
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、什么是时间轮?
作为一个粗人,咱不扯什么高级的词汇,直接上图:


上面是一张时间轮的示意图,可以看到,这个时间轮就像一个钟表一样,它有刻度,图中画了9个格子,每个格子表示时间精度,比如每个格子表示1s,那么转一圈就是9s,
对于钟表上的秒针来说它的最小刻度是1s,秒针转一圈就是60s。时间轮上每个格子储存了一个双向链表,用于记录定时任务,当指针转到对应的格子的时候,会检查对应的任务
是否到期,如果到期就会执行链条上的任务。
二、为什么使用时间轮?
我认为这个世界上任何事物的出现都有它的原因,只是大部分事物我们都无法找到它的原因而已,好在技术的出现是有一定规律的,要么是性能上的提高,要么就是易用性,时间
轮也不例外。假设给你一批任务,每个任务都有它的执行时间点,时间精确到秒,你会怎么去实现它?
-
启动一个线程,每秒轮询每个任务,用当前时间与任务的年,月,日,时,分,秒匹配,能匹配的扔到线程池中执行
- 优点:实现简单
- 缺点:每秒都要遍历所有的任务,对每个任务做匹配,对于很多还没有到时间的任务,做了无用功,当数据量大的时候会导致任务执行延时,对于这种情况也可以考虑多个
轮询线程分批执行的方案
-
根据执行时间采用小顶堆的排序算法
- 优点:无需轮询每个任务,只要取出第一个节点判断是否到期即可,如果时间未到期,线程wait
- 缺点:数据量大的时候,插入到一个已经排好序的小顶堆,时间复杂度为O(lgn),当然也还好,即使是2的30次方个数据,也就是30次,但是有一个与第一种方法相同的问题,那就是任务可能会导致延时,这种也可以通过分批来做优化。
上面的两种方式都有一个共同点,就是对任务没有分组,那我们给他们分个组,比如任务
里面有一个延时最大的任务的执行时间是100s,那么我们可以创建一个长度为100的数组,相同时间执行的任务放在一起,变成下面这样

可以看到这个数组被分成了100个格子,每个格子表示1s,相同执行时间的任务被放在了一起,组成了一个链表,此时启动一个每秒执行的线程,每秒走一个格子,如果格子里有
任务那么扔到线程池中执行。那如果我最大的延时任务是上万秒以后,那是不是就得创建一个上万长度的数组啊?是的,这样的话就会导致一些问题,如果中间好多格子都没有
任务,着实挺浪费空间的,那么怎么改进呢?这个时候时间轮就呼之欲出了,下面就是时间轮的表演时间了
我们固定数组的长度为60个格子,每个格子的精度为1s,那么一圈就是60s,如果我有3个任务A、B、C,他们相对于启动轮询线程开始走第一个格子的时间差分
别为3s,50s,55s,那么其对应的格子为

轮询线程只要走到对应A、B、C的格子就可以执行它们了,但是如果我有一个一万秒之后执行的任务D,该怎么办呢?首先我们可以计算下走一万秒,轮询线程需要走166圈,还余
40s,那么这个任务我们可以增加额外的属性用于记录圈数,任务存放在第40个格子上

也就是说我这个轮询线程从第一个格子到达最后一个格子,再从第一个格子再到最后一个格子,周而复始,只要在第40个格子上遇见D任务167次就可以执行这个任务了。
看起来挺完美的,但是由于精度小,格子固定,当任务非常多的时候,每个格子上的链表将会变得很长,任务的执行将可能会延时,那怎么办?我们都知道,我们的钟表,除了
秒针之外,还有分针,时针。那么我们能不能再定义一个精度不同的时间轮呢?当然是可以的,假设我有一个任务E是在某点某分某秒执行,那么我们可以定义三个时间轮,
分别是秒时间轮,分时间轮,小时时间轮
秒时间轮:总共60个格子,每格1s
分时间轮:总共60个格子,每格1分钟
时时间轮:总共24个格子,每格1小时
现在假设上面三个时间轮启动时间都是startTime,用totalTick变量表示总格子数,tick表示当前指针走到的格子位置,tickDuration表示每个格子的精度,那么对于一个任务
怎么计算其圈数和所在下标的位置呢?计算方式如下:
//计算任务执行点相对于时间轮启动时间的差值
duration = 任务执行时间点 - 时间轮启动时间点startTime
//计算从时间轮启动点到达执行点需要走多少格子
needTicks = duration / tickDuration
//减去已经走过的格子数,计算指针还需要走多少个格子
remainTicks = duration / tickDuration - tick
//计算还需要走多少圈
remainRounds(圈数)= remainTicks / totalTick
//如果提交的任务是过时的,比如我的任务执行点比当前时间点还小,那这种任务属于超时未执行任务,needTicks势必比tick小,那么需要尽早执行
ticks = Math.max(needTicks, tick)
//求余,计算存放任务的下标,ticks是一直往上递增的,为了性能考虑,这个totalTick会膨胀为2的指数次幂
index = ticks % totalTick
假设上面三个时间轮启动的时间一样并且我们的任务E计算出来的duration为24小时30分20秒,那么首先这个任务E会存放在时时间轮的第24个格子上,等时时间轮走到第24个格子
后,会将这个任务E降级存放到分时间轮的第30个格子上,等分时间轮也走到第30个格子之后,又会把任务E存放到秒时间轮的第20个格子上,等秒时间轮走到第20个格子上之后
就会执行任务,我们管这种时间轮叫做层级时间轮。
三、Netty中时间轮的实现
3.1 类图
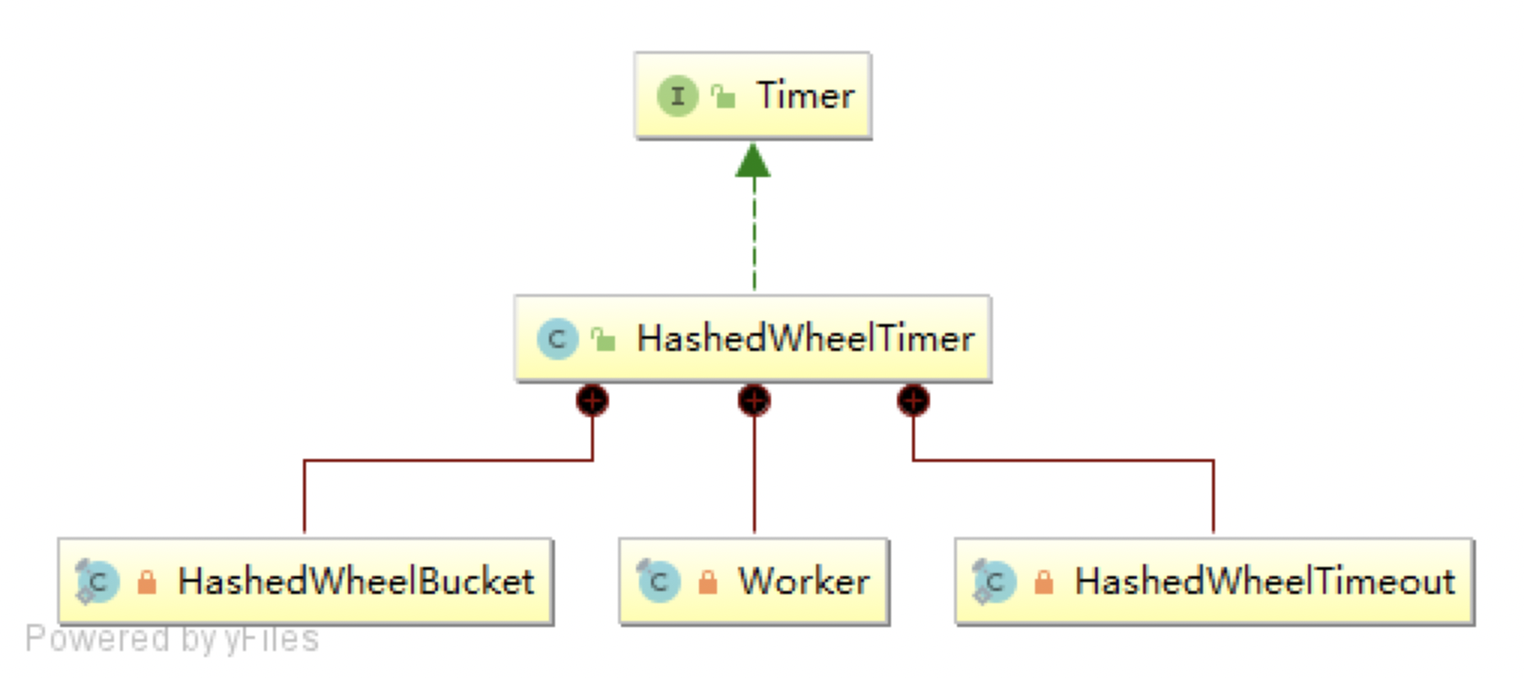
- HashedWheelTimer:时间轮对象
- HashedWheelBucket:HashedWheelTimer的内部类,表示时间轮上的每个格子,它是一个链表
- Worker:时间轮的轮询线程,理解为指针即可
- HashedWheelTimeout:延时任务,HashedWheelBucket的链表值,封装了任务,圈数,下标位置
3.2 构造器
//threadFactory:线程工厂,用于创建线程
//tickDuration:每个格子的精度
//ticksPerWheel:时间轮的总格子数
//leakDetection:是否启动内存泄露检测
//maxPendingTimeouts:最多可提交多少延时任务
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
//。。。。。。省略部分参数检查代码
// Normalize ticksPerWheel to power of two and initialize the wheel.
//将时间轮的格子数调整为2的指数次幂,求余的时候提高性能
wheel = createWheel(ticksPerWheel);
//求余掩码
mask = wheel.length - 1;
// Convert tickDuration to nanos.
//转换成纳秒
long duration = unit.toNanos(tickDuration);
// Prevent overflow.
if (duration >= Long.MAX_VALUE / wheel.length) {
throw new IllegalArgumentException(String.format(
"tickDuration: %d (expected: 0 < tickDuration in nanos < %d",
tickDuration, Long.MAX_VALUE / wheel.length));
}
if (duration < MILLISECOND_NANOS) {
if (logger.isWarnEnabled()) {
logger.warn("Configured tickDuration %d smaller then %d, using 1ms.",
tickDuration, MILLISECOND_NANOS);
}
this.tickDuration = MILLISECOND_NANOS;
} else {
this.tickDuration = duration;
}
workerThread = threadFactory.newThread(worker);
leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null;
this.maxPendingTimeouts = maxPendingTimeouts;
if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&
WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {
reportTooManyInstances();
}
}
构造器中主要对一些参数做了些校验和处理。
3.3 启动时间轮
public void start() {
//原子类 WORKER_STATE_UPDATER 用于标识当前时间轮的状态,刚创建时为 WORKER_STATE_INIT
switch (WORKER_STATE_UPDATER.get(this)) {
case WORKER_STATE_INIT:
//启动轮询线程,开始走时间格子
if (WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {
workerThread.start();
}
break;
case WORKER_STATE_STARTED:
break;
case WORKER_STATE_SHUTDOWN:
throw new IllegalStateException("cannot be started once stopped");
default:
throw new Error("Invalid WorkerState");
}
// Wait until the startTime is initialized by the worker.
while (startTime == 0) {
try {
startTimeInitialized.await();
} catch (InterruptedException ignore) {
// Ignore - it will be ready very soon.
}
}
}
上面这个方法启动轮询线程,就像一个钟表加上电池之后,指针开始转动。
3.4 提交延时任务
//task:任务对象,我们提交的任务实现这个接口即可
//delay:延时执行的时间
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
if (task == null) {
throw new NullPointerException("task");
}
if (unit == null) {
throw new NullPointerException("unit");
}
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
//检查是否达到任务提交上限
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
//启动轮询线程,可以看做是启动指针,让它开始转动
start();
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
//计算延时任务执行点时间相对于时间轮启动时间的差值
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
//封装任务
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
//放入时间轮队列,等待轮询线程迁移到对应格子上
timeouts.add(timeout);
return timeout;
}
提交任务的时候,会判断时间轮是否已经启动,启动后继续计算当前任务相对于时间轮启动时间的差值,以便轮询线程去计算下标位置和圈数
3.5 轮询线程(指针)
public void io.netty.util.HashedWheelTimer.Worker#run() {
// Initialize the startTime.
//时间轮启动时间
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
// Notify the other threads waiting for the initialization at start().
startTimeInitialized.countDown();
do {
//睡眠一个格子的时间,比如每个格子1s,那么sleep一秒
final long deadline = waitForNextTick();
if (deadline > 0) {
//tick表示当前指针走了多少格子,一直递增
//idx表示当前走到的格子下标,由于总格子数是一个2的指数次幂的值,所以只是用位运算求余
int idx = (int) (tick & mask);
//剔除已经移除的任务
processCancelledTasks();
//获取对应的下标格子的链表
HashedWheelBucket bucket =
wheel[idx];
//将提交的延时任务从待调度队列中取出,计算其圈数,下标存放到时间轮当中
//每次取最多100000条数据
transferTimeoutsToBuckets();
//检查圈数与deadline,如果到期,那么执行任务
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
// Fill the unprocessedTimeouts so we can return them from stop() method.
//时间轮关闭,清除所有任务,并把未执行的任务存储到unprocessedTimeouts(未处理的任务)中
for (HashedWheelBucket bucket: wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
for (;;) {
//处理待存入时间轮格子的任务,把未取消的任务存入unprocessedTimeouts(未处理的任务)中
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
//剔除掉取消的延时任务
processCancelledTasks();
}
时间轮启动时,首先记录下启动的时间,这个时间用于计算任务与启动时间的差值,用于定位下标和计算圈数,然后进入一个无限循环,每隔一个精度走一个格子,每走一个格
子会剔除被取消掉的任务和迁移提交的任务以及检查对应格子的任务是否有到期的任务,如果有,那么执行。
下面我们看到Netty是怎么迁移待调用的任务到时间轮格子的
private void io.netty.util.HashedWheelTimer.Worker#transferTimeoutsToBuckets() {
// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just
// adds new timeouts in a loop.
//每次最多取10w条数据
for (int i = 0; i < 100000; i++) {
//从待定任务队列任务中取值
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// all processed
break;
}
//被取消的,跳过
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// Was cancelled in the meantime.
continue;
}
//计算从时间轮启动点到任务执行点需要走多少格子
long calculated = timeout.deadline / tickDuration;
//calculated - tick用于计算还剩多少格子未走,除以总格子数计算还需要走多少圈
timeout.remainingRounds = (calculated - tick) / wheel.length;
//如果提交的任务是过时的,比如我的任务执行点比当前时间点还小,那这种任务属于超时未执行任务,needTicks势必比tick小,那么需要尽早执行
final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
//计算下标
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
//存入时间轮格子链表
bucket.addTimeout(timeout);
}
}
从上面的方法可以看到,Netty每次最多取10w条数据进行迁移,计算方法本人在前面分析时间轮的出现时已经讲过,此处不再赘述
下面我们再来看看它是怎么执行任务的
public void io.netty.util.HashedWheelTimer.HashedWheelBucket#expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// process all timeouts
//遍历当前格子上的所有任务
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
//圈数小于等于零的,已经到期的,那么可以直接执行了
//对于圈数还未减到0的,那么减去1,等待下次调度
if (timeout.remainingRounds <= 0) {
next = remove(timeout);
if (timeout.deadline <= deadline) {
timeout.expire();
} else {
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
next = remove(timeout);
} else {
timeout.remainingRounds --;
}
timeout = next;
}
}
首先检查任务的圈数是否已经减到0,如果还未减到零的,那么需要进行下一轮的比较,这里先比较圈数,再把圈数减一,其实就是在计算与任务相遇的次数,假设圈数是9,那
么指针在与这个任务相遇的第10次开始执行。
四、后话
博主从概念,缘由对时间轮做了比较详细的阐述并辅以Netty的实现做结尾,相信用心的读者都能够读懂,博主水平有限,如若有错误的地方,还望批评指正。以下为本人公众号,欢迎关注。

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/187151.html原文链接:https://javaforall.net


