
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
KFold是sklearn中用来做交叉检验的,在sklearn 的版本升级中,KFold被挪了地方。
在sklearn 0.18及以上的版本中,sklearn.cross_validation包被废弃,KFold被挪到了sklearn.model_selection中,本来以为挪就挪了,用法没变就行,结果,,谁用谁知道。
cross_validation.KFold与model_selection.KFold的不同用法
cross_validation.KFold做交叉验证
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(len(y_train_data),5,shuffle=False)
#将训练集切分成5份,做交叉验证
#正则化惩罚项系数
c_param_range = [0.01,0.1,1,10,100]
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
j = 0
for c_param in c_param_range:
print('-------------------------------------------')
print('C parameter: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#循环进行交叉验证
for iteration, indices in enumerate(fold,start=1):
#建立逻辑回归模型,选择正则惩罚类型L1
lr = LogisticRegression(C = c_param, penalty = 'l1')
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)#计算召回率
recall_accs.append(recall_acc)
print('Iteration ', iteration,': recall score = ', recall_acc)
results_table.ix[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('Mean recall score ', np.mean(recall_accs))
print('')
results_table['Mean recall score'] = results_table['Mean recall score'].astype('float64')
best_c = results_table.loc[results_table['Mean recall score'].idxmax()]['C_parameter']
# Finally, we can check which C parameter is the best amongst the chosen.
print('*********************************************************************************')
print('Best model to choose from cross validation is with C parameter = ', best_c)
print('*********************************************************************************')
return best_cmodel_selection.KFold做交叉验证
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
def printing_Kfold_scores(x_train_data,y_train_data):
#将训练集切分成5份,做交叉验证
kf = KFold(n_splits=5,shuffle=False)
kf.get_n_splits(x_train_data)
#正则化惩罚项系数
c_param_range = [0.01,0.1,1,10,100]
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
j = 0
for c_param in c_param_range:
print('-------------------------------------------')
print('C parameter: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#循环进行交叉验证
for iteration, indices in kf.split(x_train_data):
lr = LogisticRegression(C = c_param, penalty = 'l1',solver='liblinear')
lr.fit(x_train_data.iloc[iteration,:],y_train_data.iloc[iteration,:].values.ravel())
y_pred_undersample = lr.predict(x_train_data.iloc[indices,:].values)
recall_acc = recall_score(y_train_data.iloc[indices,:].values,y_pred_undersample)#计算召回率
recall_accs.append(recall_acc)
print('recall score = ', recall_acc)
results_table.ix[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('Mean recall score ', np.mean(recall_accs))
print('')
results_table['Mean recall score'] = results_table['Mean recall score'].astype('float64')
best_c = results_table.loc[results_table['Mean recall score'].idxmax()]['C_parameter']
# Finally, we can check which C parameter is the best amongst the chosen.
print('*********************************************************************************')
print('Best model to choose from cross validation is with C parameter = ', best_c)
print('*********************************************************************************')
return best_c在新版中,将数据切分需要两行代码:kf = KFold(n_splits=5,shuffle=False) 、 kf.get_n_splits(x_train_data),用for iteration, indices in kf.split(x_train_data):取出,看到iteration和indices装的是两段index值,iteration装了五分之四,indices装的是五分之一,如下图
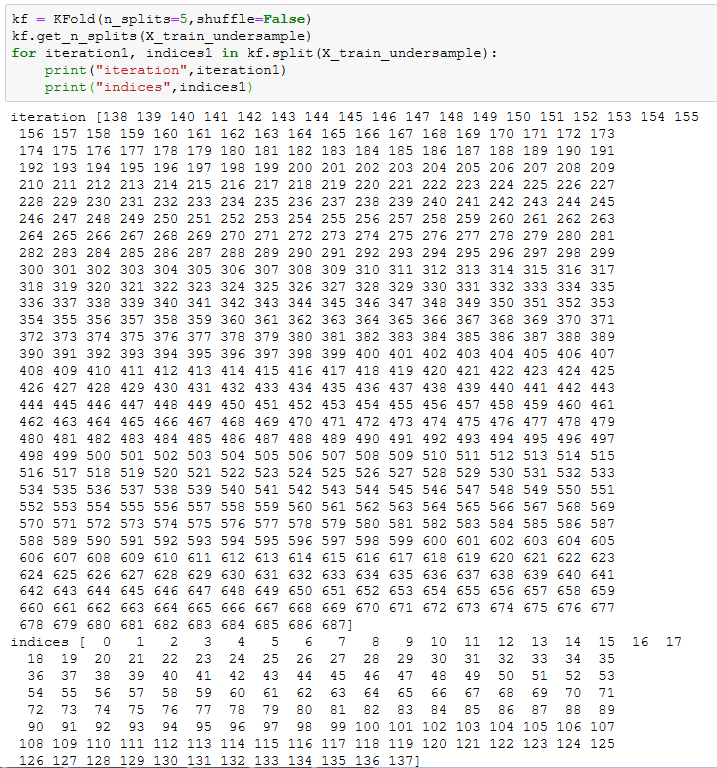

在旧版本中,将数据切分成n份就是一句代码:fold = KFold(len(y_train_data),5,shuffle=False),并且切分后用:for iteration, indices in enumerate(fold,start=1):,取出的iteration是1、2、3、4、5这几个数,indices是上图中两部分的合集
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191394.html原文链接:https://javaforall.net


