
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
最近新的项目写了不少各种 insertBatch 的代码,一直有人说,批量插入比循环插入效率高很多,那本文就来实验一下,到底是不是真的?
测试环境:
- SpringBoot 2.5
- Mysql 8
- JDK 8
- Docker
首先,多条数据的插入,可选的方案:
foreach循环插入- 拼接
sql,一次执行 - 使用批处理功能插入
搭建测试环境`
sql文件:
drop database IF EXISTS test;
CREATE DATABASE test;
use test;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT "",
`age` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
复制代码应用的配置文件:
server:
port: 8081
spring:
#数据库连接配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&&serverTimezone=UTC&setUnicode=true&characterEncoding=utf8&&nullCatalogMeansCurrent=true&&autoReconnect=true&&allowMultiQueries=true
username: root
password: 123456
#mybatis的相关配置
mybatis:
#mapper配置文件
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.aphysia.spingbootdemo.model
#开启驼峰命名
configuration:
map-underscore-to-camel-case: true
logging:
level:
root: error
复制代码启动文件,配置了Mapper文件扫描的路径:
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.aphysia.springdemo.mapper")
public class SpringdemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringdemoApplication.class, args);
}
}
复制代码Mapper文件一共准备了几个方法,插入单个对象,删除所有对象,拼接插入多个对象:
import com.aphysia.springdemo.model.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserMapper {
int insertUser(User user);
int deleteAllUsers();
int insertBatch(@Param("users") List<User>users);
}
复制代码Mapper.xml文件如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.aphysia.springdemo.mapper.UserMapper">
<insert id="insertUser" parameterType="com.aphysia.springdemo.model.User">
insert into user(id,age) values(#{id},#{age})
</insert>
<delete id="deleteAllUsers">
delete from user where id>0;
</delete>
<insert id="insertBatch" parameterType="java.util.List">
insert into user(id,age) VALUES
<foreach collection="users" item="model" index="index" separator=",">
(#{model.id}, #{model.age})
</foreach>
</insert>
</mapper>
复制代码测试的时候,每次操作我们都删除掉所有的数据,保证测试的客观,不受之前的数据影响。
不同的测试
1. foreach 插入
先获取列表,然后每一条数据都执行一次数据库操作,插入数据:
@SpringBootTest
@MapperScan("com.aphysia.springdemo.mapper")
class SpringdemoApplicationTests {
@Autowired
SqlSessionFactory sqlSessionFactory;
@Resource
UserMapper userMapper;
static int num = 100000;
static int id = 1;
@Test
void insertForEachTest() {
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
for (int i = 0; i < users.size(); i++) {
userMapper.insertUser(users.get(i));
}
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
}
复制代码2. 拼接sql插入
其实就是用以下的方式插入数据:
INSERT INTO `user` (`id`, `age`)
VALUES (1, 11),
(2, 12),
(3, 13),
(4, 14),
(5, 15);
复制代码 @Test
void insertSplicingTest() {
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
userMapper.insertBatch(users);
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
复制代码3. 使用Batch批量插入
将MyBatis session 的 executor type 设为 Batch ,使用sqlSessionFactory将执行方式置为批量,自动提交置为false,全部插入之后,再一次性提交:
@Test
public void insertBatch(){
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
for(int i=0;i<users.size();i++){
mapper.insertUser(users.get(i));
}
sqlSession.commit();
sqlSession.close();
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
复制代码4. 批量处理+分批提交
在批处理的基础上,每1000条数据,先提交一下,也就是分批提交。
@Test
public void insertBatchForEachTest(){
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = getRandomUsers();
long start = System.currentTimeMillis();
for(int i=0;i<users.size();i++){
mapper.insertUser(users.get(i));
if (i % 1000 == 0 || i == num - 1) {
sqlSession.commit();
sqlSession.clearCache();
}
}
sqlSession.close();
long end = System.currentTimeMillis();
System.out.println("time:" + (end - start));
}
复制代码初次结果,明显不对?
运行上面的代码,我们可以得到下面的结果,for循环插入的效率确实很差,拼接的sql效率相对高一点,看到有些资料说拼接sql可能会被mysql限制,但是我执行到1000w的时候,才看到堆内存溢出。
下面是不正确的结果!!!
| 插入方式 | 10 | 100 | 1000 | 1w | 10w | 100w | 1000w |
|---|---|---|---|---|---|---|---|
| for循环插入 | 387 | 1150 | 7907 | 70026 | 635984 | 太久了… | 太久了… |
| 拼接sql插入 | 308 | 320 | 392 | 838 | 3156 | 24948 | OutOfMemoryError: 堆内存溢出 |
| 批处理 | 392 | 917 | 5442 | 51647 | 470666 | 太久了… | 太久了… |
| 批处理 + 分批提交 | 359 | 893 | 5275 | 50270 | 472462 | 太久了… | 太久了… |
拼接sql并没有超过内存
我们看一下mysql的限制:
mysql> show VARIABLES like '%max_allowed_packet%';
+---------------------------+------------+
| Variable_name | Value |
+---------------------------+------------+
| max_allowed_packet | 67108864 |
| mysqlx_max_allowed_packet | 67108864 |
| slave_max_allowed_packet | 1073741824 |
+---------------------------+------------+
3 rows in set (0.12 sec)
复制代码这67108864足足600多M,太大了,怪不得不会报错,那我们去改改一下它吧,改完重新测试:
- 首先在启动
mysql的情况下,进入容器内,也可以直接在Docker桌面版直接点Cli图标进入:
docker exec -it mysql bash
复制代码- 进入
/etc/mysql目录,去修改my.cnf文件:
cd /etc/mysql
复制代码- 先按照
vim,要不编辑不了文件:
apt-get update
apt-get install vim
复制代码- 修改
my.cnf
vim my.cnf
复制代码- 在最后一行添加
max_allowed_packet=20M(按i编辑,编辑完按esc,输入:wq退出)
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
secure-file-priv= NULL
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Custom config should go here
!includedir /etc/mysql/conf.d/
max_allowed_packet=2M
复制代码- 退出容器
# exit
复制代码- 查看
mysql容器id
docker ps -a
复制代码

- 重启
mysql
docker restart c178e8998e68
复制代码重启成功后查看最大的max_allowed_pactet,发现已经修改成功:
mysql> show VARIABLES like '%max_allowed_packet%';
+---------------------------+------------+
| Variable_name | Value |
+---------------------------+------------+
| max_allowed_packet | 2097152 |
| mysqlx_max_allowed_packet | 67108864 |
| slave_max_allowed_packet | 1073741824 |
+---------------------------+------------+
复制代码我们再次执行拼接sql,发现100w的时候,sql就达到了3.6M左右,超过了我们设置的2M,成功的演示抛出了错误:
org.springframework.dao.TransientDataAccessResourceException:
### Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (36,788,583 > 2,097,152). You can change this value on the server by setting the 'max_allowed_packet' variable.
; Packet for query is too large (36,788,583 > 2,097,152). You can change this value on the server by setting the 'max_allowed_packet' variable.; nested exception is com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (36,788,583 > 2,097,152). You can change this value on the server by setting the 'max_allowed_packet' variable.
复制代码批量处理为什么这么慢?
但是,仔细一看就会发现,上面的方式,怎么批处理的时候,并没有展示出优势了,和for循环没有什么区别?这是对的么?
这肯定是不对的,从官方文档中,我们可以看到它会批量更新,不会每次去创建预处理语句,理论是更快的。
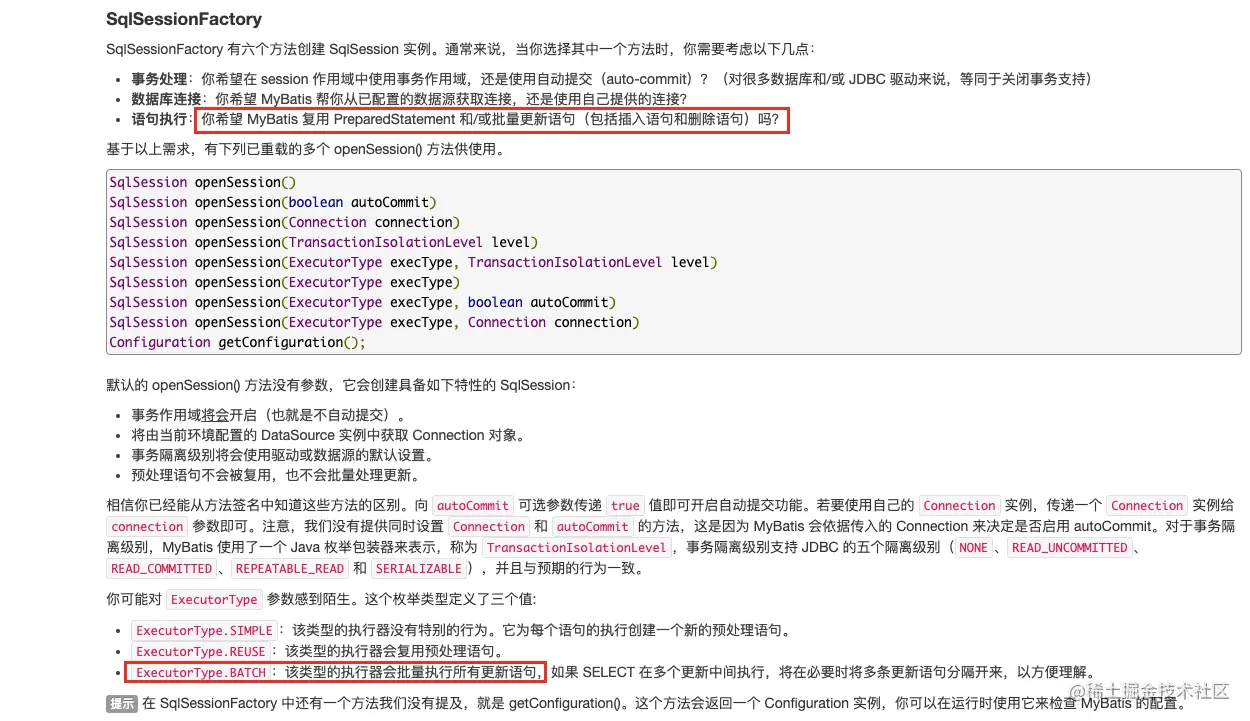
然后我发现我的一个最重要的问题:数据库连接 URL 地址少了rewriteBatchedStatements=true
如果我们不写,MySQL JDBC 驱动在默认情况下会忽视 executeBatch() 语句,我们期望批量执行的一组 sql 语句拆散,但是执行的时候是一条一条地发给 MySQL 数据库,实际上是单条插入,直接造成较低的性能。我说怎么性能和循环去插入数据差不多。
只有将 rewriteBatchedStatements 参数置为 true, 数据库驱动才会帮我们批量执行 SQL。
正确的数据库连接:
jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&&serverTimezone=UTC&setUnicode=true&characterEncoding=utf8&&nullCatalogMeansCurrent=true&&autoReconnect=true&&allowMultiQueries=true&&&rewriteBatchedStatements=true
复制代码找到问题之后,我们重新测试批量测试,最终的结果如下:
| 插入方式 | 10 | 100 | 1000 | 1w | 10w | 100w | 1000w |
|---|---|---|---|---|---|---|---|
| for循环插入 | 387 | 1150 | 7907 | 70026 | 635984 | 太久了… | 太久了… |
| 拼接sql插入 | 308 | 320 | 392 | 838 | 3156 | 24948(很可能超过sql长度限制) | OutOfMemoryError: 堆内存溢出 |
| 批处理(重点) | 333 | 323 | 362 | 636 | 1638 | 8978 | OutOfMemoryError: 堆内存溢出 |
| 批处理 + 分批提交 | 359 | 313 | 394 | 630 | 2907 | 18631 | OutOfMemoryError: 堆内存溢出 |
从上面的结果来看,确实批处理是要快很多的,当数量级太大的时候,其实都会超过内存溢出的,批处理加上分批提交并没有变快,和批处理差不多,反而变慢了,提交太多次了,拼接sql的方案在数量比较少的时候其实和批处理相差不大,最差的方案就是for循环插入数据,这真的特别的耗时。100条的时候就已经需要1s了,不能选择这种方案。
作者:秦怀杂货店
链接:https://juejin.cn/post/7049143701590769678
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/185386.html原文链接:https://javaforall.net


