
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
LSTM模型
之前一直想要了解一下LSTM模型的想法,看到一些介绍,说里面的各种门,遗忘门,输入门,输出门,是模拟电路的,然后自己就一直很莫名其妙,怎么还有电路什么的,然后就各种一直看不懂。。。现在回过头来仔细的看了看,发现原来也不是很难。不是电路,跟电路一点关系都没有,把它想象成一个神经元就好了,一切问题迎刃而解。嗯,是的,就是这么简单。。。
最后在知乎上找了一篇文章,讲的挺不错的:https://zhuanlan.zhihu.com/p/29927638
讲解
RNN网络结构
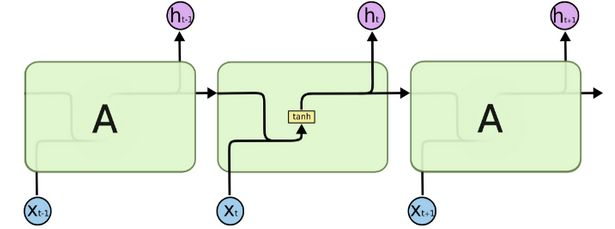

公式: h t = σ ( W h ∗ x t + U h ∗ h t − 1 + b h ) h_t = \sigma(W_h * x_t + U_h * h_{t-1} + b_h) ht=σ(Wh∗xt+Uh∗ht−1+bh)
其中, W h W_h Wh:
LSTM网络结构
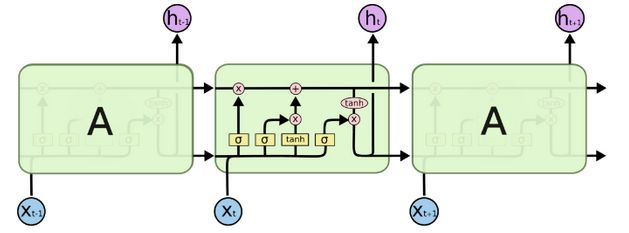
图中 σ , t a n h \sigma, tanh σ,tanh都可以看做是一个神经元,看似复杂,但是相较于RNN只是多了几个神经元而已。下面分析
1. 细胞状态
相较于RNN的隐含状态 h ( t ) h^{(t)} h(t),这里又多了一个细胞状态(cell state) C ( t ) C^{(t)} C(t)

2. 遗忘门

控制是否遗忘,以一定的概率控制是否遗忘上一层的细胞状态:
f ( t ) = σ ( W f ∗ h t − 1 + U f ∗ x ( t ) + b f ) f^{(t)} = \sigma(W_f*h_{t-1} + U_f * x^{(t)} + b_f) f(t)=σ(Wf∗ht−1+Uf∗x(t)+bf)
其中, f ( t ) f^{(t)} f(t)是遗忘门的输出,本身是 s i g m o i d sigmoid sigmoid函数,输出是(0, 1)的值,表示一定概率的遗忘细胞状态。
3. 输入门
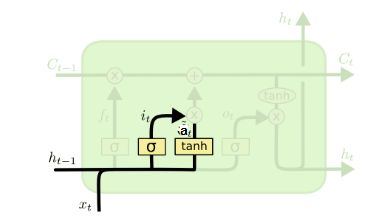
用来处理输入,最终目的是为了更新细胞状态
i ( t ) = σ ( W i ∗ h t − 1 + U i ∗ x i + b i ) i^{(t)} = \sigma(W_i * h_{t-1} + U_i * x_i + b_i) i(t)=σ(Wi∗ht−1+Ui∗xi+bi)
a ( t ) = t a n h ( W a ∗ h t − 1 + U a ∗ x i + b a ) a^{(t)} = tanh(W_a * h_{t-1} + U_a * x_i + b_a) a(t)=tanh(Wa∗ht−1+Ua∗xi+ba)
4. 细胞状态更新
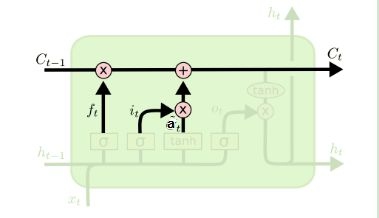
C ( t ) = f ( t ) ⨀ C ( t − 1 ) + i ( t ) ⨀ a ( t ) C^{(t)} = f^{(t)} \bigodot C^{(t-1)} + i^{(t)} \bigodot a^{(t)} C(t)=f(t)⨀C(t−1)+i(t)⨀a(t)
其中, ⨀ \bigodot ⨀表示 H a r a m a r d Haramard Haramard积。
5. 输出门
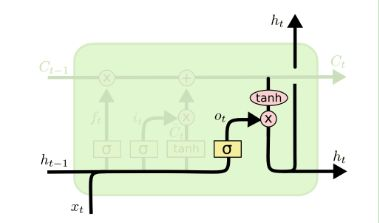
o ( t ) = σ ( W o ∗ h ( t − 1 ) + U o ∗ x ( t ) + b o ) o^{(t)} = \sigma(W_o*h^{(t-1)} + U_o * x^{(t)} + b_o) o(t)=σ(Wo∗h(t−1)+Uo∗x(t)+bo)
h ( t ) = o ( t ) ⨂ t a n h ( C ( t ) ) h^{(t)} = o^{(t)} \bigotimes tanh(C^{(t)}) h(t)=o(t)⨂tanh(C(t))
整个结构就这样介绍完了。就是几个神经单元。挺简单的吧。
其实可以换一个角度来看,三个 σ \sigma σ函数实际上就是三个忘记,忘记上一个细胞的状态,忘记当前的输入,忘记隐藏层的输出。中间的 t a n h tanh tanh就是一个RNN结构
为什么使用LSTM
由于RNN也有梯度消失的问题,因此很难处理长序列的数据,对RNN做了改进,得到了RNN的特例LSTM(Long Short-Term Memory),它可以避免常规RNN的梯度消失,因此在工业界得到了广泛的应用
比较好的LSTM文章
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/195271.html原文链接:https://javaforall.net


