


对计算图像相似度的方法,本文做了如下总结,主要有三种办法:
1.PSNR峰值信噪比
PSNR(Peak Signal to Noise Ratio),一种全参考的图像质量评价指标。
原理简介
https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
PSNR是最普遍和使用最为广泛的一种图像客观评价指标,然而它是基于对应像素点间的误差,即基于误差敏感的图像质量评价。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
SSIM(structural similarity)结构相似性,也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。

SSIM取值范围[0,1],值越大,表示图像失真越小.
在实际应用中,可以利用滑动窗将图像分块,令分块总数为N,考虑到窗口形状对分块的影响,采用高斯加权计算每一窗口的均值、方差以及协方差,然后计算对应块的结构相似度SSIM,最后将平均值作为两图像的结构相似性度量,即平均结构相似性MSSIM:
参考资料
[1] 峰值信噪比-维基百科
官方文档的说明,不过是GPU版本的,我们可以修改不用gpu不然还得重新编译
代码
// PSNR.cpp : 定义控制台应用程序的入口点。 // #include "stdafx.h" #include
效果
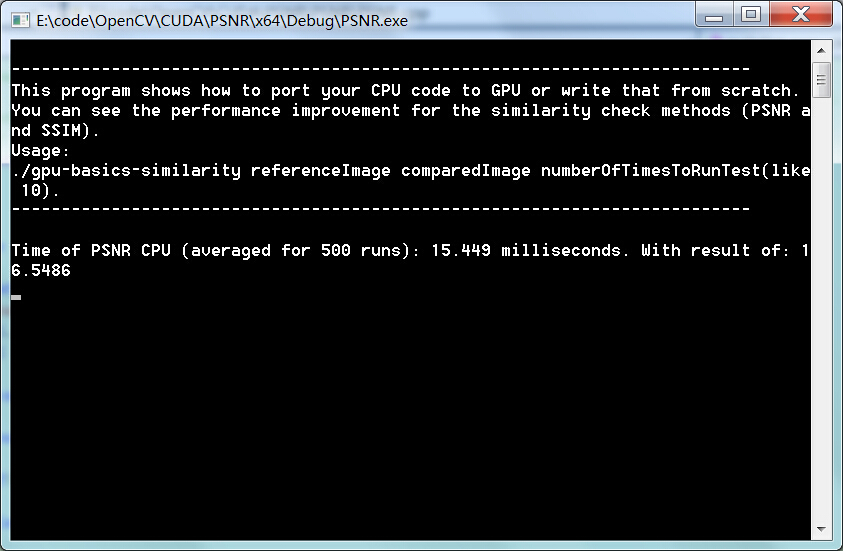
两幅一样的图片,对比结果:
2.感知哈希算法
(perceptual hash algorithm)
http://blog.csdn.net/fengbingchun/article/details/
感知哈希算法(perceptual hash algorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。
实现步骤
- 缩小尺寸:将图像缩小到8*8的尺寸,总共64个像素。
- 这一步的作用是去除图像的细节,只保留结构/明暗等基本信息,摒弃不同尺寸/比例带来的图像差异;这一步的作用是去除图像的细节,只保留结构/明暗等基本信息,摒弃不同尺寸/比例带来的图像差异;
- 简化色彩:将缩小后的图像,转为64级灰度,即所有像素点总共只有64种颜色;
- 计算平均值:计算所有64个像素的灰度平均值;
- 比较像素的灰度:将每个像素的灰度,与平均值进行比较,大于或等于平均值记为1,小于平均值记为0;
- 计算哈希值:将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图像的指纹。组合的次序并不重要,只要保证所有图像都采用同样次序就行了;
- 得到指纹以后,就可以对比不同的图像,看看64位中有多少位是不一样的。在理论上,这等同于”汉明距离”(Hamming distance,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数)。
如果不相同的数据位数不超过5,就说明两张图像很相似;
如果大于10,就说明这是两张不同的图像。
以上内容摘自:http://www.ruanyifeng.com/blog/2011/07/principle_of_similar_image_search.html
代码
// similarity.cpp : 定义控制台应用程序的入口点。 // #include "stdafx.h" #include
效果
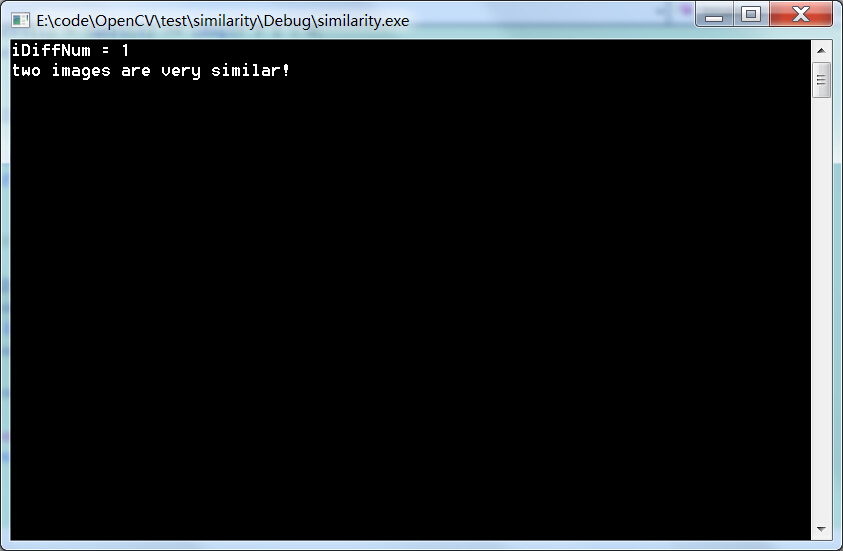
一幅图片自己对比:

结果:
3.计算特征点
OpenCV的feature2d module中提供了从局部图像特征(Local image feature)的检测、特征向量(feature vector)的提取,到特征匹配的实现。其中的局部图像特征包括了常用的几种局部图像特征检测与描述算子,如FAST、SURF、SIFT、以及ORB。对于高维特征向量之间的匹配,OpenCV主要有两种方式:
feature2d module: http://docs.opencv.org/modules/features2d/doc/features2d.html
OpenCV FLANN: http://docs.opencv.org/modules/flann/doc/flann.html
FLANN: http://www.cs.ubc.ca/~mariusm/index.php/FLANN/FLANN
原文:
http://blog.csdn.net/icvpr/article/details/
代码
//localfeature.h #ifndef _FEATURE_H_ #define _FEATURE_H_ #include
效果
两幅同样图片结果:

几年前上学时候写了这个文章,没想到现在居然是博客访问最高的一篇文章,现在我又收集了一些论文文档资料,当然衡量图像相似度的方法有很多不止上述的三种方法,具体我们再看看论文和外围资料,下载链接:
http://download.csdn.net/detail/wangyaninglm/
更新
参照大牛@yuanwenmao,大家可能得对部分代码做出修改
cv::cvtColor(matDst1, matDst1, CV_BGR2GRAY); cv::cvtColor(matDst2, matDst2, CV_BGR2GRAY); 感知哈希算法,的这里有个bug,入参与出参不能是同一个变量,内部应该在计算时被自己修改了,造成判断结果都是很相似。由于博主采用了同一个图片进行比较,所以没发现问题。
void cv::cvtColor( cv::InputArray src, // 输入序列 cv::OutputArray dst, // 输出序列 int code, // 颜色映射码 int dstCn = 0 // 输出的通道数 (0='automatic') ); 你src、dst都传同一个array,内部计算的同时又在修改array的值,自然有问题。可以看看cvtColor的实现。dst换用另外的变量即可,后面的计算也以更换的变量来。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/199564.html原文链接:https://javaforall.net


