
一、内存溢出和内存泄露
下面具体介绍。
1.1 内存溢出
- JVM内存过小。
- 程序不严密,产生了过多的垃圾。
程序体现
一般情况下,在程序上的体现为:
- 内存中加载的数据量过于庞大,如一次从数据库取出过多数据。
- 集合类中有对对象的引用,使用完后未清空,使得JVM不能回收。
- 代码中存在死循环或循环产生过多重复的对象实体。
- 使用的第三方软件中的BUG。
- 启动参数内存值设定的过小。
错误提示
此错误常见的错误提示:tomcat:java.lang.OutOfMemoryError: PermGen spacetomcat:java.lang.OutOfMemoryError: Java heap spaceweblogic:Root cause of ServletException java.lang.OutOfMemoryErrorresin:java.lang.OutOfMemoryErrorjava:java.lang.OutOfMemoryError
解决方法
- 增加JVM的内存大小
对于tomcat容器,找到tomcat在电脑中的安装目录,进入这个目录,然后进入bin目录中,在window环境下找到bin目录中的catalina.bat,在linux环境下找到catalina.sh。
编辑catalina.bat文件,找到JAVA_OPTS(具体来说是set "JAVA_OPTS=%JAVA_OPTS% %LOGGING_MANAGER%")这个选项的位置,这个参数是Java启动的时候,需要的启动参数。
也可以在操作系统的环境变量中对JAVA_OPTS进行设置,因为tomcat在启动的时候,也会读取操作系统中的环境变量的值,进行加载。
如果是修改了操作系统的环境变量,需要重启机器,再重启tomcat,如果修改的是tomcat配置文件,需要将配置文件保存,然后重启tomcat,设置就能生效了。 - 优化程序,释放垃圾
主要思路就是避免程序体现上出现的情况。避免死循环,防止一次载入太多的数据,提高程序健壮型及时释放。因此,从根本上解决Java内存溢出的唯一方法就是修改程序,及时地释放没用的对象,释放内存空间。
1.2 内存泄露
关于内存泄露的处理页就是提高程序的健壮型,因为内存泄露是纯代码层面的问题。
1.3 内存溢出和内存泄露的联系
二、一个Java内存泄漏的排查案例
某个业务系统在一段时间突然变慢,我们怀疑是因为出现内存泄露问题导致的,于是踏上排查之路。
2.1 确定频繁Full GC现象
 jstat执行结果
jstat执行结果
查询结果表明:这台服务器的新生代Eden区(E,表示Eden)使用了28.30%(最后)的空间,两个Survivor区(S0、S1,表示Survivor0、Survivor1)分别是0和8.93%,老年代(O,表示Old)使用了87.33%。程序运行以来共发生Minor GC(YGC,表示Young GC)101次,总耗时1.961秒,发生Full GC(FGC,表示Full GC)7次,Full GC总耗时3.022秒,总的耗时(GCT,表示GC Time)为4.983秒。
2.2 找出导致频繁Full GC的原因
存活对象
按照一位IT友的说法,数据不正常,十有八九就是泄露的。在我这个图上对象还是挺正常的。
我在网上找了一位博友的不正常数据,如下:
image.png
可以看出HashTable中的元素有5000多万,占用内存大约1.5G的样子。这肯定不正常。
2.3 定位到代码
定位带代码,有很多种方法,比如前面提到的通过MAT查看Histogram即可找出是哪块代码。——我以前是使用这个方法。 也可以使用BTrace,我没有使用过。
举例:
一台生产环境机器每次运行几天之后就会莫名其妙的宕机,分析日志之后发现在tomcat刚启动的时候内存占用比较少,但是运行个几天之后内存占用越来越大,通过jmap命令可以查询到一些大对象引用没有被及时GC,这里就要求解决内存泄露的问题。
1. 登录linux服务器,获取tomcat的pid,命令:
- ps -ef|grep java

2. 利用jmap初步分析内存映射,命令:
- jmap -histo:live 3514 | head -7

第2行是我们业务系统的对象,通过这个对象的引用可以初步分析出到底是哪里出现了引用未被垃圾回收收集,通知开发人员优化相关代码。
3. 如果上面一步还无法定位到关键信息,那么需要拿到heap dump,生成离线文件,做进一步分析,命令:
- jmap -dump:live,format=b,file=heap.hprof 3514
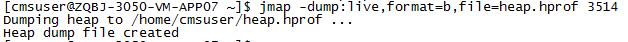
4. 拿到heap dump文件,利用eclipse插件MAT来分析heap profile。
a. 安装MAT插件
b. 在eclipse里切换到Memory Analysis视图
c. 用MAT打开heap profile文件。
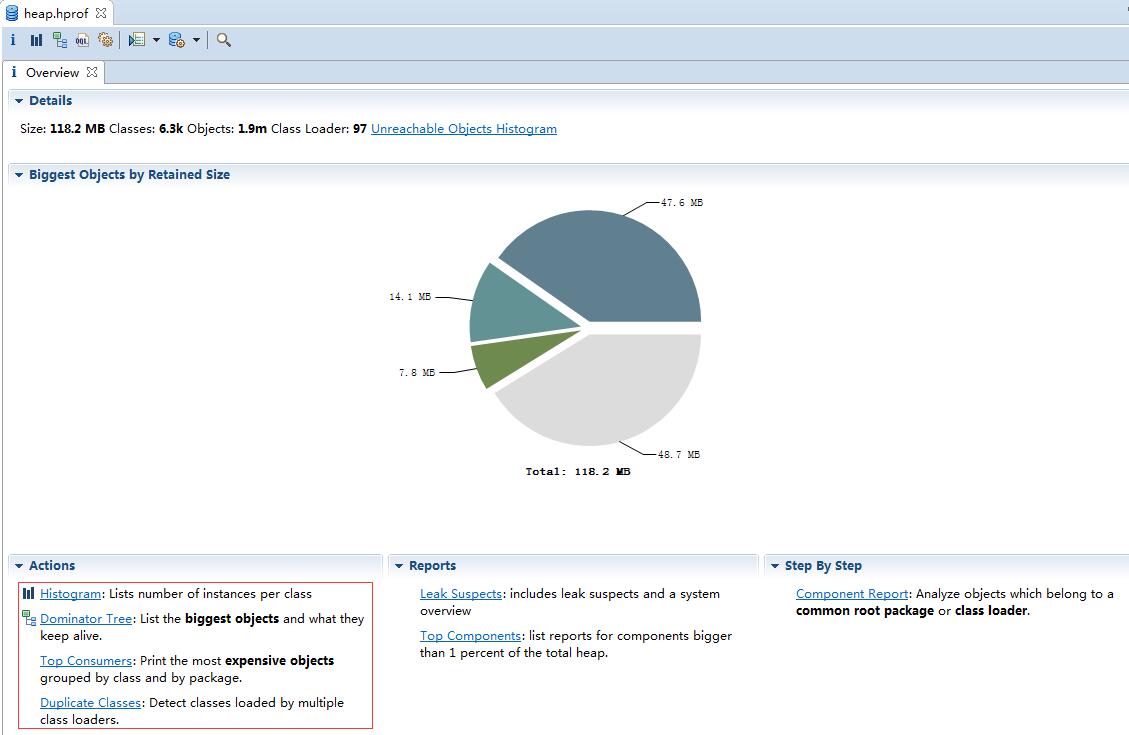
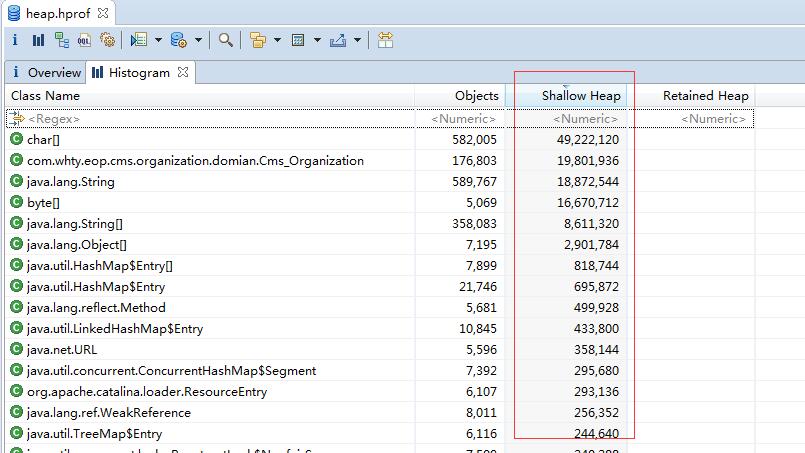
直接看到下面Action窗口,有4种Action来分析heap profile,介绍其中最常用的2种:
– Histogram:这个使用的最多,跟上面的jmap -histo 命令类似,只是在MAT里面可以用GUI来展示应用系统各个类产生的实例。
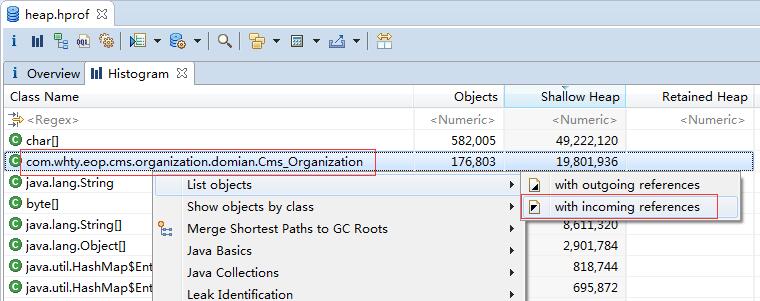
分析引用栈,找到无效引用,打开源码:
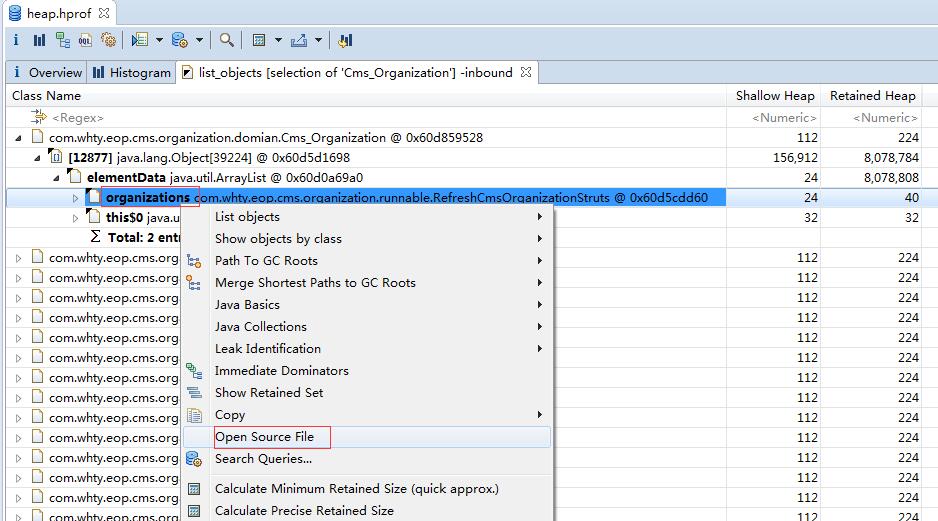
有问题的源码如下:
- public class RefreshCmsOrganizationStruts implements Runnable{
- private final static Logger logger = Logger.getLogger(RefreshCmsOrganizationStruts.class);
- private List
organizations;
- private OrganizationDao organizationDao = (OrganizationDao) WebContentBean
- .getInstance().getBean(“organizationDao”);
- public RefreshCmsOrganizationStruts(List
organizations) {
- this.organizations = organizations;
- }
- public void run() {
- Iterator
iter = organizations.iterator();
- Cms_Organization organization = null;
- while (iter.hasNext()) {
- organization = iter.next();
- synchronized (organization) {
- try {
- organizationDao.refreshCmsOrganizationStrutsInfo(organization.getOrgaId());
- organizationDao.refreshCmsOrganizationResourceInfo(organization.getOrgaId());
- organizationDao.sleep();
- } catch (Exception e) {
- logger.debug(“RefreshCmsOrganizationStruts organization = “ + organization.getOrgaId(), e);
- }
- }
- }
- }
- }
分析源码,定时任务定时调用,每次调用生成10个线程处理,而它又使用了非线程安全的List对象,导致List对象无法被GC收集,所以这里将List替换为CopyOnWriteArrayList 。
– Dominator Tree:这个使用的也比较多,显示大对象的占用率。
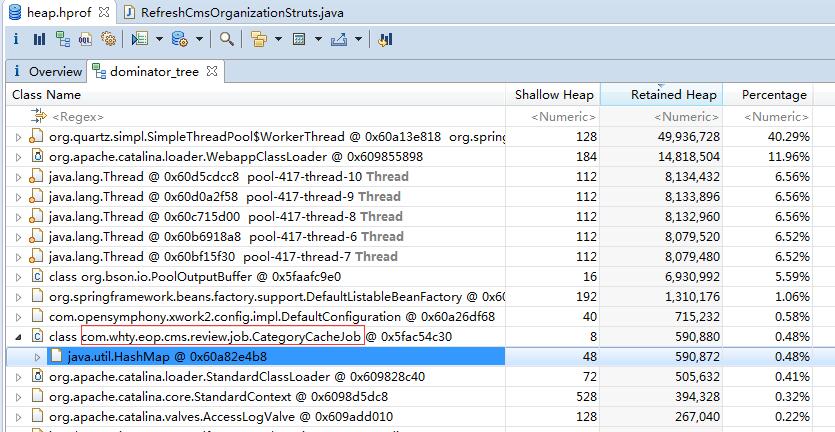
同样的打开源码:
- public class CategoryCacheJob extends QuartzJobBean implements StatefulJob {
- private static final Logger LOGGER = Logger.getLogger(CategoryCacheJob.class);
- public static Map
> cacheMap =
>();
- @Override
- protected void executeInternal(JobExecutionContext ctx) throws JobExecutionException {
- try {
- //LOGGER.info(“======= 缓存编目树开始 =======”);
- MongoBaseDao mongoBaseDao = (MongoBaseDao) BeanLocator.getInstance().getBean(“mongoBaseDao”);
- MongoOperations mongoOperations = mongoBaseDao.getMongoOperations();
- /*
- LOGGER.info(“1.缓存基础教育编目树”);
- Query query = Query.query(Criteria.where(“isDel”).is(“0”).and(“categoryType”).is(“F”));
- query.sort().on(“orderNo”, Order.ASCENDING);
- List
list = mongoOperations.find(query, Cms_Category.class);
- String key = query.toString().replaceAll(“\\{|\\}|\\p{Cntrl}|\\p{Space}”, “”);
- key += “_CategoryCacheJob”;
- cacheMap.put(key, list);
- */
- //LOGGER.info(“2.缓存职业教育编目树”);
- Query query2 = Query.query(Criteria.where(“isDel”).is(“0”).and(“categoryType”).in(“JMP”,“JHP”));
- query2.sort().on(“orderNo”, Order.ASCENDING);
- List
list2 = mongoOperations.find(query2, Cms_Category.
class
);
- String key2 = query2.toString().replaceAll(“\\{|\\}|\\p{Cntrl}|\\p{Space}”, “”);
- key2 += “_CategoryCacheJob”;
- cacheMap.put(key2, list2);
- //LOGGER.info(“3.缓存专题教育编目树”);
- Query query3 = Query.query(Criteria.where(“isDel”).is(“0”).and(“categoryType”).is(“JS”));
- query3.sort().on(“orderNo”, Order.ASCENDING);
- List
list3 = mongoOperations.find(query3, Cms_Category.
class
);
- String key3 = query3.toString().replaceAll(“\\{|\\}|\\p{Cntrl}|\\p{Space}”, “”);
- key3 += “_CategoryCacheJob”;
- cacheMap.put(key3, list3);
- //LOGGER.info(“======= 缓存编目树结束 =======”);
- } catch(Exception ex) {
- LOGGER.error(ex.getMessage(), ex);
- LOGGER.info(“======= 缓存编目树出错 =======”);
- }
- }
- }
这里的HashMap也有问题:居然使用定时任务,在容器启动之后定时将数据放到Map里面做缓存?这里修改这部分代码,替换为使用memcached缓存即可。
内存泄漏的原因分析,总结出来只有一条:存在无效的引用!良好的编码规范以及合理使用设计模式有助于解决此类问题。
线程安全的CopyOnWriteArrayList介绍
先写一段代码证明CopyOnWriteArrayList确实是线程安全的。
ReadThread.java
import java.util.List;
public class ReadThread implements Runnable {
private List
list;
public
ReadThread(List
list) {
this.list = list; }
@Override
public
void
run() {
for (Integer ele : list) { System.out.println(
"ReadThread:"+ele); } } }
WriteThread.java
import java.util.List;
public class WriteThread implements Runnable {
private List
list;
public
WriteThread(List
list) {
this.list = list; }
@Override
public
void
run() {
this.list.add(
9); } }
TestCopyOnWriteArrayList.java
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestCopyOnWriteArrayList {
private void test() {
//1、初始化CopyOnWriteArrayList
List
tempList = Arrays.asList(
new Integer [] {
1,
2}); CopyOnWriteArrayList
copyList =
new CopyOnWriteArrayList<>(tempList);
//2、模拟多线程对list进行读和写 ExecutorService executorService = Executors.newFixedThreadPool(
10); executorService.execute(
new ReadThread(copyList)); executorService.execute(
new WriteThread(copyList)); executorService.execute(
new WriteThread(copyList)); executorService.execute(
new WriteThread(copyList)); executorService.execute(
new ReadThread(copyList)); executorService.execute(
new WriteThread(copyList)); executorService.execute(
new ReadThread(copyList)); executorService.execute(
new WriteThread(copyList)); System.out.println(
"copyList size:"+copyList.size()); }
public
static
void
main(String[] args) {
new TestCopyOnWriteArrayList().test(); } }
运行上面的代码,没有报出
java.util.ConcurrentModificationException说明了CopyOnWriteArrayList并发多线程的环境下,仍然能很好的工作。
CopyOnWriteArrayList如何做到线程安全的
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
当有新元素加入的时候,如下图,创建新数组,并往新数组中加入一个新元素,这个时候,array这个引用仍然是指向原数组的。

当元素在新数组添加成功后,将array这个引用指向新数组。

CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。
CopyOnWriteArrayList的add操作的源代码如下:
public boolean add(E e) {
//1、先加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//2、拷贝数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
//3、将元素加入到新数组中
newElements[len] = e;
//4、将array引用指向到新数组
setArray(newElements);
return true;
} finally {
//5、解锁
lock.unlock();
}
}可见,CopyOnWriteArrayList的读操作是可以不用加锁的。
CopyOnWriteArrayList的使用场景
通过上面的分析,CopyOnWriteArrayList 有几个缺点:
1、由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
2、不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
CopyOnWriteArrayList透露的思想
3、使用另外开辟空间的思路,来解决并发冲突
Eclipse Memory Analyzer 进行堆转储文件分析
简单的说一下使用(控制台的)如果是tomcat或者是别的服务器需要你去查如何配置JVM参数:
以下是一个会导致java.lang.OutOfMemoryError: Java heap space的程序代码:(very easy)
- package org.lx.test;
- import java.util.Date;
- import java.util.HashMap;
- import java.util.Map;
- public class OutOfMemoryTest {
- public static void main(String[] args) {
- Map
map=
new
HashMap
();
- for (int i = 0; i < 600000000; i++) {
- map.put(i, new Date());
- }
- }
- }
首先在运行之前有一些参数需要设置:

然后就到了参数设置的页面,按照A,B的顺序设置参数:(-XX:+HeapDumpOnOutOfMemoryError)避免写错误可以copy

运行错误的程序代码会看见以下结果:

那么这时候就生成了一个文件java_pid3708.hprof,这个文件 在你的项目的根目录下(myeclipse10)

那么接下来我们就打开这个文件进行分析如何打开见下图:(选中刚刚在项目根目录下生成的文件java_pid3708.hprof打开)

打开之后你会看见下图就OK了:

参考文档
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/199302.html原文链接:https://javaforall.net


