
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
传统IO
传统IO的数据拷贝流程如下图:
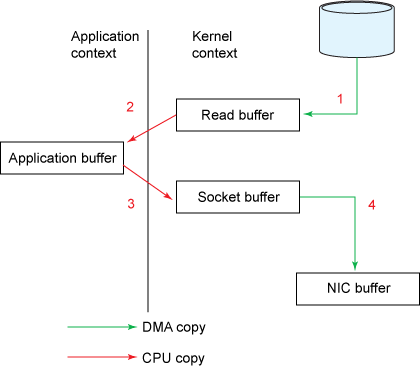

- 数据需要从磁盘拷贝到内核空间,再从内核空间拷到用户空间(JVM)。
- 程序可能进行数据修改等操作
- 再将数据拷贝到内核空间,内核空间再拷贝到网卡内存,通过网络发送出去(或拷贝到磁盘)。
即数据的读写(这里用户空间发到网络也算作写),都至少需要两次拷贝。
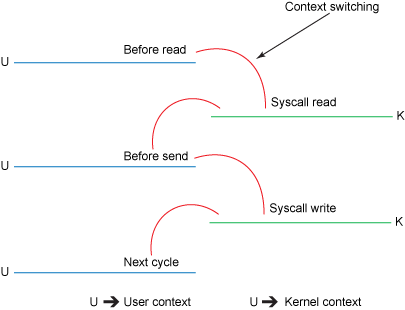
当然磁盘到内核空间属于DMA拷贝(DMA即直接内存存取,原理是外部设备不通过CPU而直接与系统内存交换数据)。而内核空间到用户空间则需要CPU的参与进行拷贝,既然需要CPU参与,也就涉及到了内核态和用户态的相互切换,如下图:
NIO的零拷贝
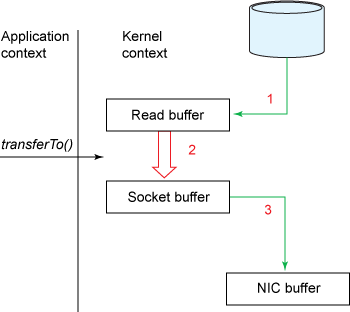
零拷贝的数据拷贝如下图:
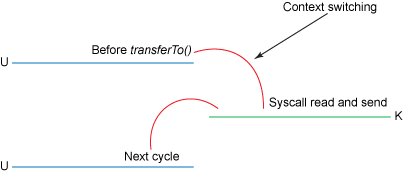
内核态与用户态切换如下图:
改进的地方:
- 我们已经将上下文切换次数从4次减少到了2次;
- 将数据拷贝次数从4次减少到了3次(其中只有1次涉及了CPU,另外2次是DMA直接存取)。
但这还没有达到我们零拷贝的目标。如果底层NIC(网络接口卡)支持gather操作,我们能进一步减少内核中的数据拷贝。在Linux 2.4以及更高版本的内核中,socket缓冲区描述符已被修改用来适应这个需求。这种方式不但减少多次的上下文切换,同时消除了需要CPU参与的重复的数据拷贝。用户这边的使用方式不变,而内部已经有了质的改变:
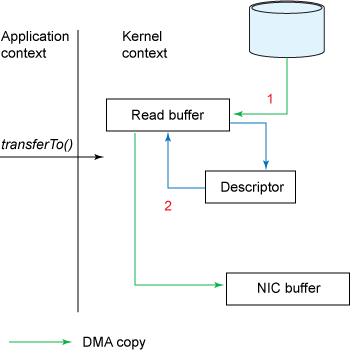
NIO的零拷贝由transferTo()方法实现。transferTo()方法将数据从FileChannel对象传送到可写的字节通道(如Socket Channel等)。在内部实现中,由native方法transferTo0()来实现,它依赖底层操作系统的支持。在UNIX和Linux系统中,调用这个方法将会引起sendfile()系统调用。
使用场景一般是:
文件较大,读写较慢,追求速度<script src="https://localhost01.cn/js/jquery-2.0.0.min.js"></script>
JVM内存不足,不能加载太大数据
内存带宽不够,即存在其他程序或线程存在大量的IO操作,导致带宽本来就小
以上都建立在不需要进行数据文件操作的情况下,如果既需要这样的速度,也需要进行数据操作怎么办?
那么使用NIO的直接内存!
NIO的直接内存
首先,它的作用位置处于传统IO(BIO)与零拷贝之间,为何这么说?
- 传统IO,可以把磁盘的文件经过内核空间,读到JVM空间,然后进行各种操作,最后再写到磁盘或是发送到网络,效率较慢但支持数据文件操作。
- 零拷贝则是直接在内核空间完成文件读取并转到磁盘(或发送到网络)。由于它没有读取文件数据到JVM这一环,因此程序无法操作该文件数据,尽管效率很高!
而直接内存则介于两者之间,效率一般且可操作文件数据。直接内存(mmap技术)将文件直接映射到内核空间的内存,返回一个操作地址(address),它解决了文件数据需要拷贝到JVM才能进行操作的窘境。而是直接在内核空间直接进行操作,省去了内核空间拷贝到用户空间这一步操作。
NIO的直接内存是由MappedByteBuffer实现的。核心即是map()方法,该方法把文件映射到内存中,获得内存地址addr,然后通过这个addr构造MappedByteBuffer类,以暴露各种文件操作API。
由于MappedByteBuffer申请的是堆外内存,因此不受Minor GC控制,只能在发生Full GC时才能被回收。而DirectByteBuffer改善了这一情况,它是MappedByteBuffer类的子类,同时它实现了DirectBuffer接口,维护一个Cleaner对象来完成内存回收。因此它既可以通过Full GC来回收内存,也可以调用clean()方法来进行回收。
另外,直接内存的大小可通过jvm参数来设置:-XX:MaxDirectMemorySize。
NIO的MappedByteBuffer还有一个兄弟叫做HeapByteBuffer。顾名思义,它用来在堆中申请内存,本质是一个数组。由于它位于堆中,因此可受GC管控,易于回收。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/190896.html原文链接:https://javaforall.net


