
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
参数解释
- class sklearn.model_selection.KFold(n_splits=’warn’, shuffle=False, random_state=None)
- 将训练/测试数据集划分n_splits个互斥子集,每次用其中一个子集当作验证集,剩下的n_splits-1个作为训练集,进行n_splits次训练和测试,得到n_splits个结果
- API文档
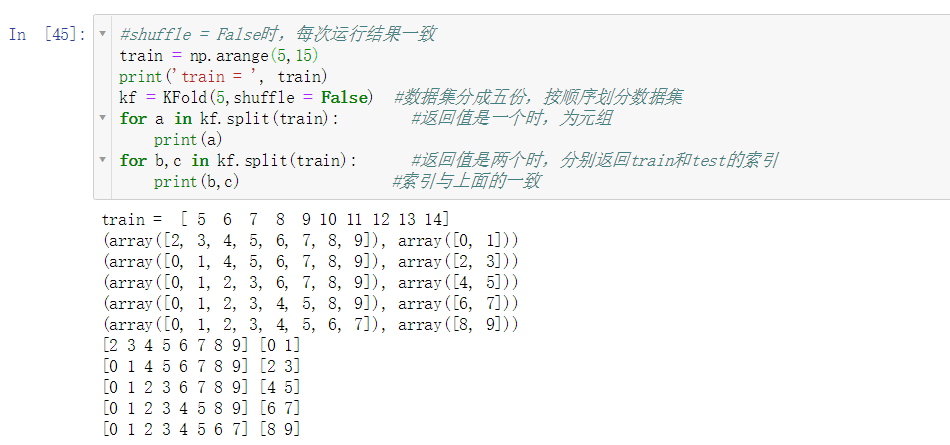
- shuffle = False则不会对传入的训练集打乱,是按顺序进行划分的,每次运行代码得到的划分结果一样
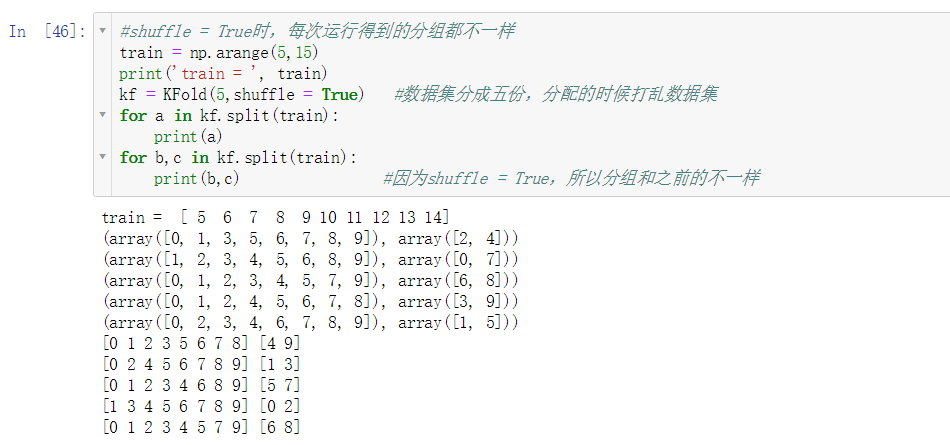
- shuffle = True则对传入的数据集打乱,随机划分n_splits组数据。常与random_state配合使用,以保存重复运行代码得到的随机划分一致
- 函数的用法是fold = KFold(参数设置);fold.split(train_data)。返回值是train和test的索引
用法示例
- 导入模块
import numpy as np
from sklearn.model_selection import KFold
- shuffle = False时,每次运行结果一致

- shuffle = True时,每次运行得到的分组都不一样
- 即想打乱数据,又想每次打乱方式一样

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191584.html原文链接:https://javaforall.net


