=17,bty="l")
abline(v=7/4,lwd=2,lty=2,col="red")
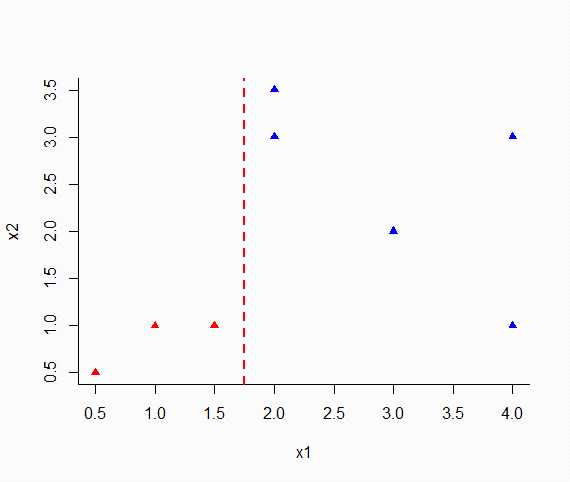

由此可以看出还是不错的,都已经正确划分。
3.3算法(感知机学习算法的对偶形式)
输入:线性可分的数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } , T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\}, T={
(x1,y1),(x2,y2),⋯,(xN,yN)},其中 x i ∈ R n , y i ∈ { + 1 , − 1 } , i = 1 , 2 , ⋯ , N ; x_i\in R^n,y_i \in \{+1,-1\},i=1,2,\cdots,N; xi∈Rn,yi∈{
+1,−1},i=1,2,⋯,N;学习率 η ( 0 < η ≤ 1 ) ; \eta(0<\eta\le1); η(0<η≤1);
输出: α , b ; \alpha,b; α,b;感知机模型 f ( x ) = s i g n ( ∑ j = 1 N α j y j x j ⋅ x + b ) . f(x)=sign(\sum_{j=1}^N\alpha_jy_jx_j\cdot x+b). f(x)=sign(∑j=1Nαjyjxj⋅x+b).
其中 α = ( α 1 , α 2 , ⋯ , α N ) T . \alpha=(\alpha_1,\alpha_2,\cdots,\alpha_N)^T. α=(α1,α2,⋯,αN)T.
(1) α ← 0 , b ← 0 \alpha\leftarrow 0,b\leftarrow0 α←0,b←0
(2)在训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
(3)如果 y i ( ∑ j = 1 N α j y j x j ⋅ x i + b ) ≤ 0 y_i(\sum_{j=1}^N\alpha_jy_jx_j\cdot x_i +b)\le0 yi(∑j=1Nαjyjxj⋅xi+b)≤0
α i ← α i + η b ← b + η y i \alpha_i\leftarrow \alpha_i +\eta\\ b\leftarrow b+\eta y_i αi←αi+ηb←b+ηyi
(4)转至(2)直到没有误分类数据。
对偶形式训练实例仅以内积的形式实现,为了方便,可以预先将训练集中的实例间的内积计算出来并以矩阵形式存储,这个矩阵就是所谓的Gram矩阵
G = [ x i ⋅ x j ] N × N G=[x_i\cdot x_j]_{N\times N} G=[xi⋅xj]N×N
3.4 R语言实现(感知机学习算法的对偶形式)
后续补充
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/179091.html原文链接:https://javaforall.net


