
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Fork/Join
是一个分而治之的任务框架,如一个任务需要多线程执行,分割成很多块计算的时候,可以采用这种方法。
动态规范:和分而治之不同的是,每个小任务之间互相联系。
工作密取:分而治之分割了每个任务之后,某个线程提前完成了任务,就会去其他线程偷取任务来完成,加快执行效率。同时,第一个分配的线程是从队列中的头部拿任务,当完成任务的线程去其他队列拿任务的时候是从尾部拿任务,所以这样就避免了竞争。
在Java的Fork/Join框架中,使用两个类完成上述操作:
1.ForkJoinTask:我们要使用Fork/Join框架,首先需要创建一个ForkJoin任务。该类提供了在任务中执行fork和join的机制。通常情况下我们不需要直接集成ForkJoinTask类,只需要继承它的子类,Fork/Join框架提供了两个子类:
a.RecursiveAction:用于没有返回结果的任务
b.RecursiveTask:用于有返回结果的任务
2.ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行.他其实也是一个线程池。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
注意:ForkJoinPool的invoke方法是同步阻塞的,excute方法是异步的。
Fork/Join框架的实现原理:
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将存放程序提交给ForkJoinPool,ForkJoinWorkerThread负责执行这些任务。
使用场景:
Fork/Join框架适合能够进行拆分再合并的计算密集型(CPU密集型)任务。ForkJoin框架
是一个并行框架,因此要求服务器拥有多CPU、多核,用以提高计算能力。
如果是单核、单CPU,不建议使用该框架,会带来额外的性能开销,反而比单线程的执行效率低。当然不是因为并行的任务会进行频繁的线程切换,因为Fork/Join框架在进行线程池初始化的时候默认线程数量为Runtime.getRuntime().availableProcessors(),单CPU单核的情况下只会产生一个线程,并不会造成线程切换,而是会增加Fork/Join框架的一些队列、池化的开销。
比如:数据迁移到数据库,解析excel等等可以拆分完成的任务都可以使用到forkjoin。
实战
有返回值
需求:累加一个整形数组。
产生整形数组的工具类:
/**
* 产生整形数组
*/
public class MakeArray {
//数组长度
public static final int ARRAY_LENGTH = 4000;
public static int[] makeArray() {
//new一个随机数发生器
Random r = new Random();
int[] result = new int[ARRAY_LENGTH];
for (int i = 0; i < ARRAY_LENGTH; i++) {
//用随机数填充数组
result[i] = r.nextInt(ARRAY_LENGTH * 3);
}
return result;
}
}
继承RecursiveTask实现有返回值的任务计算:
public class SumArray {
//产生一个随机数组
private static int[] array = MakeArray.makeArray();
//阈值
private final static int POINT = MakeArray.ARRAY_LENGTH / 10;
//有返回值的任务
private static class SumTask extends RecursiveTask<Integer> {
//要累加的源数组
private int[] src;
//开始角标
private int startIndex;
//结束角标
private int endIndex;
public SumTask(int[] src, int startIndex, int endIndex) {
this.src = src;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
//实现具体的累加逻辑和任务分割逻辑
@Override
protected Integer compute() {
//不满足阈值的时候,这里面的逻辑也是当满足阈值的时候,递归执行的逻辑
if (endIndex - startIndex < POINT) {
int count = 0;
for (int i = startIndex; i <= endIndex; i++) {
count += src[i];
// SleepTools.ms(1);
}
return count;
//满足阈值的时候,需要分割任务,然后交给forkjoinpool去执行任务
} else {
//当需要分割的时候,采用折中法进行分割
//startIndex.......mid.......endIndex
int mid = (startIndex + endIndex) / 2;
//左任务
SumTask leftTask = new SumTask(src, startIndex, mid);
//右任务
SumTask rigthTask = new SumTask(src, mid + 1, endIndex);
//交给forkjoinpool去执行任务
invokeAll(leftTask, rigthTask);
//将执行结果返回
return leftTask.join() + rigthTask.join();
}
}
}
private static void testForkJoin() {
//创建ForkJoinPool池
ForkJoinPool forkJoinPool = new ForkJoinPool();
long startTime = System.currentTimeMillis();
SumTask task = new SumTask(array, 0, array.length - 1);
//这个方法是阻塞的,是同步的
forkJoinPool.invoke(task);
long endTime = System.currentTimeMillis();
System.out.println("采用forkjoin执行结果是:" + task.join() + "---------用时:" + (endTime - startTime));
}
private static void testFor() {
long startTime = System.currentTimeMillis();
int count = 0;
for (int i = 0; i < array.length; i++) {
count += array[i];
// SleepTools.ms(1);
}
long endTime = System.currentTimeMillis();
System.out.println("采用for循环执行结果是:" + count + "---------用时:" + (endTime - startTime));
}
public static void main(String[] args) {
testForkJoin();
testFor();
}
}
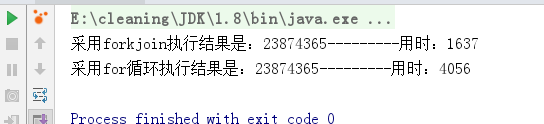
执行结果:

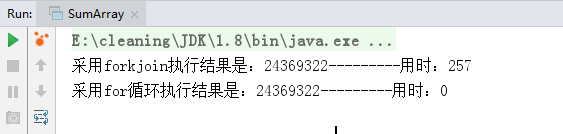
可以看出当数组并不大并且累加过程并不耗时的情况,循环累加效率优于forkjoin,当在累加的时候让线程休眠1毫秒时:
可以明显看出效率的差距,由此总结:对于计算过程复杂耗时的任务可以优先考虑使用forkjoin。
没有返回值
需求:遍历目录,搜寻目录下的所有文件
继承RecursiveAction实现无返回值的任务的执行:
public class FindFiles extends RecursiveAction {
//要搜寻的目录
private File dir;
public FindFiles(File dir) {
this.dir = dir;
}
@Override
protected void compute() {
File[] files = dir.listFiles();
if (files != null) {
List<FindFiles> list = new ArrayList<>();
for (File file : files) {
//如果是目录,就需要分割任务,交给ForkJoinPool去执行,因为任务数目不确定,所以需要定义一个集合
if (file.isDirectory()) {
FindFiles findFiles = new FindFiles(file);
list.add(findFiles);
//不是目录,是文件就执行自己的逻辑
} else {
if (file.getAbsolutePath().endsWith("dll")) {
System.out.println(file.getAbsolutePath());
}
}
}
//如果任务
if (list.size() > 0) {
Collection<FindFiles> findFiles = invokeAll(list);
for (FindFiles findFiles1 : findFiles) {
//等待所有的任务执行完成
findFiles1.join();
//所有的任务都执行完了才会执行
System.out.println(Thread.currentThread().getName() + "....join end..");
}
}
}
}
private static void testFork() {
ForkJoinPool forkJoinPool = new ForkJoinPool();
FindFiles findFiles = new FindFiles(new File("d://"));
//execute方法是异步的
forkJoinPool.execute(findFiles);
//阻塞,等待ForkJoin执行完,主线程才往下执行
findFiles.join();
System.out.println("end.....");
}
public static void main(String[] args) {
testFork();
}
}
执行结果:
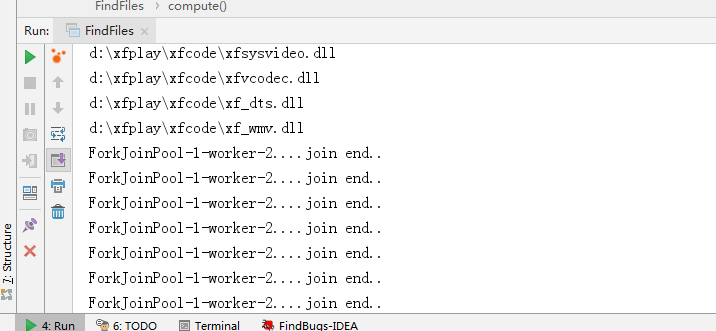
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191214.html原文链接:https://javaforall.net


