
引言
在有向图相关的实际应用中,有向环特别重要。一幅图可能含有大量的环,通常,我们一般只关注它们是否存在。
有关图的概念可参考博文数据结构之图的概述
在学习环之前,我们一起来学习下调度问题。
调度问题
给定一组任务并安排它们的执行顺序,限制条件为这些任务的执行方法、起始时间以及任务的消耗等。最重要的一种限制条件叫做优先级限制,它指定了哪些任务必须在哪些任务之前完成。不同类型的限制条件会产生不同难度的调度问题。

 以一个正在安排课程的大学生为例,有些课程是其他课程的先导课程。如上图所示。
以一个正在安排课程的大学生为例,有些课程是其他课程的先导课程。如上图所示。
比如要学习机器学习(Machine Learning),得先学习人工智能(Artificial Intelligence)。
再假设该同学一次只能选修一门课程,就会遇到下面的问题:
优先级限制下的调度问题:在满足限制条件的情况下如何安排并完成所有任务。我们可以画出一张有向图,顶点对应任务(通过数组索引来表示课程),有向边对应优先级顺序。
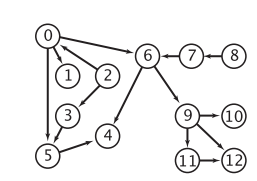
上图9代表人工智能,11代表机器学习。
而在有向图中,优先级限制下的调度问题等价于拓扑排序:
拓扑排序:给定一副有向图,将所有的顶点排序,使得所有的有向边均从排在前面的顶点指向排在后面的顶点。

上图为示例的拓扑排序,所有的边都是向下的。按照这个顺序,该同学可以在满足先导课程限制的条件下选修完所有课程。
有向图中的环
如果任务x必须在任务y之前完成:x→y,而y→z,同时z→x。那么就会形成一个环:x→y→z→x。如果一个有优先级限制的问题中存在有向环,那么这个问题肯定是无解的。因此我们需要首先进行有向环检测。
有向环检测:检测给定的有向图是否包含环,若有环,通常只需找出一个即可。
有向无环图(DAG):不含环的有向图
可以转换为检查一副有向图是否为有向无环图。
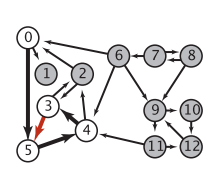
对课程图进行一些修改,增加一些环如上所示。
寻找环利用了DFS方法,维护一个递归调用期间已访问的顶点的栈,若(在递归调用期间,通过判断onStack标记数组)两次访问了某个顶点,则说明有环;若DFS递归调用完毕,说明无环。
该递归调用期间只是递归dfs调用它的邻接顶点期间(如果有邻接顶点,它的邻接顶点也会执行同样的过程,所以会越来越深),一旦递归完它的所有邻接顶点,会把该顶点从
onStack数组中移除
我们暂且关注0-5六个顶点。执行图解如下:
dfs(1),将1标记为已访问,并将1的调用栈标记置为true,因为1无邻接点,dfs(1)调用完毕,并将1的调用栈标记置为false(在图中用空白表示false),回退到dfs(0)

递归调用0的下一个邻接点5,将5的上一节点置为0
递归调用dfs(5)
将5标记为已访问,并将5的调用栈标记置为true
 递归的访问
递归的访问5的邻接点4。观察到4没有访问过,将其上一节点置为5,然后调用
dfs(4),将4标记为已访问,并将4的调用栈标记置为true,递归的访问4的邻接点2,观察到2没有访问过
 将
将2上一节点置为4,递归调用
dfs(2)
将2标记为已访问,并将2的调用栈标记置为true,递归的访问2的邻接点0,观察到0已经访问过,且0在调用栈中,因此发现了环。 此时已经得出结果可以返回了,但别急,我们将环的路径存入调用栈中,方便后面输出。

cycle环栈输入顺序为:2,4,5,0
检测有向图是否有环代码
package com.algorithms.graph; import com.algorithms.stack.Stack; / * @author yjw * @date 2019/5/20/020 */ public class DirectedCycle {
private boolean[] marked; private int[] edgeTo; / * 有向环中的所有顶点(如果存在) */ private Stack<Integer> cycle; / * 保存递归调用期间栈上的所有顶点 */ private boolean[] onStack; public DirectedCycle(DiGraph g) {
marked = new boolean[g.vertexNum()]; edgeTo = new int[g.vertexNum()]; onStack = new boolean[g.vertexNum()]; for (int v = 0; v < g.vertexNum(); v++) {
if (!marked[v]) {
dfs(g, v); } } } private void dfs(DiGraph g, int v) {
marked[v] = true; onStack[v] = true; for (int w : g.adj(v)) {
if (hasCycle()) {
//有环直接退出 return; } else if (!marked[w]) {
edgeTo[w] = v; dfs(g, w); } else if (onStack[w]) {
//如果w已经在栈中,说明再一次访问到了w,因此此时发现了环 cycle = new Stack<>(); for (int x = v; x != w; x = edgeTo[x]) {
cycle.push(x); } cycle.push(w); cycle.push(v); } } onStack[v] = false; } public boolean hasCycle() {
return cycle != null; } public Iterable<Integer> cycle(int v) {
return cycle; } public static void main(String[] args) {
DiGraph g = new DiGraph(13); g.addDiEdges(0, 5, 1); g.addDiEdges(2, 3, 0); g.addDiEdges(3, 2, 5); g.addDiEdges(4, 3, 2); g.addDiEdges(5, 4); g.addDiEdges(6, 0, 4, 9); g.addDiEdges(7, 6, 8); g.addDiEdges(8, 7, 9); g.addDiEdges(9, 10, 11); g.addDiEdges(10, 12); g.addDiEdges(11, 4, 12); g.addDiEdges(12, 9); //System.out.println(g); DirectedCycle dc = new DirectedCycle(g); if (dc.hasCycle()) {
for (int w : dc.cycle) {
System.out.print(w + "->"); } } } } 顶点的深度优先顺序
图的深度优先搜索只会访问每个顶点一次,如果将dfs(int v)的参数顶点v保存在一个数据结构中,
遍历这个数据结构实际上就能访问图中的所有顶点。
遍历的顺序取决于该数据结构的性质(栈的先进后出、队列的先进先出),以及是在递归调用之前还是之后存入该数据结构。
常见的的3种遍历顺序如下:
- 前序:在递归调用之前将顶点加入队列
- 后序:在递归调用之后将顶点加入队列
- 逆后序:在递归调用之后将顶点压入栈
 我们以上面这个图为例,对该图进行3种遍历:
我们以上面这个图为例,对该图进行3种遍历:

pre和post是队列,reversePost是栈,红色元素为最近插入的元素。从左到右,可以看到队列是先进先出,而栈是先进后出。
分析下执行过程,首先调用dfs(0),0的邻接点为{2},在递归调用dfs(2)之前,将0入前序队列;
调用dfs(2),2的邻接点为{0,1,3},因为0刚才已经访问过,不会递归调用0,因此会继续递归调用1(将它入前序队列),它没有邻接点,递归dfs调用1的邻接点完毕,将1入后序队列;
然后继续调用2的下一个邻接点3,而3又会导致dfs(4)和dfs(5),该两个顶点都没有邻接点,因此很快就可以返回,3的所有邻接点递归调用完毕,到了3 done。后面也是一样,2和0依次调用完毕。
有向图的前序、后序遍历代码
package com.algorithms.graph; import com.algorithms.queue.Queue; import com.algorithms.stack.Stack; / * 顶点的深度优先顺序 * @author yjw * @date 2019/5/21/021 */ public class DepthFirstOrder {
private boolean[] marked; / * 所有顶点的前序序列 */ private Queue<Integer> pre; / * 所有顶点的后序序列 */ private Queue<Integer> post; / * 所有顶点的逆后序序列 */ private Stack<Integer> reversePost; public DepthFirstOrder(DiGraph g) {
pre = new Queue<>(); post = new Queue<>(); reversePost = new Stack<>(); marked = new boolean[g.vertexNum()]; for (int v = 0; v < g.vertexNum(); v++) {
if (!marked[v]) {
dfs(g,v); } } } private void dfs(DiGraph g, int v) {
marked[v] = true; //前序:递归调用dfs之前将顶点加入队列 pre.enqueue(v); for (int w : g.adj(v)) {
if (!marked[w]) {
//递归调用dfs dfs(g, w); } } //遍历完所有的邻接点后(递归调用dfs之后) //后序:递归调用dfs之后将顶点加入队列 post.enqueue(v); //逆后序:在递归调用dfs之后将顶点压入栈 reversePost.push(v); } public Iterable<Integer> pre() {
return pre; } public Iterable<Integer> post() {
return post; } public Iterable<Integer> reversePost() {
return reversePost; } public static void main(String[] args) {
DiGraph g = new DiGraph(6); g.addEdge(0,2,2,0,2,1,2,3,3,2,3,4,3,5); DepthFirstOrder dfo = new DepthFirstOrder(g); for (Integer v: dfo.pre()){
System.out.print(v + " "); } System.out.println(); for (Integer v: dfo.post()){
System.out.print(v + " "); } System.out.println(); for (Integer v: dfo.reversePost()){
System.out.print(v + " "); } System.out.println(); / * 输出: * 0 2 1 3 4 5 * 1 4 5 3 2 0 * 0 2 3 5 4 1 */ } } 拓扑排序
回顾一下拓扑排序的描述
拓扑排序:给定一副有向图,将所有的顶点排序,使得所有的有向边均从排在前面的顶点指向排在后面的顶点。
上图为示例的拓扑排序,所有的边都是向下的。按照这个顺序,可以在满足先导课程限制的条件下选修完所有课程。
一副有向无环图的拓扑排序即为所有顶点的逆后序排列
package com.algorithms.graph; / * 有向无环图的拓扑排序即为所有顶点的逆后序排列 * * @author yjw * @date 2019/5/21/021 */ public class Topological {
//顶点的拓扑顺序 private Iterable<Integer> order; public Topological(DiGraph g) {
//首先检测是否有环 DirectedCycle cycle = new DirectedCycle(g); if (!cycle.hasCycle()) {
DepthFirstOrder dfs = new DepthFirstOrder(g); order = dfs.reversePost(); } } public Iterable<Integer> order() {
return order; } / * 是否为有向无环图 * * @return */ public boolean isDAG() {
return order != null; } public static void main(String[] args) {
DiGraph g = new DiGraph(13); g.addDiEdges(0, 1, 5, 6); g.addDiEdges(2, 0, 3); g.addDiEdges(3, 5); g.addDiEdges(5, 4); g.addDiEdges(6, 4, 9); g.addDiEdges(7, 6); g.addDiEdges(8, 7); g.addDiEdges(9, 10, 11,12); g.addDiEdges(11, 12); Topological tp = new Topological(g); if (tp.isDAG()) {
for (Integer v : tp.order) {
System.out.print(v + " "); } } } } 发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/199189.html原文链接:https://javaforall.net


