
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Learning Discriminative Features with Multiple Granularities for Person Re-Identification(MGN)
论文:Learning Discriminative Features with Multiple Granularities for Person Re-Identification,2018,cvpr.
作者:云从科技
摘要
背景:将整体特征与局部特征相结合是提高行人再识别(Re-ID)能力的重要解决方案。以往的基于局部的方法主要是通过定位具有特定语义的区域来学习局部表示,这增加了学习难度,但对方差较大的场景缺乏有效性和鲁棒性。
贡献:本文中提出了一种融合不同粒度的判别信息的端到端特征学习策略。设计了多分支深度网络体系结构,其中一个分支用于全局特征表示,两个分支用于局部特征表示。本文没有学习语义区域,而是将图像统一划分为若干条,并改变局部分支的部分数量,得到具有多个粒度的局部特征表示。
网络效果:在包括Market-1501、DukeMTMC-reid和CUHK03在内的主流评估数据集上进行的综合实验表明,论文中的方法稳健地实现了最先进的性能,并在很大程度上优于任何现有的方法。
介绍
本文提出了一种不同粒度的全局和局部信息相结合的特征学习策略。不同数量的分区条带引入了内容粒度的多样性。我们定义原始图像只包含一个全局信息的整体分割为最粗情况,并且随着分割数目的增加,局部特征可以更多的集中在每个部分条带中更精细的判别信息,过滤其他条带上的信息。深度学习机制可以从整个图像中获取主体上的近似响应偏好,因此也可以从较小的局部区域中提取出更细粒度的局部特征显著性。这些局部区域不必是具有特定语义的定位区域,而只需要是原始图像上的一块等分条带。从观察中我们发现,随着水平条数的增加,区分反应的粒度变得更细。
基于这一动机,我们从ResNet-50骨干网的第四剩余阶段设计了多粒度网络(MGN),一个多分支网络体系结构,将其分为一个全局分支和两个局部分支,并对其参数进行了细化。在MGN的每个局部分支中,将全局汇集的特征映射划分为不同数量的条带作为部分区域,以独立的学习局部特征表示。
与以往的基于局部的方法相比,本文中的方法只利用等分部分进行局部表示,但在性能上优于以往的所有方法,此外,该方法学习了一个端到端的学习过程,易于学习和实现。
网络结构
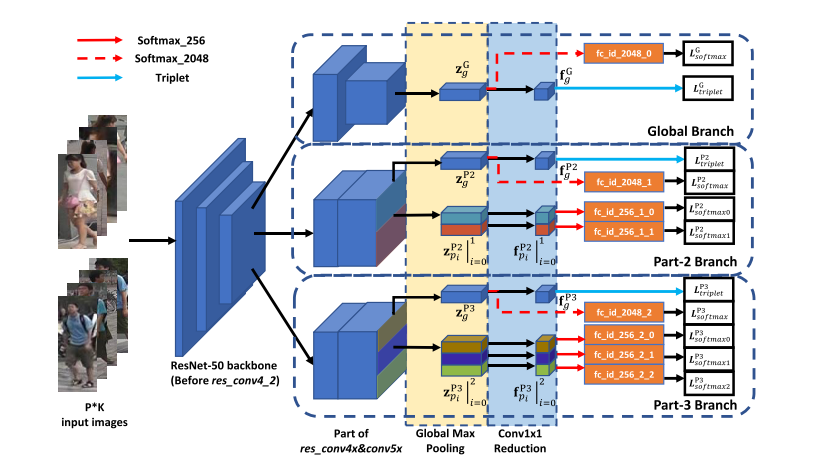

网络主干为ResNet-50,本文将res_conv4_1块后的后续部分划分为三个独立的分支,与原ResNet-50共享相似的架构。在测试阶段,为了获得强大的识别能力,将所有降到256维的特征串接为最终特征,结合全局和局部信息来完善对学习特征的总和性。
前三层网络是共享的,到第四层时分成三个支路,第一个支路是 global 的分支,第二个是 part-2 的分支,第三个是 part-3 的分支。在 global 的地方有两块,右边这个方块比左边的方块大概缩小了一倍(12×4),因为做了个下采样,下面两个分支没有做下采样,所以第四层和第五层特征图是一样大小的(24×8)。
接下来我们看一下图中黄色部分的区域。网络对 part-2 跟 part-3 做一个从上到下的纵向分割,part-2 在第五层特征图谱分成两块,part-3 对特征图谱从上到下分成三块。在分割完成后,我们用Max-pooling,得到一个 2048 的向量。
然后我们来看一下具体是怎么操作的,part-2 跟 part-3 的操作跟 global不一样,part-2 有两个 pooling,第一个pooling对应Zg p2(蓝色的长条),通过24×8大小的卷积核,将第五层特征图直接最大池化生成1×1×2048的向量。第二个pooling的卷积核大小和第一个不一样,为12×8,因此生成的是2×1×2048的向量,我们将其拆成2个1×1×2048的向量,对应图中part-2 中的2个接在一起的长条形。淡蓝色这个地方变成了小方体 ,大小为1×1×256,这个地方是做的降维,从 2048 维做成 256 维,主要是为了方便特征计算,这样更快更有效。
在测试的时候在淡蓝色的地方,小方块从上而下应该是8个,我们把这8个256维的特征串联在一起成为2048的特,用这个特征替代前面输入的图片计算相似度。
网络分支
global分支:图中第一块的Loss 设计,这个地方对2048维的特征做了SoftmaxLoss 损失,对256维的特征做了一个TripletLoss 损失。
part2&part3分支:中间part2部分和下部part3部分有一个全局信息,有global特征,做SoftmaxLoss + TripletLoss 。下面两个局部特征只用了SoftmaxLoss,未用TripletLoss,文中提到对细节使用TripletLoss效果会变差,(原因:一张图片分成从上到下两部分的时候,最完美的情况当然是上面部分是上半身,下面部分是下半身,但是在实际的图片中,有可能整个人都在上半部分,下半部分全是背景,这种情况用上、下部分来区分,假设下半部分都是背景,把这个背景放到 TripletLoss 三元损失里去算这个 Loss,就会使得这个模型学到莫名其妙的特征。)
解读
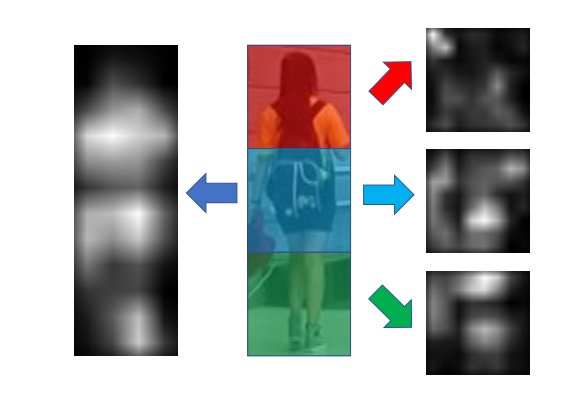
上图显示了从IDE基线模型和基于IDE的部件中提取的特定图像的特征响应图。可以观察到,即使没有明确的注意力机制来增强对某些显著成分的偏好,深层网络仍然可以根据不同身体部位的内在语义来初步区分它们的反应偏好。然而为了消除复杂度高的行人图像中的无关模型的干扰,更高的响应的只集中在行人的主体上,而不是任何具有语义模式的具体部位。当缩小表示区域的范围并将其训练为学习局部特征的分类任务是,我们可以观察到局部特征映射上的响应开始聚集在一些显著的语义模式上,这些语义模式也随着表示区域的大小而变化。
这一观察反映了图像内容量(即区域的粒度)与深度网络关注特定表示模式的能力之间的关系。我们相信这种现象是由于信息在有限区域内的局限性造成的。一般来说,从全局图像比较,很难从局部区域区分行人的身份。分类任务的监控信号强制将特征正确分类为目标身份,这也推动了学习过程试图在有限的信息中探索有用的细粒度细节。实际上,以前基于零件的方法中的局部特征学习
仅在有或无经验先验知识的情况下,将分区的基本粒度多样性引入到整个特征学习过程中。假设存在适当级别的粒度,则具有最具歧视性信息的细节可能最集中于深层网络。基于以上的观察和分析,我们提出了多粒度网络(MGN)架构,将全局和多粒度局部特征学习相结合,以获得更强大的行人表示。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/188438.html原文链接:https://javaforall.net


