
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
参考文章 http://iaman.actor/blog/2016/04/17/copy-in-python


**首先直接上结论: —–我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
—–而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。**
对于简单的 object,用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
看不懂文字没关系我们来看代码:
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2可以看到 cop1,也就是 shallow copy 跟着 origin 改变了。而 cop2 ,也就是 deep copy 并没有变。
似乎 deep copy 更加符合我们对「复制」的直觉定义: 一旦复制出来了,就应该是独立的了。如果我们想要的是一个字面意义的「copy」,那就直接用 deep_copy 即可。
那么为什么会有 shallow copy 这样的「假」 copy 存在呢? 这就是有意思的地方了。
python的数据存储方式
Python 存储变量的方法跟其他 OOP 语言不同。它与其说是把值赋给变量,不如说是给变量建立了一个到具体值的 reference。
当在 Python 中 a = something 应该理解为给 something 贴上了一个标签 a。当再赋值给 a 的时候,就好象把 a 这个标签从原来的 something 上拿下来,贴到其他对象上,建立新的 reference。 这就解释了一些 Python 中可能遇到的诡异情况:
>> a = [1, 2, 3]
>>> b = a
>>> a = [4, 5, 6] //赋新的值给 a
>>> a
[4, 5, 6]
>>> b
[1, 2, 3]
# a 的值改变后,b 并没有随着 a 变
>>> a = [1, 2, 3]
>>> b = a
>>> a[0], a[1], a[2] = 4, 5, 6 //改变原来 list 中的元素
>>> a
[4, 5, 6]
>>> b
[4, 5, 6]
# a 的值改变后,b 随着 a 变了上面两段代码中,a 的值都发生了变化。区别在于,第一段代码中是直接赋给了 a 新的值(从 [1, 2, 3] 变为 [4, 5, 6]);而第二段则是把 list 中每个元素分别改变。
而对 b 的影响则是不同的,一个没有让 b 的值发生改变,另一个变了。怎么用上边的道理来解释这个诡异的不同呢?
首次把 [1, 2, 3] 看成一个物品。a = [1, 2, 3] 就相当于给这个物品上贴上 a 这个标签。而 b = a 就是给这个物品又贴上了一个 b 的标签。
第一种情况:
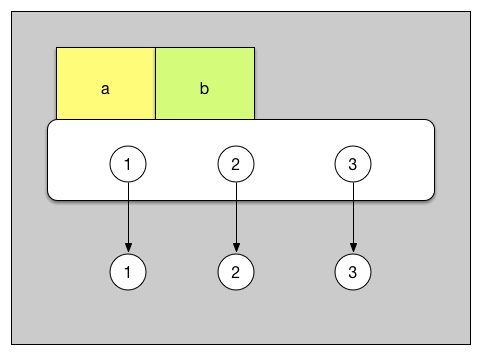
a = [4, 5, 6] 就相当于把 a 标签从 [1 ,2, 3] 上撕下来,贴到了 [4, 5, 6] 上。
在这个过程中,[1, 2, 3] 这个物品并没有消失。 b 自始至终都好好的贴在 [1, 2, 3] 上,既然这个 reference 也没有改变过。 b 的值自然不变。
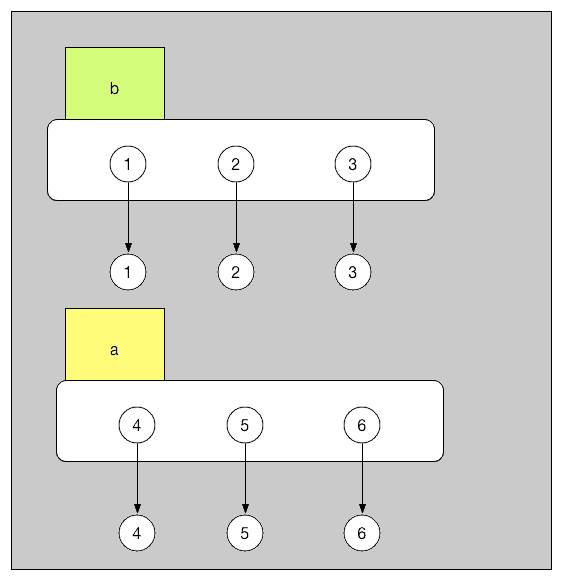
第二种情况:
a[0], a[1], a[2] = 4, 5, 6 则是直接改变了 [1, 2, 3] 这个物品本身。把它内部的每一部分都重新改装了一下。内部改装完毕后,[1, 2, 3] 本身变成了 [4, 5, 6]。
而在此过程当中,a 和 b 都没有动,他们还贴在那个物品上。因此自然 a b 的值都变成了 [4, 5, 6]。
搞明白这个之后就要问了,对于一个复杂对象的浅copy,在copy的时候到底发生了什么?
再看一段代码:
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2学过docker的人应该对镜像这个概念不陌生,我们可以把镜像的概念套用在copy上面。
概念图如下:

copy对于一个复杂对象的子对象并不会完全复制,什么是复杂对象的子对象呢?就比如序列里的嵌套序列,字典里的嵌套序列等都是复杂对象的子对象。对于子对象,python会把它当作一个公共镜像存储起来,所有对他的复制都被当成一个引用,所以说当其中一个引用将镜像改变了之后另一个引用使用镜像的时候镜像已经被改变了。
所以说看这里的origin[2],也就是 [3, 4] 这个 list。根据 shallow copy 的定义,在 cop1[2] 指向的是同一个 list [3, 4]。那么,如果这里我们改变了这个 list,就会导致 origin 和 cop1 同时改变。这就是为什么上边 origin[2][0] = “hey!” 之后,cop1 也随之变成了 [1, 2, [‘hey!’, 4]]。
而deepcopy概念图如下:
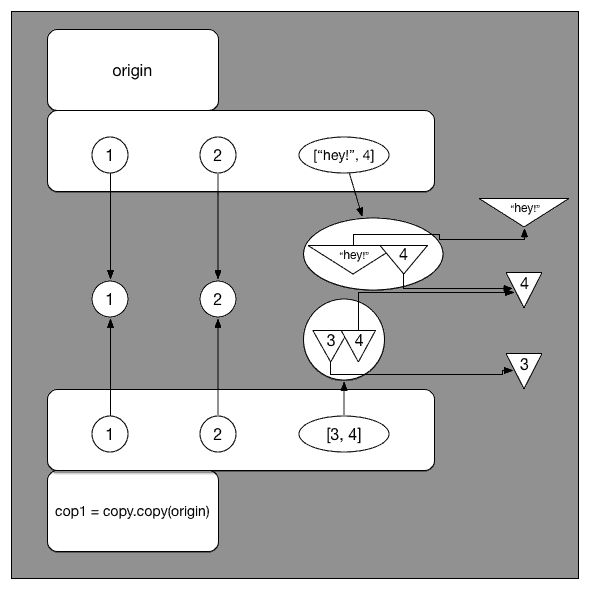
deepcopy的时候会将复杂对象的每一层复制一个单独的个体出来。
这时候的 origin[2] 和 cop2[2] 虽然值都等于 [3, 4],但已经不是同一个 list了。即我们寻常意义上的复制。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/186550.html原文链接:https://javaforall.net


