
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
项目结题总结
一、项目背景
对于一所高校来说一个好的风评有着十分重要的作用,拥有一个良好的口碑,能吸引更多的生源、引进更多的人才,学校的综合素质能力也会因此提升,因此我们小组选择了《山东大学舆情分析系统》这一题目,通过搜集百度新闻、央视新闻、今日头条、齐鲁网、新浪、网易新闻、微博、知乎等网站的有关信息,对搜集到的文本信息所进行的分词、统计处理,将结果绘制成可视化的热度词条、情感倾向变化图,并实时展示在网站上,以此来更直观的了解山大的实时风评。
二、技术要点
在本项目中,我们主要选用python语言。
在爬虫方面,我们采用Scrapy爬虫框架,首先对上述若干带有搜索引擎的入口网站进行一级爬取,该层主要爬取网页中以“山东大学”为关键字的搜索结果
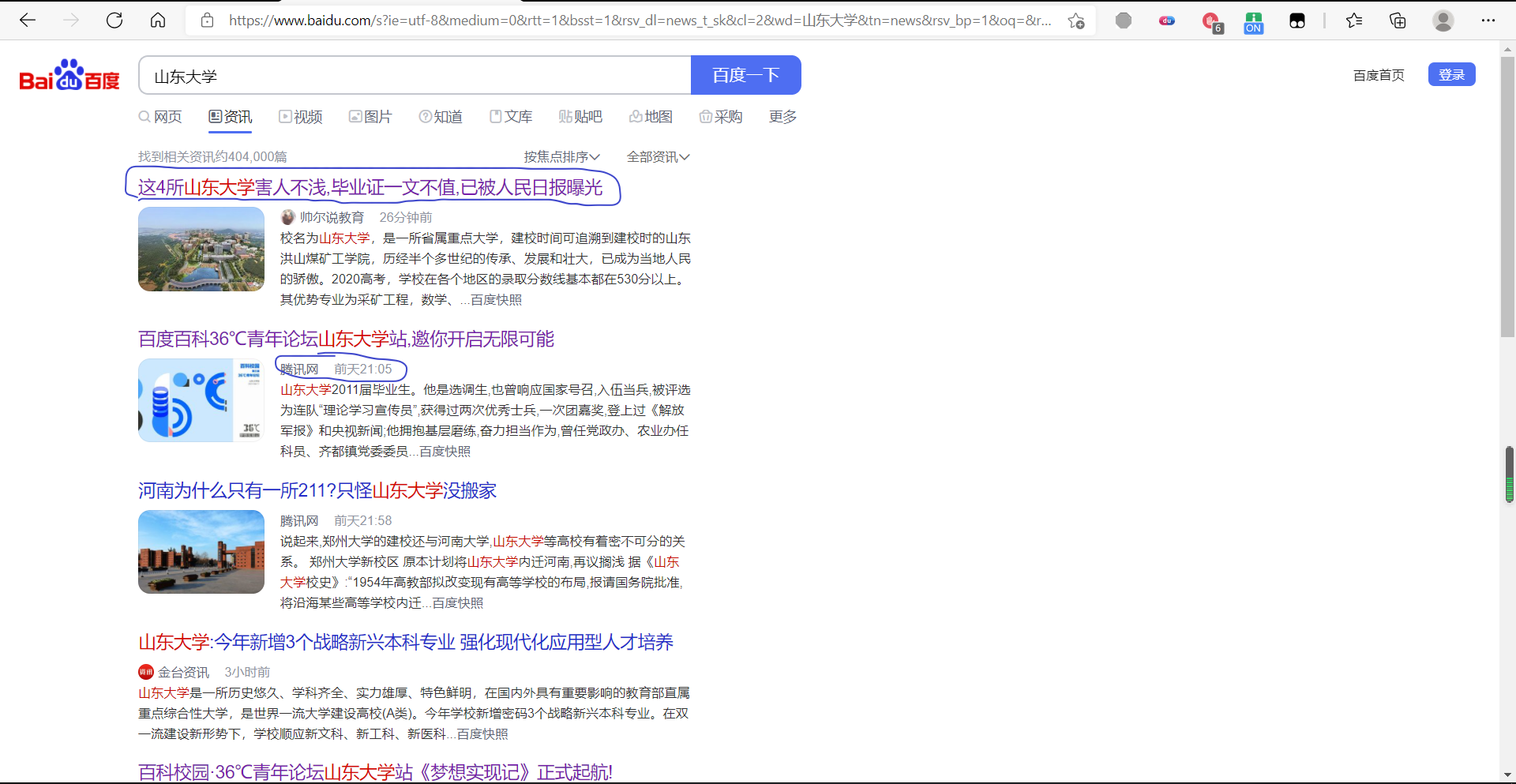

其次将对一级爬取中获得的网页链接进行二级爬取,该层主要爬取相关页面中的“相关推荐”、评论等内容。
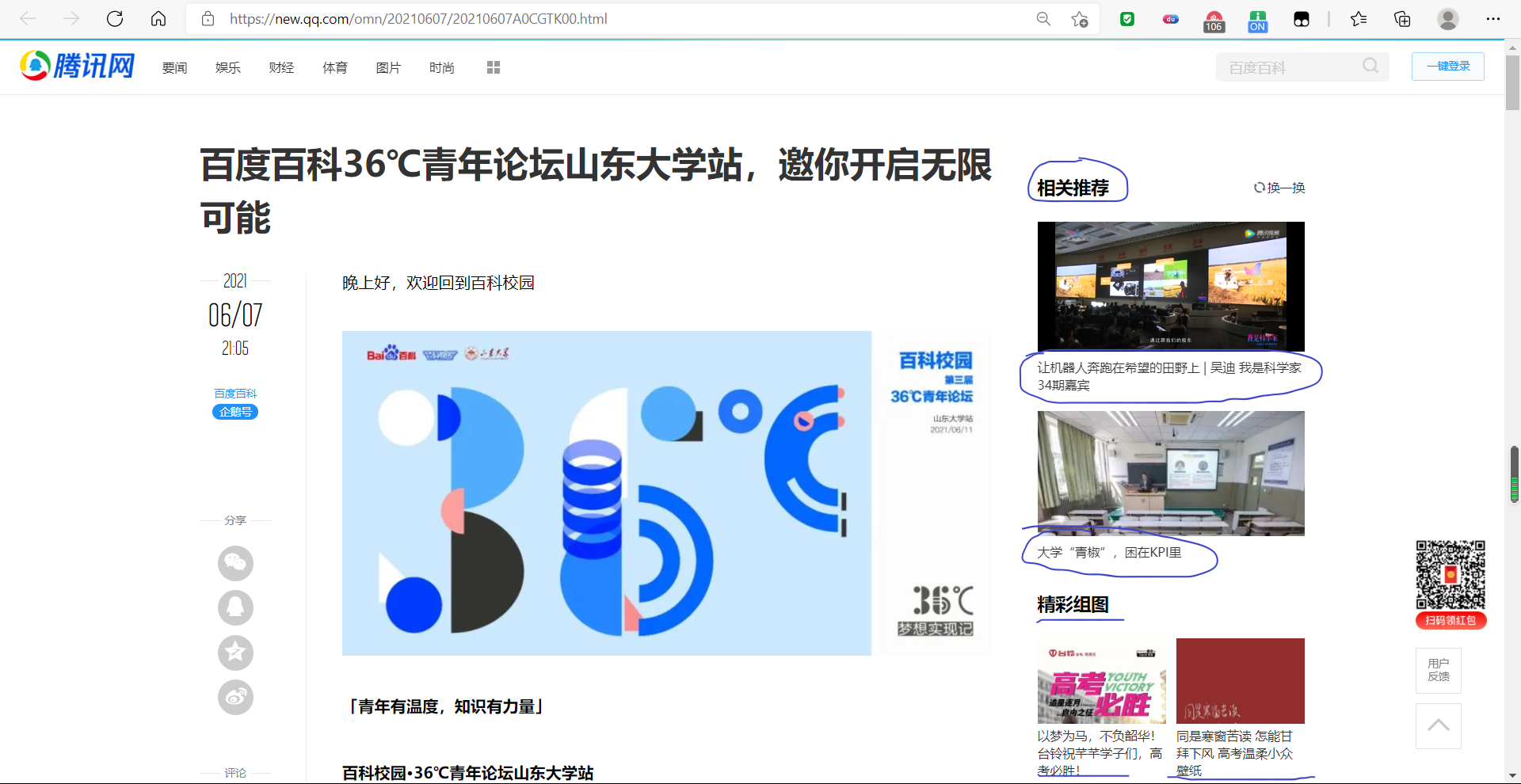
对于大部分网站中常见的反爬虫技术,我们采用了请求头随机UA、资源延时下载、cookie保存状态等来掩盖我们的爬虫,防止其被反爬虫技术识别。
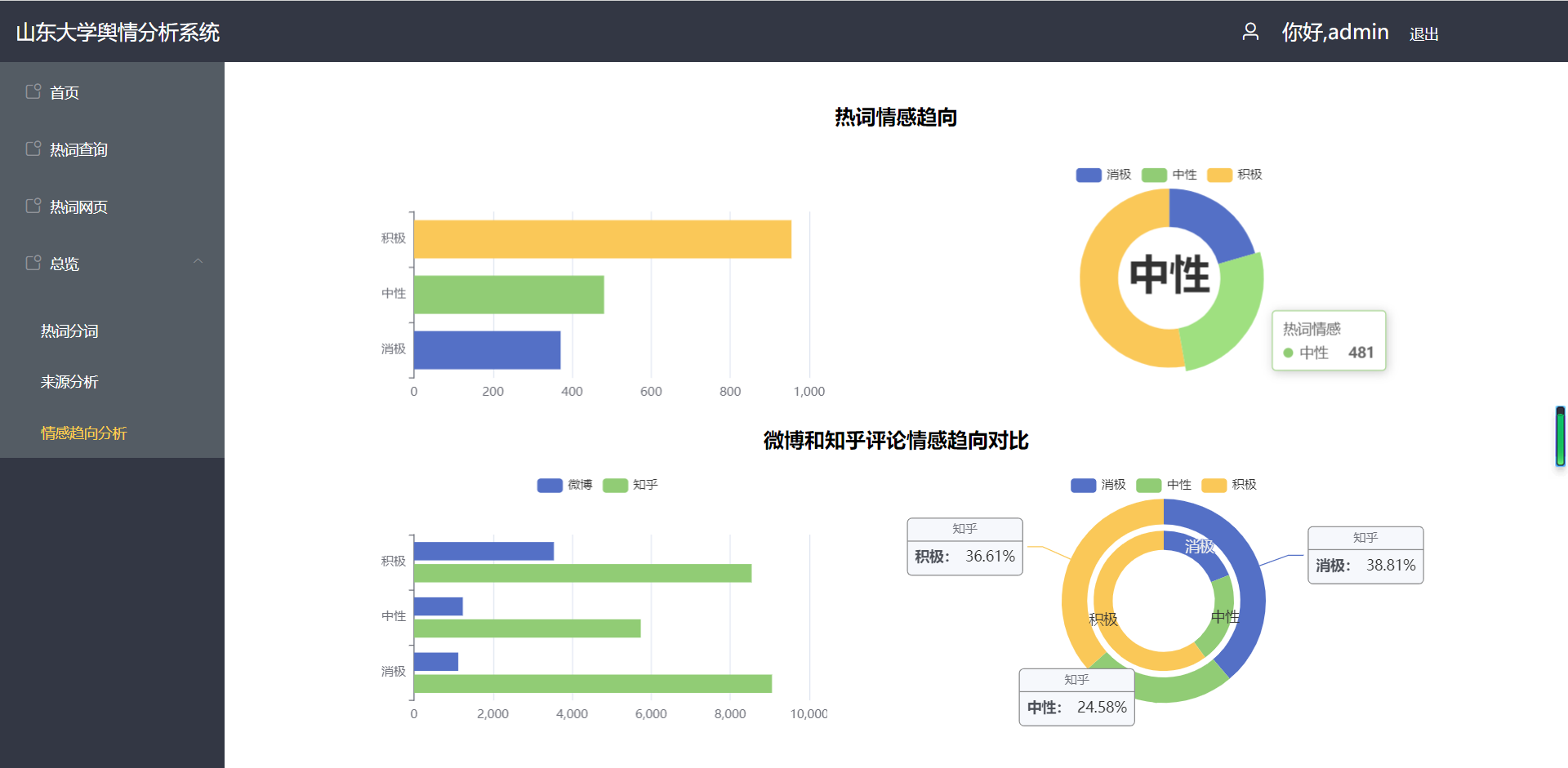
在分词方面,我们采用的是python的pkuseg库,并加入了我们自己生成的停用词词库、保留词词典等,以进一步优化分词结果。在情感分析方面,我们使用词的情感倾向表,通过各个词的权值对热词、评论进行情感分析。
在网页展示方面,我们采用了Vue的前端和Django的后端,以便能与爬虫和分词模块更好的兼容。
三、功能介绍
1、服务器端
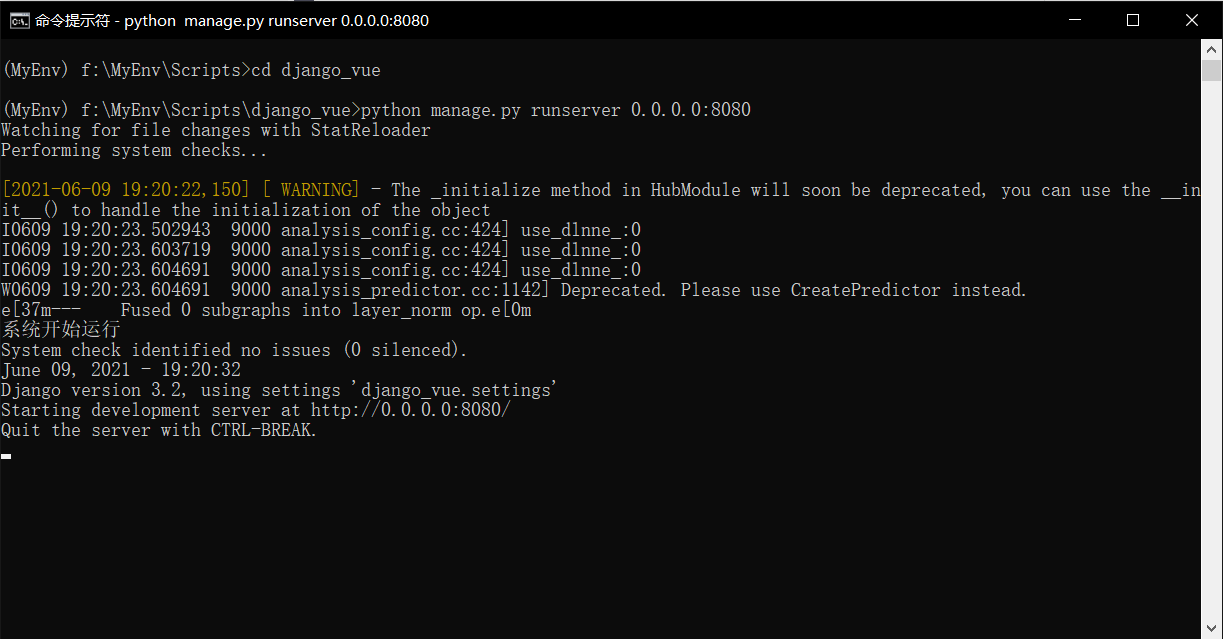
(1)启动服务器
我们的项目是在python的虚拟环境中运行,目前运行过程已经可以脱离编译器。因此我们首先进入python虚拟环境,进入django项目目录下,输入:
python manage.py runserver 0.0.0.0:8080
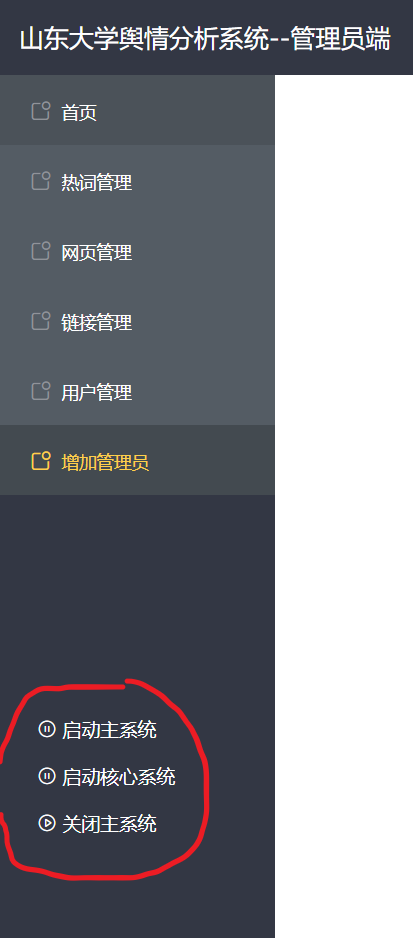
(2)后台主系统(控制爬虫、分词、分析模块)
- 后台主系统将在服务器启动时自动开启
- 主系统将在每天凌晨4~5点开启核心系统(爬虫、分词、分析模块)
- 主系统可以使用以下命令:
- “start”:开启主系统
- “stop” / “end”:关闭主系统
- “exit”:退出主系统
- ”help“:查看帮助信息
- 在核心系统运行时,无法关闭、退出主系统
(3)关闭服务器
关闭服务器前,需优先关闭主系统,再手动关闭服务器cmd窗口
2、网页端——未登录
(1)首页

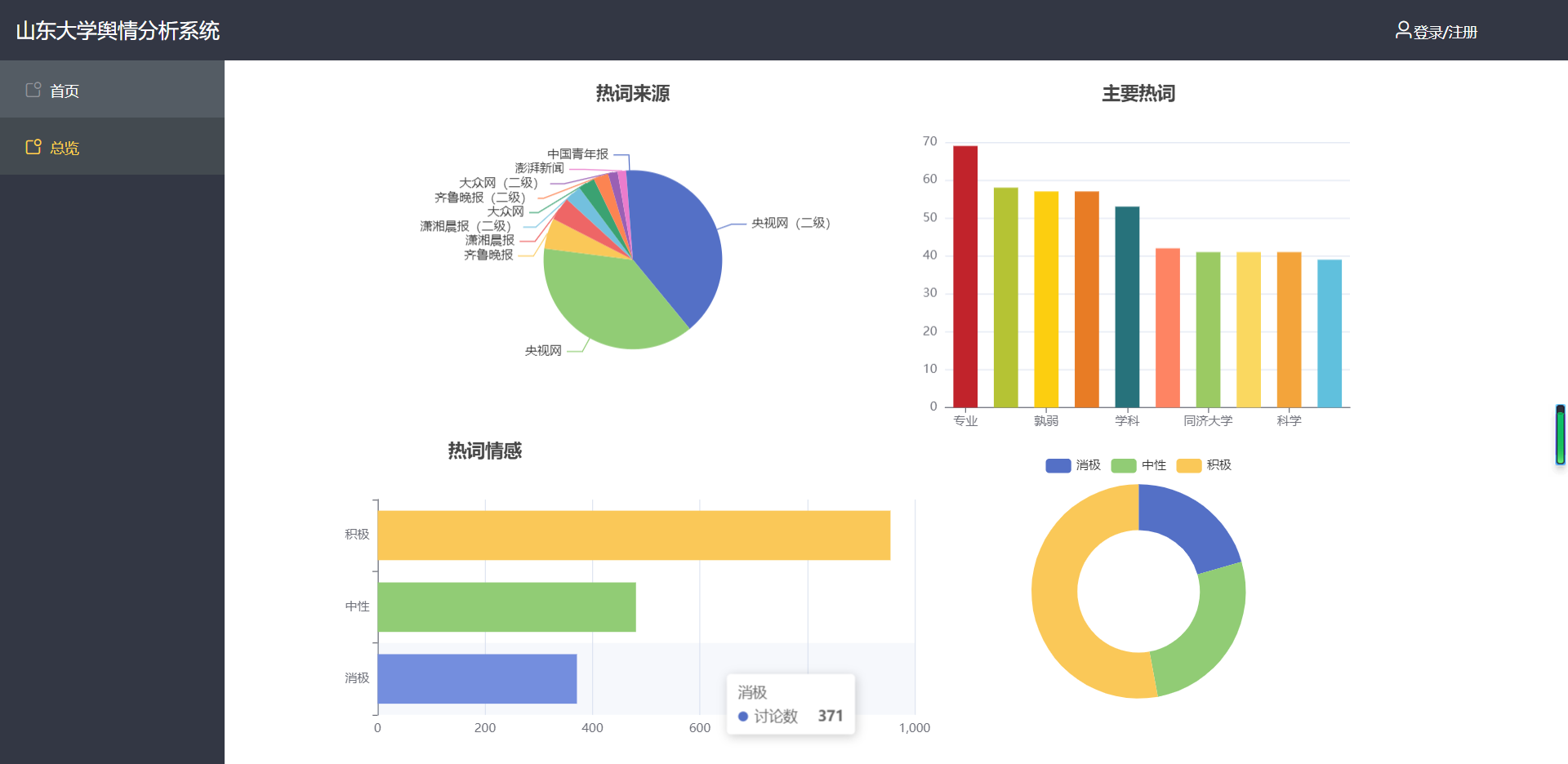
(2)总览
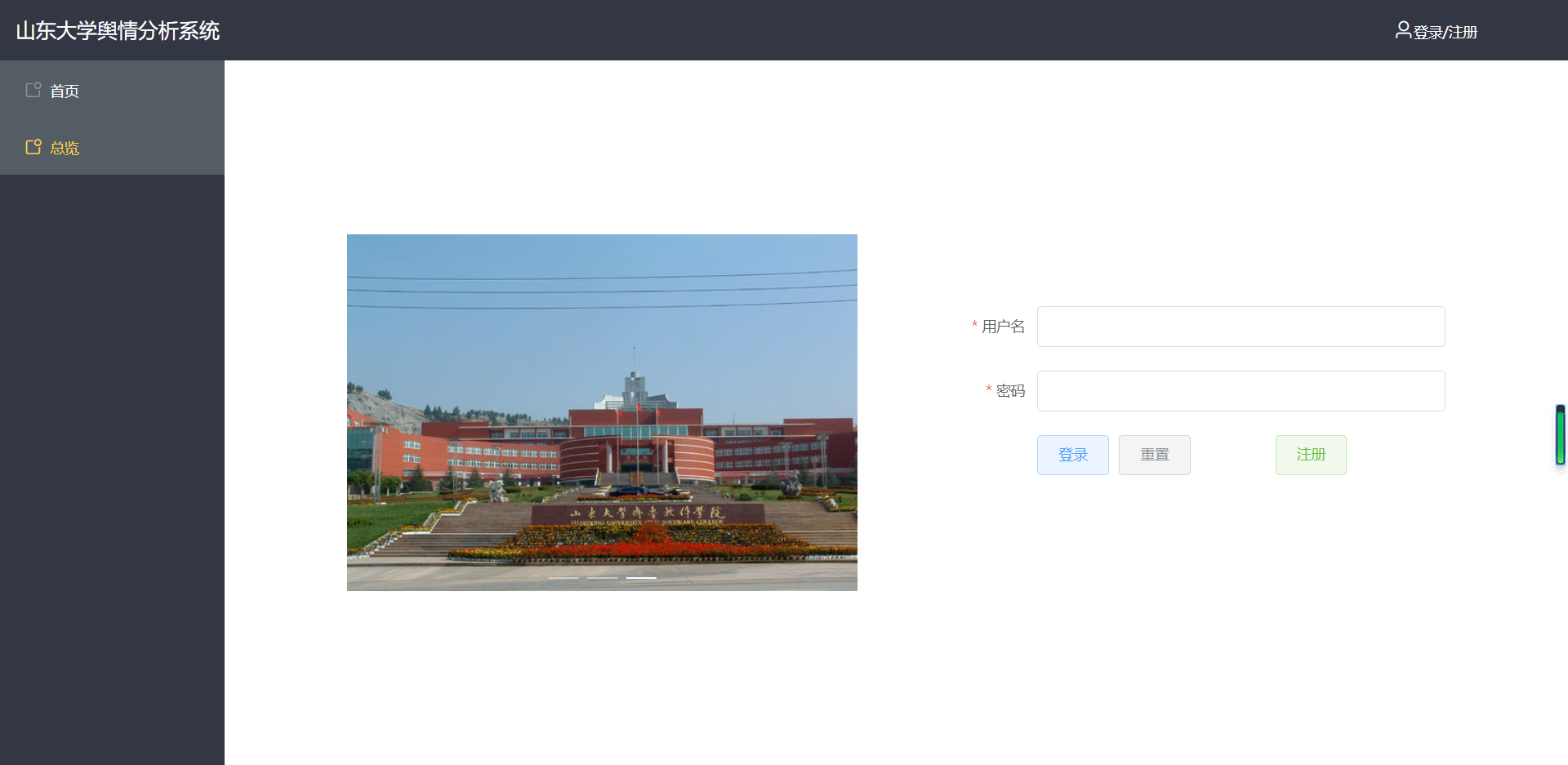
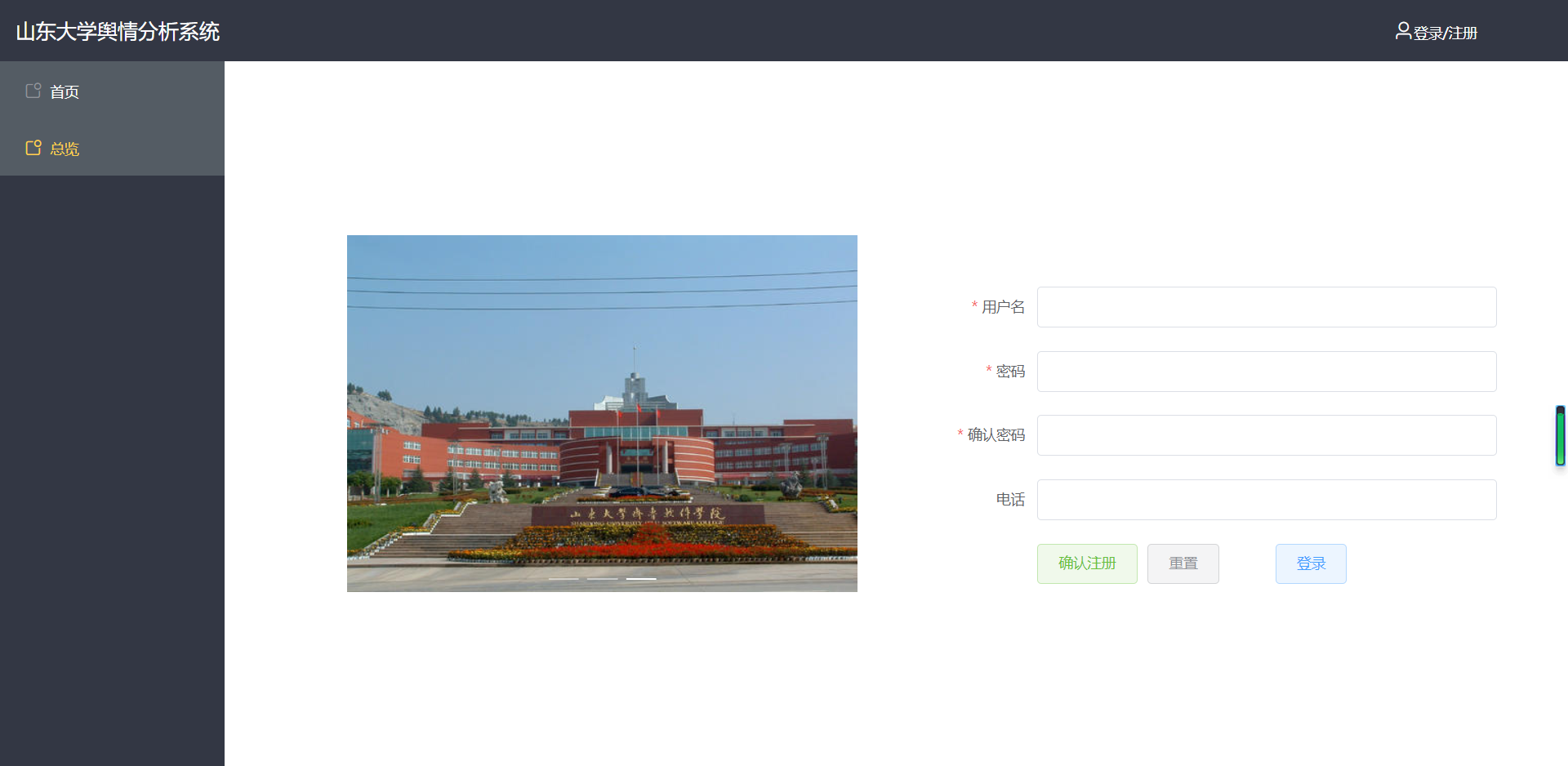
(3)登录 / 注册
3、网页端——用户端
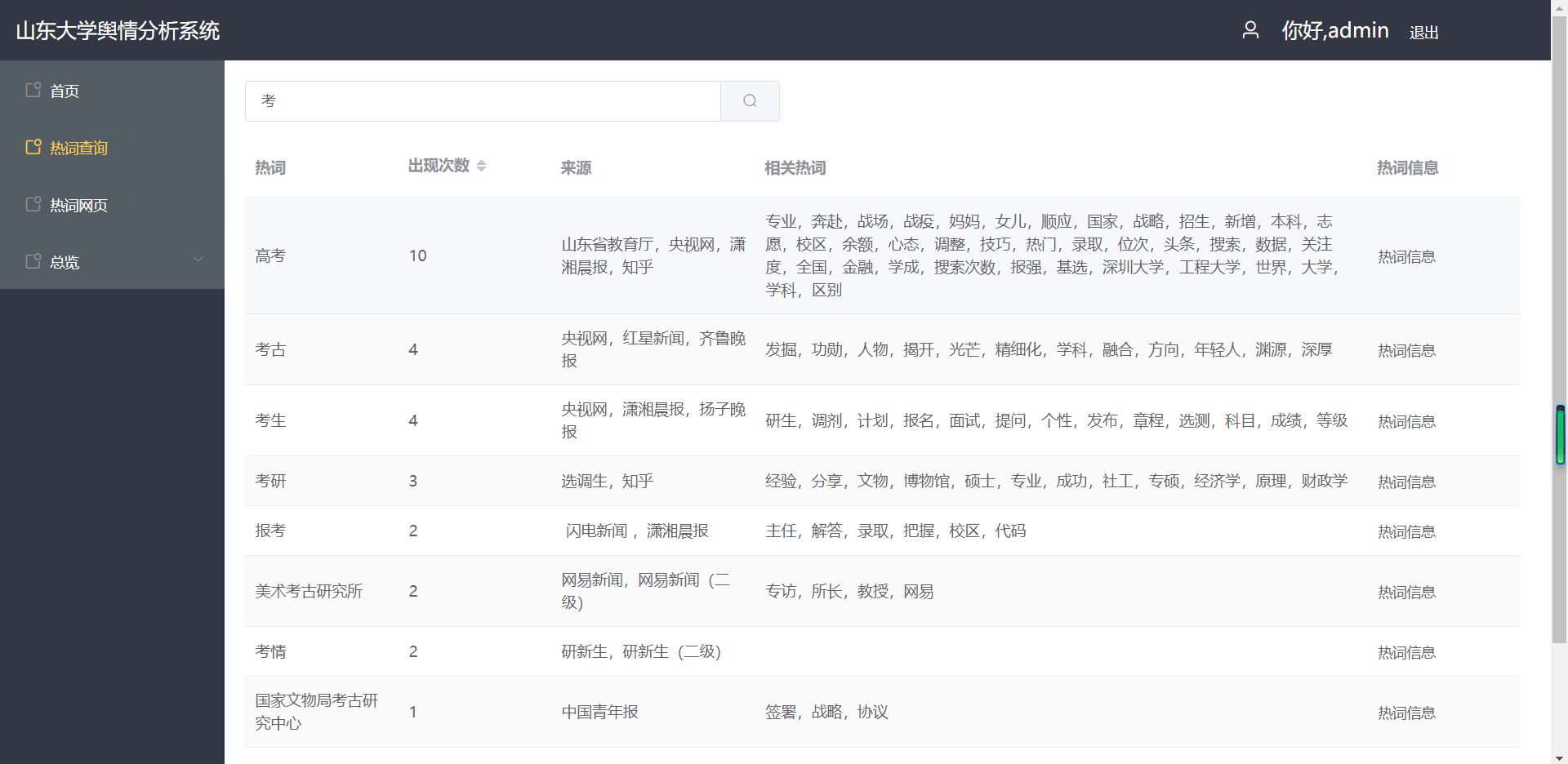
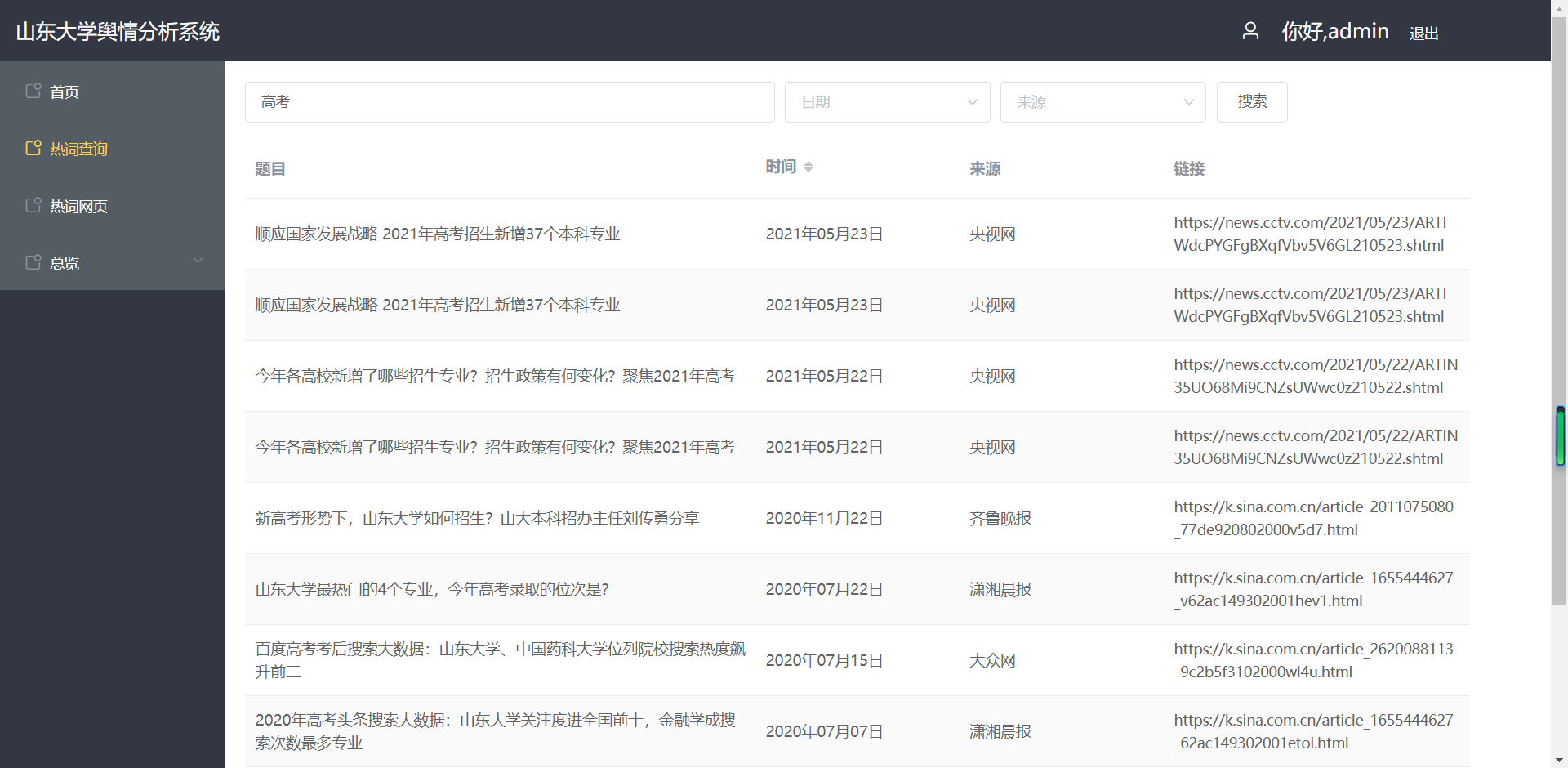
(1)单个热词查询
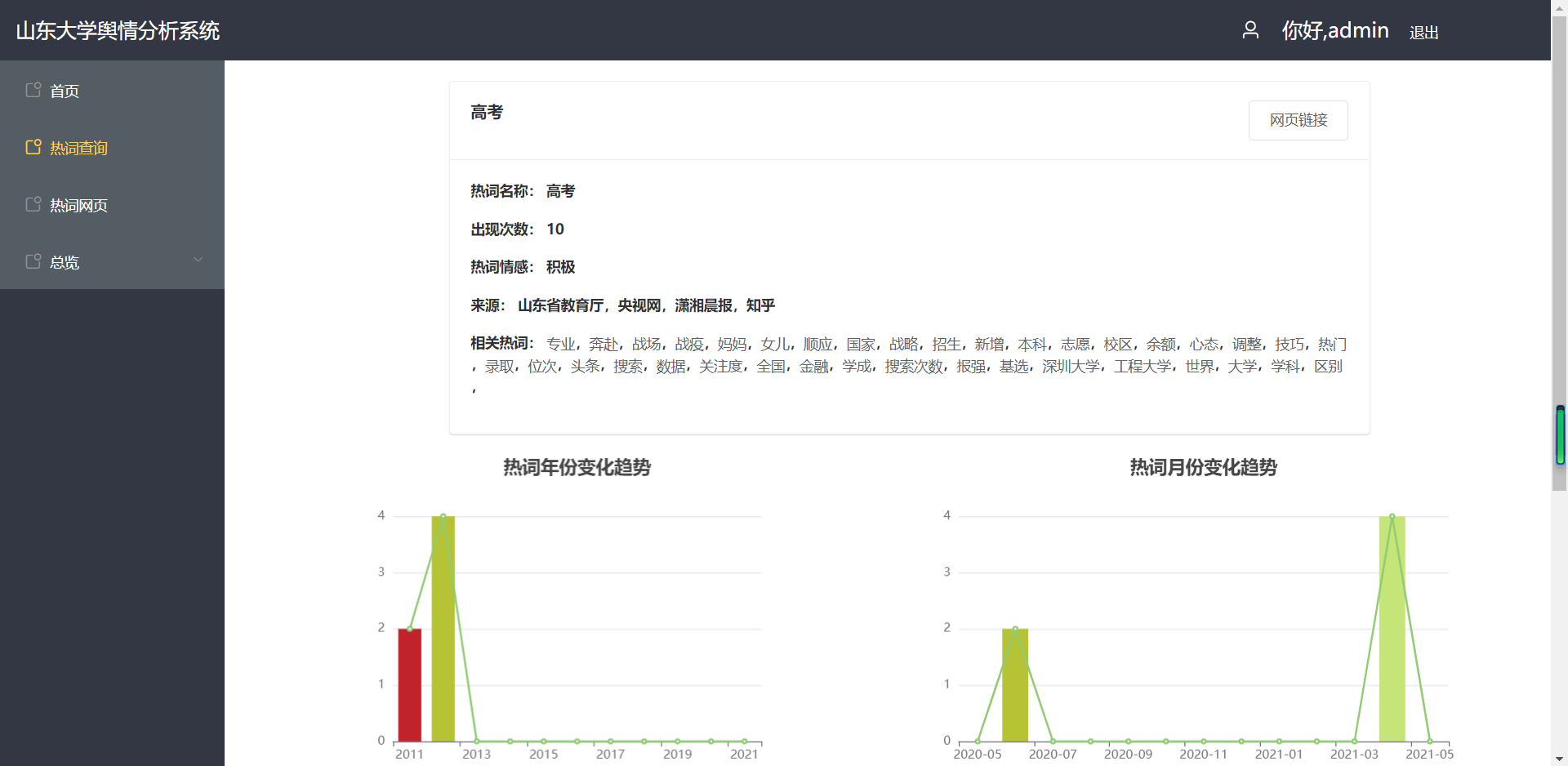
(2)单个热词信息
(3)热词相关网页查询
(4)总览——登陆后
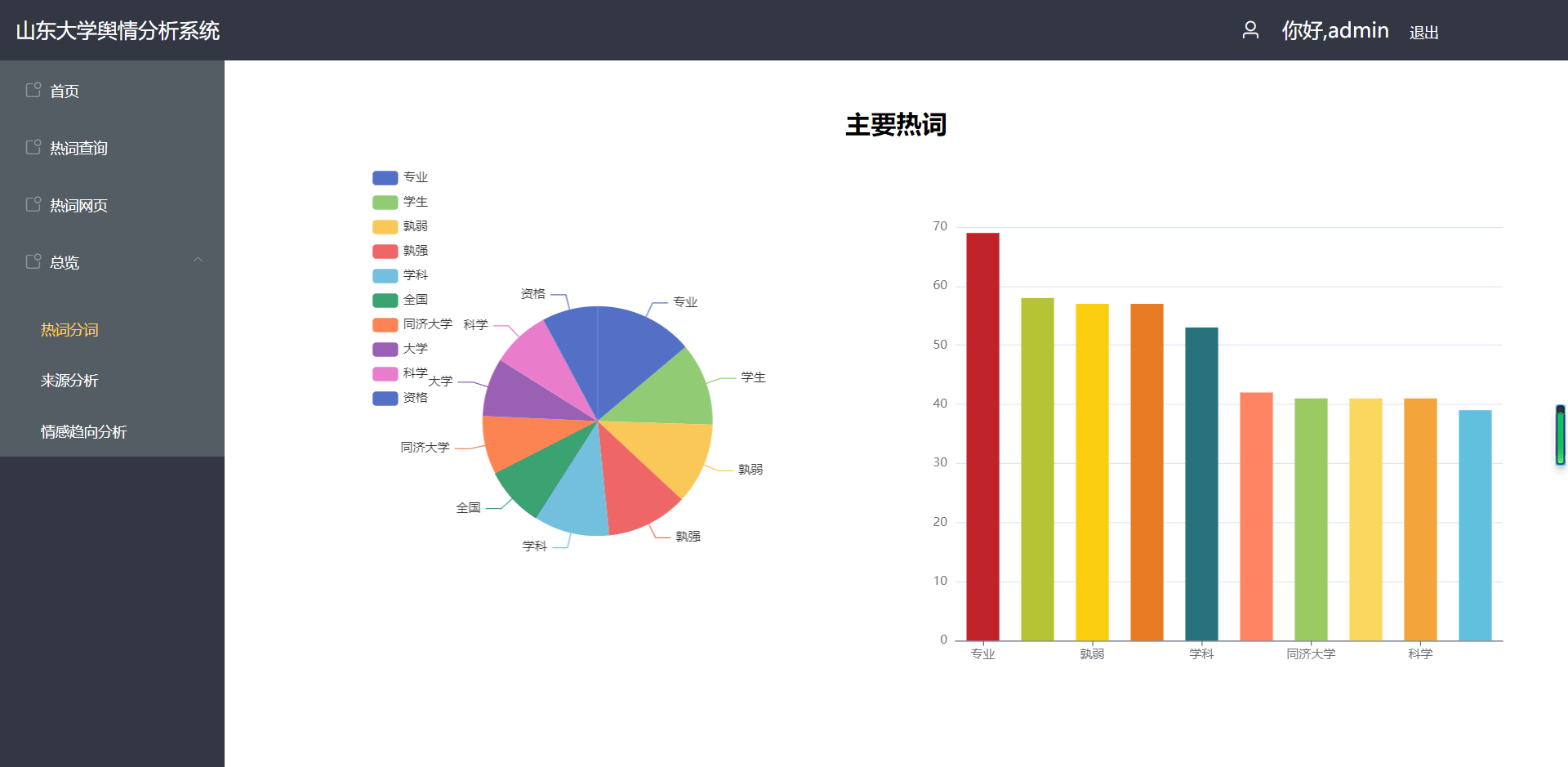
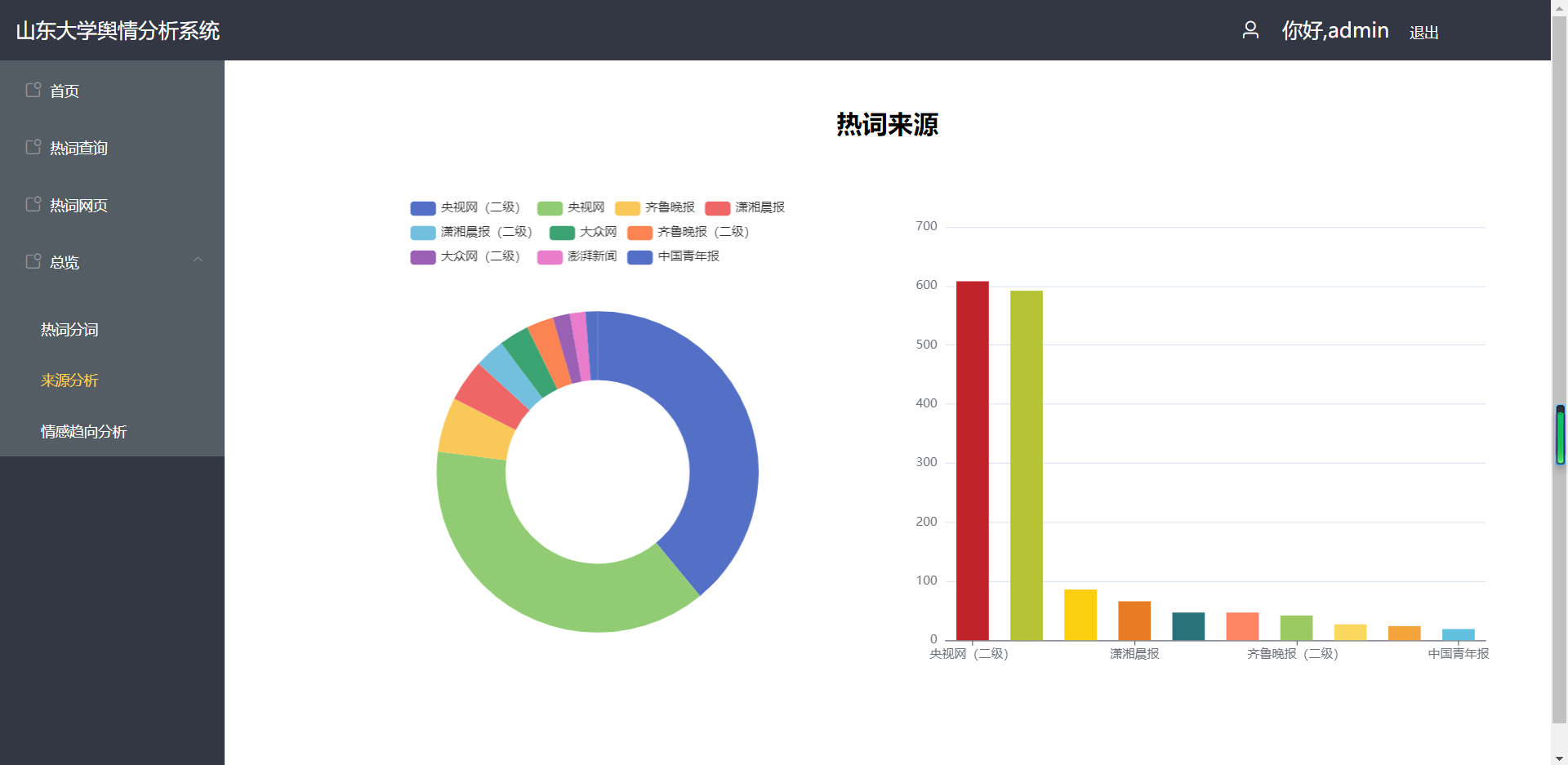
4、网页端——管理员端
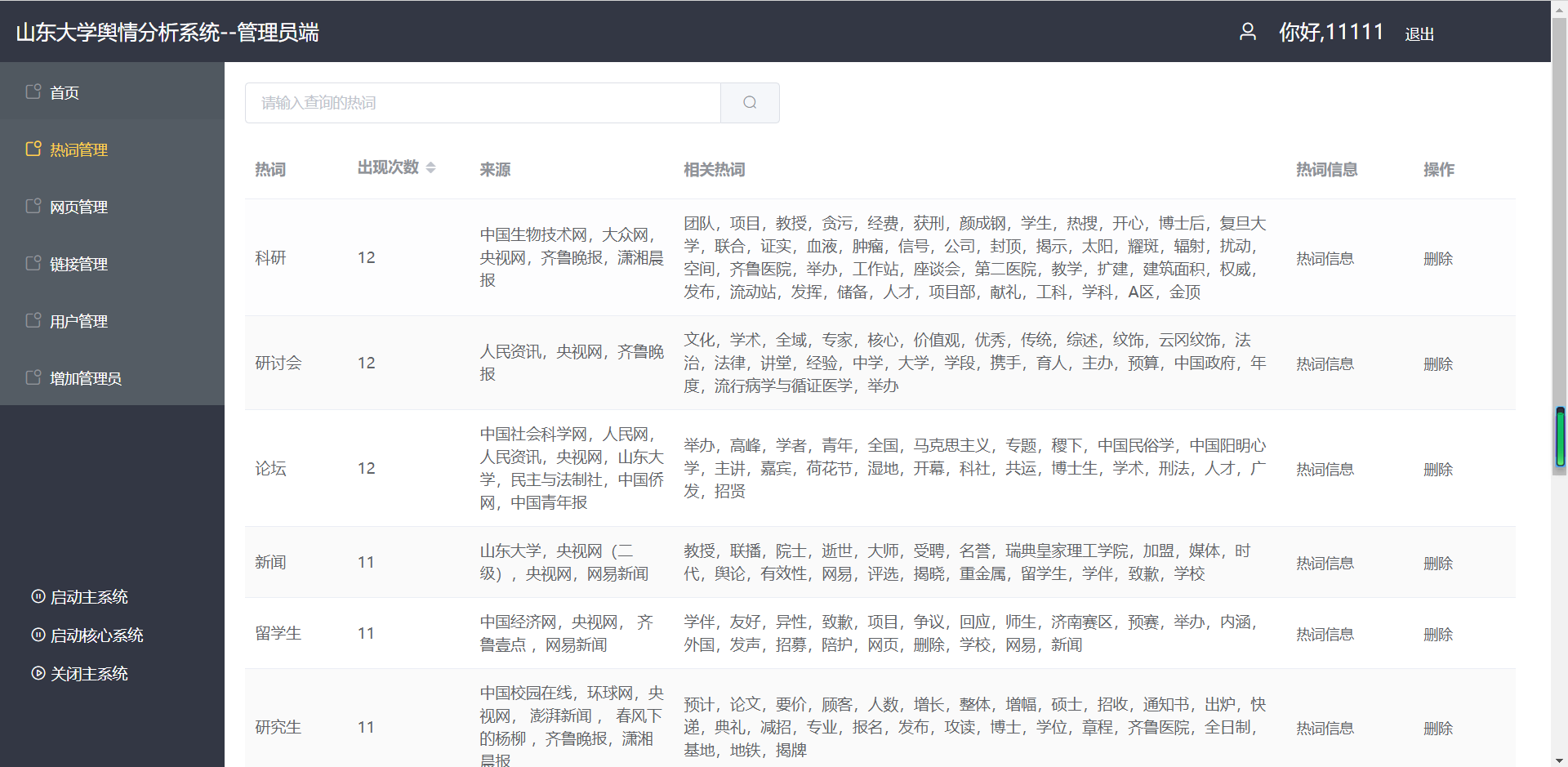
(1)热词管理
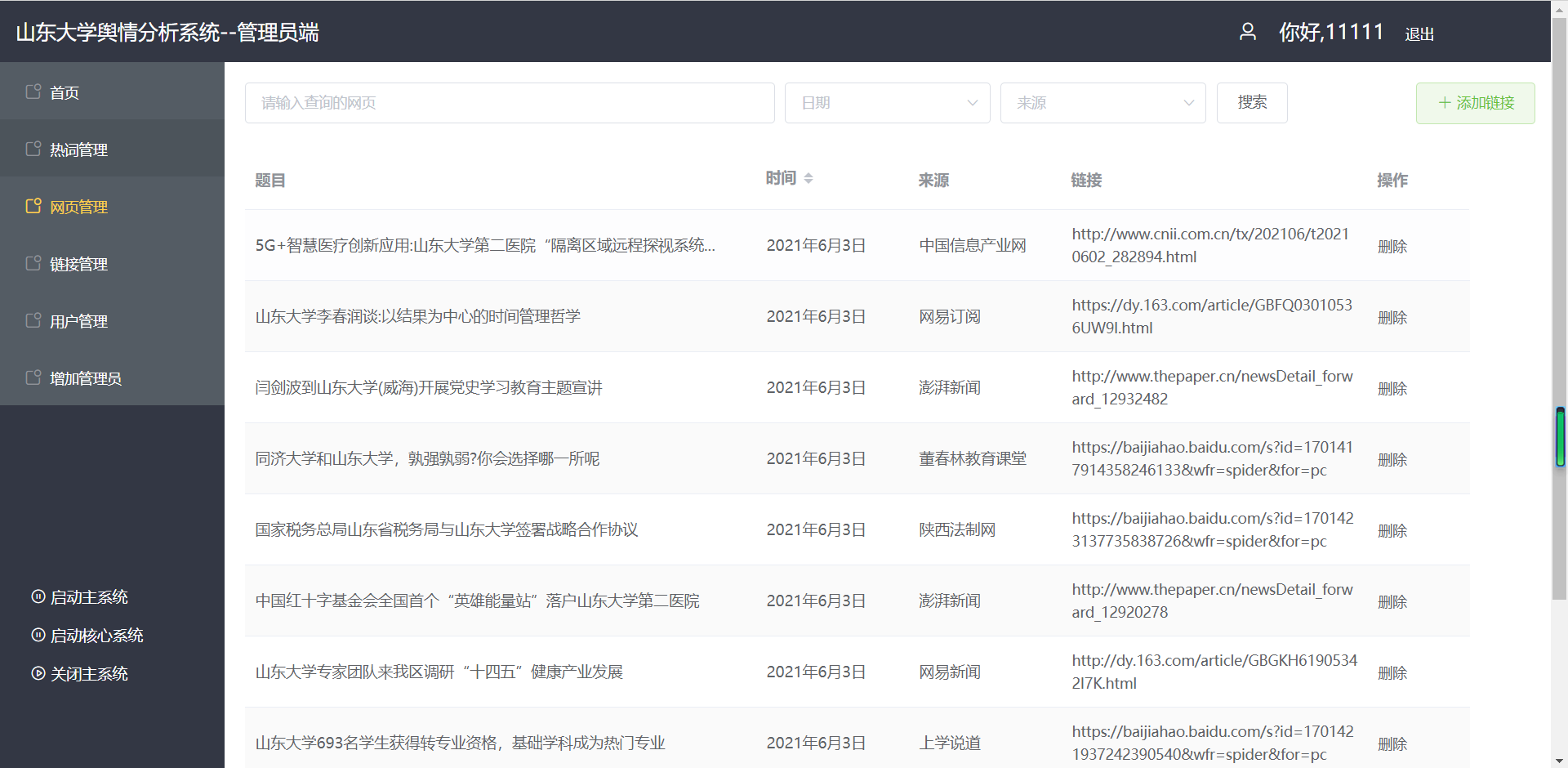
(2)网页管理
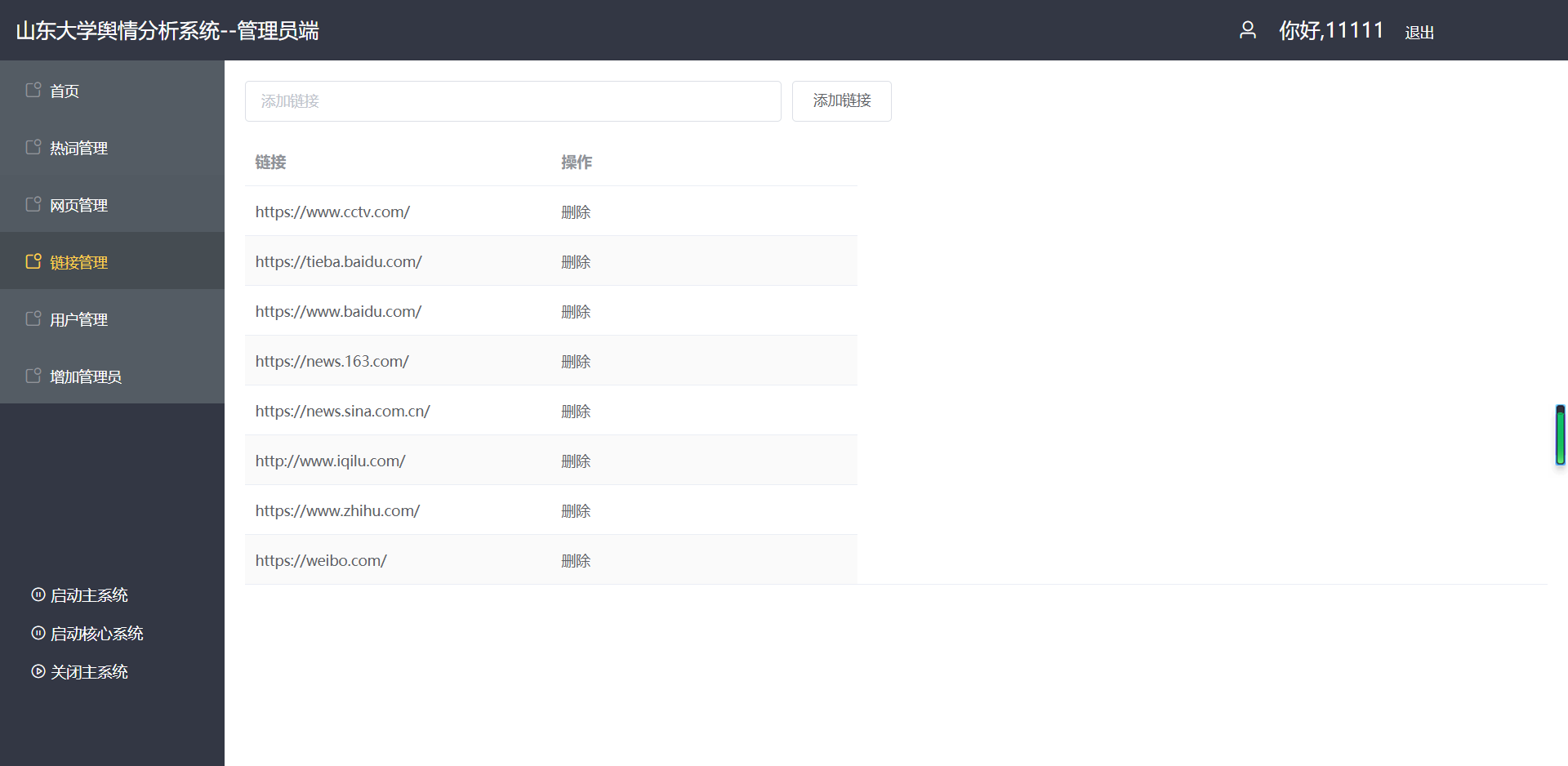
(3)链接管理
(4)用户管理
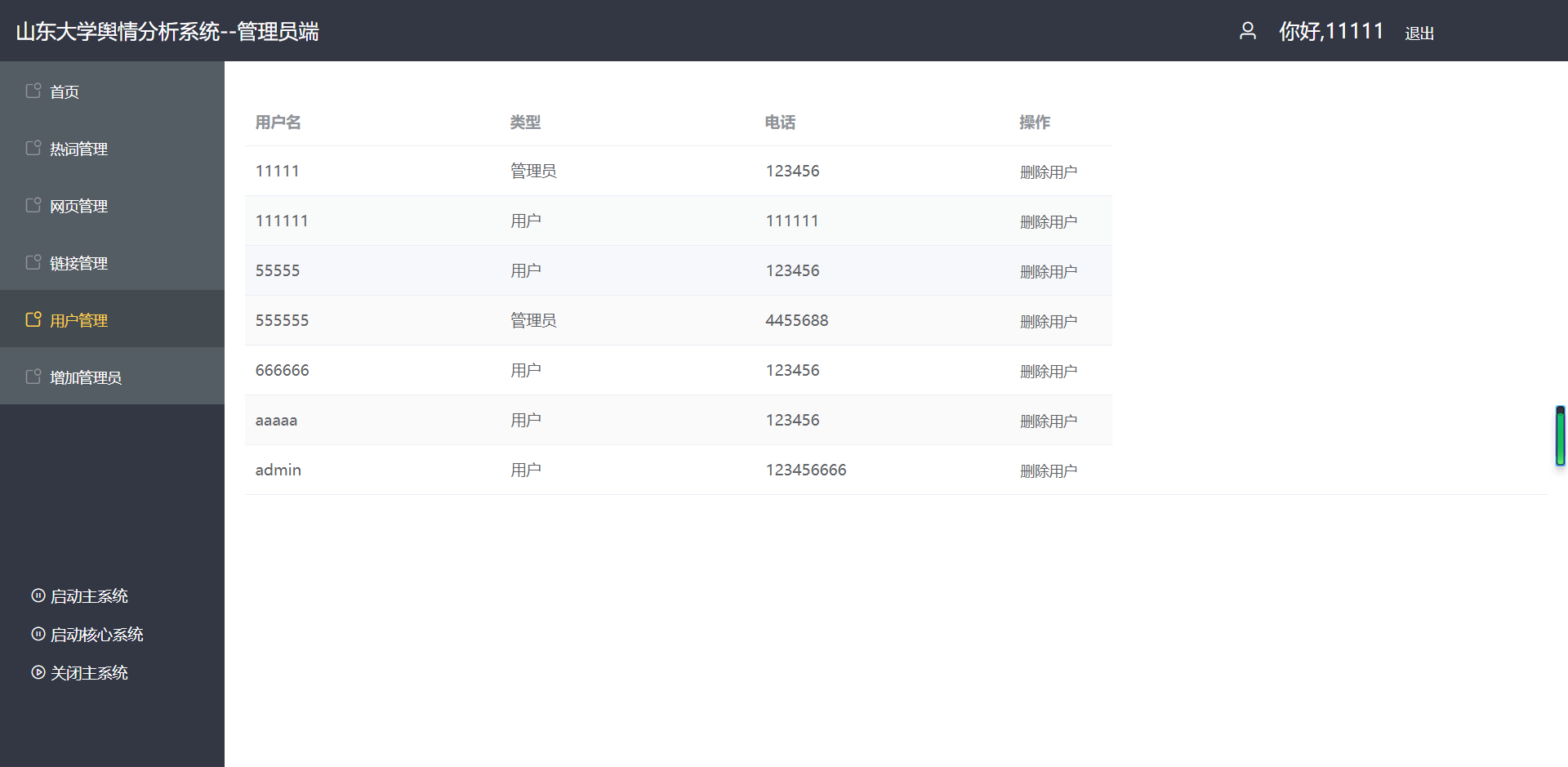
(5)增加管理员

(6)管理后台主系
四、Github项目地址
https://github.com/STK425/django_vue
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191387.html原文链接:https://javaforall.net


