
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
感知机由Rosenblatt于1957年提出,是神经网络和支持向量机的基础。这里先简单介绍一下什么是感知机。本篇博客为《统计学方法》第二章和博客《感知机原理小结》的总结。
感知机模型
感知机是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,分别取 +1 + 1 和 −1 − 1 二值。感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。这还是很容易理解的,以二维平面为例,假设平面中存在着 ′∘′ ′ ∘ ′ 和 ′×′ ′ × ′ 两种形状的点,感知机要做的是就是找到一条直线,将两类点分割开,如下图所示。这里要注意的是,感知机只适合于线性可分的数据,所以它是一个线性模型。
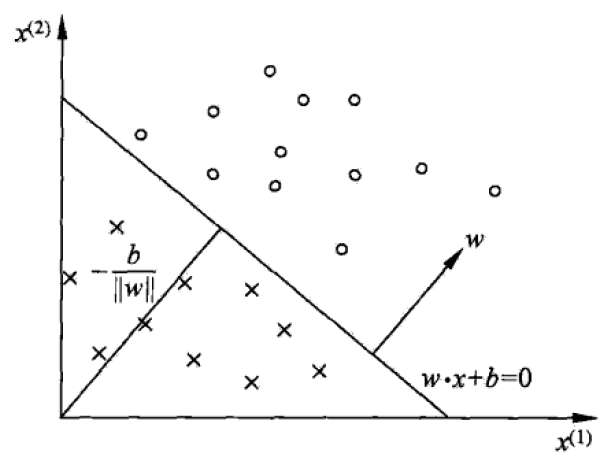

假设现在我们训练集有 m m 个样本,每个样本对应于
n
维特征和一个二元类别输出:
我们现在的目标就是找到一个超平面
S S
(为了表达简洁,后面都用向量形式了):
w⋅x+b=0
其中
w w
是超平面的法向量,
b
是超平面的截距,这个超平面将特征空间划分为两个部分:
对于
y(i)=−1 y ( i ) = − 1
的样本,
w⋅x(i)+b<0 w ⋅ x ( i ) + b < 0
;
对于
y(i)=+1 y ( i ) = + 1
的样本,
w⋅x(i)+b>0 w ⋅ x ( i ) + b > 0
。
从而实现分类的目的。这就是感知机模型,可以表示为从输入空间到输出空间的函数:
其中权值
w∈Rn w ∈ R n
和偏置
b∈R b ∈ R
是感知机模型参数,比如二维平面中
w w
就是一个二维向量。
是符号函数,即
+1,−1,x≥0x<0 s i g n ( x ) = { + 1 , x ≥ 0 − 1 , x < 0
一旦学习到了
w w
和
的值,我们就可以利用
f(x(i)) f ( x ( i ) )
来判断新的样本属于哪一类别。
感知机学习策略
感知机学习的目标是求得一个能够将训练集正类和负类样本点完全正确分开的分离超平面。为了确定超平面的参数 w w 和
,我们需要定义损失函数并将损失函数最小化。
我们自然而然能想到的一个选择是最小化误分类点的总数,即 0−1 0 − 1 损失,但这样的损失函数不是参数 w,b w , b 的连续可导函数,难以优化。另一个选择是最小化误分类点到超平面 S S 的总距离,这正是感知机所采用的。
先回顾一下空间任一点
到平面 w⋅x+b w ⋅ x + b 的距离公式:
然后对于误分类的数据点 (x(i),y(i)) ( x ( i ) , y ( i ) ) ,总是满足 y(i)f(x(i))<0 y ( i ) f ( x ( i ) ) < 0 ,所以误分类点到超平面S的距离为:
记误分类点的集合为 M M ,那么所有误分类点到超平面
的总距离为:
由于我们总能通过缩放 w,b w , b 使得在不改变超平面的的情况下使 ∥w∥2=1 ‖ w ‖ 2 = 1 ,为了简化损失函数,我们不妨令 ∥w∥2=1 ‖ w ‖ 2 = 1 ,于是得到了感知机的损失函数最终形式如下:
这个损失函数就是感知机学习的经验风险函数,显然 L(w,b) L ( w , b ) 是非负的,如果没有误分类点,损失函数值为0。误分类点越少,误分类点距离超平面越近,损失函数值就越小。
最后一句话总结,感知机学习的策略是在假设空间中选取使损失函数式(1)最小的模型参数 w,b w , b ,即感知机模型。
感知机学习算法
感知机学习问题就是损失函数式(1)的最优化问题,可以用随机梯度下降求解。下面介绍一下感知机学习算法的原始形式和对偶形式。
原始形式
给定训练集 T T ,感知机学习的目标是:
其中 M M 是训练集中误分类点的集合。感知机学习算法是误分类驱动的,具体采用SGD,首先随机选取一个超平面
,然后每次随机选取一个误分类点进行梯度下降。
损失函数的梯度由
给出。然后每轮迭代选取一个误分类点 (x(i),y(i)) ( x ( i ) , y ( i ) ) 对 w,b w , b 进行更新:
其中 η η 为学习率。整个过程直观的解释是,每次遇到误分类点就调整 w,b w , b ,使超平面向误分类点的一侧移动,以减小改误分类点与超平面间的距离,直到超平面越过该点使其被正确分类。感知机学习算法存在许多解,这不仅依赖于 w,b w , b 初始值的选择,也依赖于误分类点的选择顺序。为了得到唯一的超平面,需要对分离超平面增加约束条件,这就是线性支持向量机的思想。
最后提一下感知机的两点性质:
(1) 当数据集线性可分的时候,学习算法一定收敛,即可以找到一个将数据点完全正确分开的超平面,而且误分类的次数是有上界的,即经过有限次的搜索一定可以找到最优分离超平面;
(2) 当数据集不是线性可分的时候,学习算法不收敛,可能会发生震荡。
对偶形式
这里顺便解释一下什么是对偶。对偶就是从一个不同的角度去解答相似问题,但是问题的解是相通的,甚至是一样一样的。那为什么感知机已经有原始形式了还要特地提出一个对偶形式?吃饱了撑着?不,这里引入对偶主要是为了减小计算量(特征维度越高越明显),至于为什么能减少计算量,等推导完对偶形式就自然而然出来了。
感知机对偶形式的基本思路是,将 w w 和
表示为样本 x(i) x ( i ) 标记 y(i) y ( i ) 的线性组合的形式,这样就可以通过求解其系数而求得 w w 和
。
不失一般性,我们可以假设初始值 w0,b0 w 0 , b 0 均为0,然后使用式(2)逐步调整 w,b w , b ,设现在迭代 n n 次,
关于 (x(i),y(i)) ( x ( i ) , y ( i ) ) 的增量分别是 αiy(i)x(i) α i y ( i ) x ( i ) 和 αiy(i) α i y ( i ) ,最后学习到的 w,b w , b 可以分别表示为:
这里 αi=niη α i = n i η , ni n i 表示到目前为止第 i i 个样本点由于误分类而进行更新的次数,即一开始每个样本的
,每次当这个样本误分类进行一次梯度下降更新时, ni n i 就加1。样本点更新次数越多,意味着它距离分离超平面就越近,也就越难正确分类。换句话说,这样的样本点对学习结果影响最大。
然后,每次判断误分类点时,判断条件 y(i)(w⋅x(i)+b)≤0 y ( i ) ( w ⋅ x ( i ) + b ) ≤ 0 就变成了 y(i)(∑nj=1αiy(j)x(j)⋅x(i)+b)≤0 y ( i ) ( ∑ j = 1 n α i y ( j ) x ( j ) ⋅ x ( i ) + b ) ≤ 0 。这种形式有一个好处,就是在训练过程中,训练样本仅以内积 x(j)⋅x(i) x ( j ) ⋅ x ( i ) 的形式出现。我们可以预先将样本内积算出来并以矩阵的形式存储,在后面的迭代过程中这个结果将会被重复利用。这个样本内积矩阵也就是所谓的Gram矩阵:
现在来分析一下对偶为什么比原始形式好。
(1) 第一个原因在上面提到了,就是计算量小。我们在每次迭代过程中都必须判断各个样本点是否误分类,在原始形式中我们利用 y(i)(w⋅x(i)+b)≤0 y ( i ) ( w ⋅ x ( i ) + b ) ≤ 0 判断,因为每次 w w 都有变化,所以每次都需要计算特征向量
和 w w 的乘积。在对偶形式中我们利用
来判断,这里索引Gram矩阵就能得到样本内积 x(j)⋅x(i) x ( j ) ⋅ x ( i ) ,且Gram矩阵可以预先计算好,之后迭代中的计算就全部可以通过查表的方式得到了,这相比原始形式每次迭代都需要计算 w⋅x(i) w ⋅ x ( i ) ,减少了大量的计算时间。
(2) 内积形式很方便我们引入支持向量机的核方法,用来解决数据集线性不可分时的情况。
最后总结一下感知机的对偶形式,它本质上就是用样本 x(i) x ( i ) 标记 y(i) y ( i ) 的线性组合去表达原始形式中的 w,b w , b ,如式(3)所示。这种形式的表达可以引入样本内积,减少计算量。然后对偶形式中要更新的模型参数就只有一个 αi=ηni α i = η n i 了,我们每次用一个误分类样本 x(i) x ( i ) 对参数进行更新,只需要将相应的 ni n i 加1,即
这就是对偶形式的参数更新规则,和原始的随机初始化参数不同, αi α i 被初始化为0(因为 ni n i 一开始都为0)。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/184355.html原文链接:https://javaforall.net


