
一、简介
广度优先搜索算法(Breadth-First Search,BFS)是一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。BFS并不使用经验法则算法。
广度优先搜索让你能够找出两样东西之间的最短距离,不过最短距离的含义有很多!使用广度优先搜索可以:
- 编写国际跳棋AI,计算最少走多少步就可获胜;
- 编写拼写检查器,计算最少编辑多少个地方就可将错拼的单词改成正确的单词,如将READED改为READER需要编辑一个地方;
- 根据你的人际关系网络找到关系最近的医生。
二、例子
假设你居住在旧金山,要从双子峰前往金门大桥。你想乘公交车前往,并希望换乘最少。可乘坐的公交车如下。



金门大桥未突出,因此一步无法到达那里。两步能吗?

金门大桥也未突出,因此两步也到不了。三步呢?

金门大桥突出了!因此从双子峰出发,可沿下面的路线三步到达金门大桥。

三、图
图是由顶点的有穷非空集合和顶点之间边的集合组成,通过表示为G(V,E),其中,G标示一个图,V是图G中顶点的集合,E是图G中边的集合。
无边图:若顶点Vi到Vj之间的边没有方向,则称这条边为无项边(Edge),用序偶对(Vi,Vj)标示。
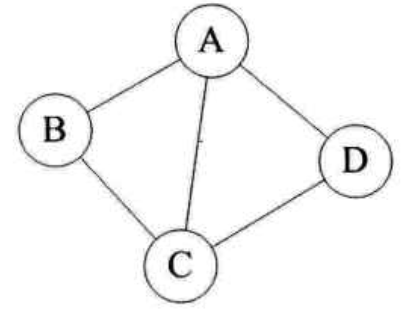
对于下图无向图G1来说,G1=(V1, {E1}),其中顶点集合V1={A,B,C,D};边集合E1={(A,B),(B,C),(C,D),(D,A),(A,C)}:
有向图:若从顶点Vi到Vj的边是有方向的,则成这条边为有向边,也称为弧(Arc)。用有序对(Vi,Vj)标示,Vi称为弧尾,Vj称为弧头。如果任意两条边之间都是有向的,则称该图为有向图。
有向图G2中,G2=(V2,{E2}),顶点集合(A,B,C,D),弧集合E2={
,{B,A},
,
}.
权:有些图的边和弧有相关的数,这个数叫做权。这些带权的图通常称为网。
四、广度优先搜索算法
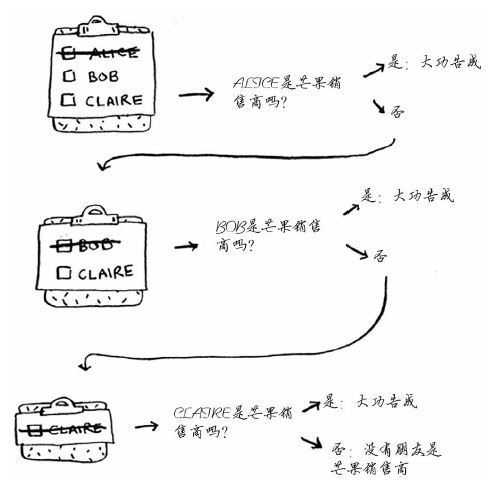
假设你经营着一个芒果农场,需要寻找芒果销售商,以便将芒果卖给他。在Facebook,你与芒果销售商有联系吗?为此,你可在朋友中查找。

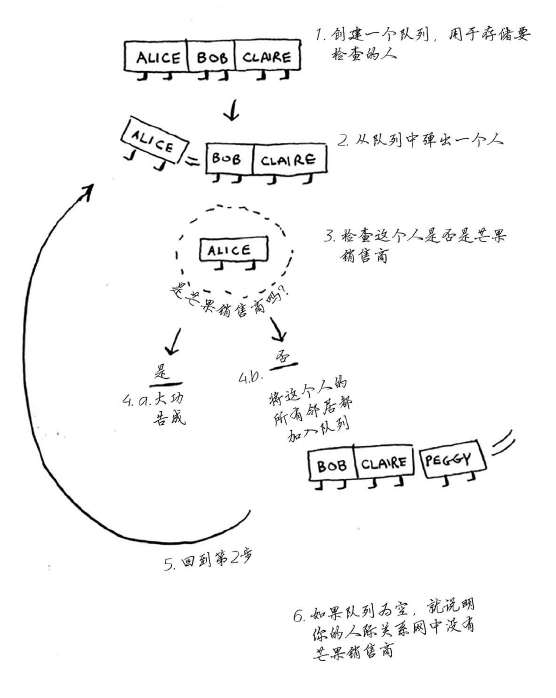
这种查找很简单。首先,创建一个朋友名单。

然后,依次检查名单中的每个人,看看他是否是芒果销售商。
假设你没有朋友是芒果销售商,那么你就必须在朋友的朋友中查找。
检查名单中的每个人时,你都将其朋友加入名单。
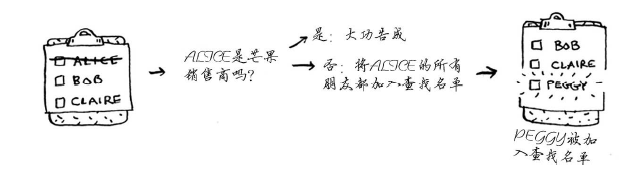
这样一来,你不仅在朋友中查找,还在朋友的朋友中查找。别忘了,你的目标是在你的人际关系网中找到一位芒果销售商。因此,如果Alice不是芒果销售商,就将其朋友也加入到名单中。这意味着你将在她的朋友、朋友的朋友等中查找。使用这种算法将搜遍你的整个人际关系网,直到找到芒果销售商。这就是广度优先搜索算法。
五、查找最短路径

你也可以这样看,一度关系在二度关系之前加入查找名单。
你按顺序依次检查名单中的每个人,看看他是否是芒果销售商。这将先在一度关系中查找,再在二度关系中查找,因此找到的是关系最近的芒果销售商。广度优先搜索不仅查找从A到B的路径,而且找到的是最短的路径。

六、队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)线性表。
顺序队列
建立顺序队列结构必须为其静态分配或动态申请一片连续的存储空间,并设置两个指针进行管理。一个是队头指针front,它指向队头元素;另一个是队尾指针rear,它指向下一个入队元素的存储位置,如图所示

每次在队尾插入一个元素是,rear增1;每次在队头删除一个元素时,front增1。随着插入和删除操作的进行,队列元素的个数不断变化,队列所占的存储空间也在为队列结构所分配的连续空间中移动。当front=rear时,队列中没有任何元素,称为空队列。当rear增加到指向分配的连续空间之外时,队列无法再插入新元素,但这时往往还有大量可用空间未被占用,这些空间是已经出队的队列元素曾经占用过得存储单元。
顺序队列中的溢出现象:
(1) “下溢”现象:当队列为空时,做出队运算产生的溢出现象。“下溢”是正常现象,常用作程序控制转移的条件。
(2)”真上溢”现象:当队列满时,做进栈运算产生空间溢出的现象。“真上溢”是一种出错状态,应设法避免。
(3)”假上溢”现象:由于入队和出队操作中,头尾指针只增加不减小,致使被删元素的空间永远无法重新利用。当队列中实际的元素个数远远小于向量空间的规模时,也可能由于尾指针已超越向量空间的上界而不能做入队操作。该现象称为”假上溢”现象。
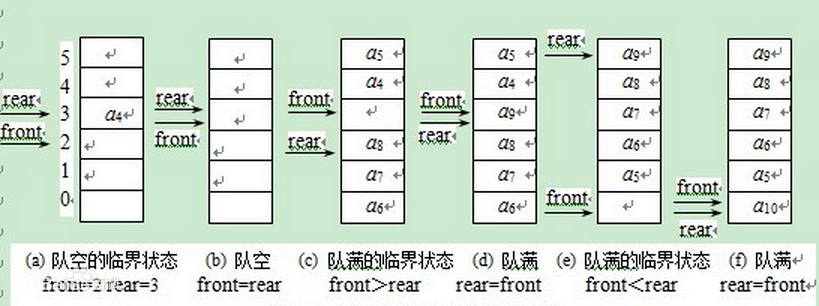
循环队列
在实际使用队列时,为了使队列空间能重复使用,往往对队列的使用方法稍加改进:无论插入或删除,一旦rear指针增1或front指针增1 时超出了所分配的队列空间,就让它指向这片连续空间的起始位置。自己真从MaxSize-1增1变到0,可用取余运算rear%MaxSize和front%MaxSize来实现。这实际上是把队列空间想象成一个环形空间,环形空间中的存储单元循环使用,用这种方法管理的队列也就称为循环队列。除了一些简单应用之外,真正实用的队列是循环队列。 [2]
在循环队列中,当队列为空时,有front=rear,而当所有队列空间全占满时,也有front=rear。为了区别这两种情况,规定循环队列最多只能有MaxSize-1个队列元素,当循环队列中只剩下一个空存储单元时,队列就已经满了。因此,队列判空的条件时front=rear,而队列判满的条件时front=(rear+1)%MaxSize。队空和队满的情况如图:
七、广度优先搜索算法实现
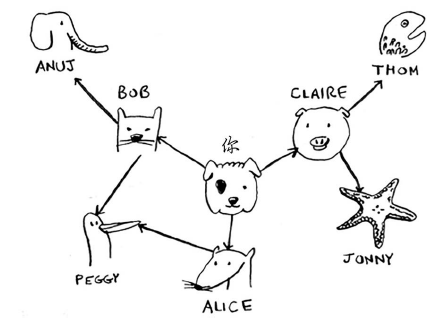
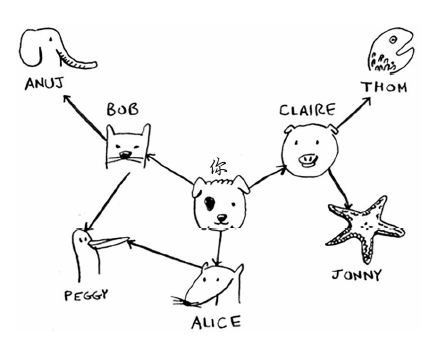
我们要从“你”出发找到“ANUJ”,关系表示为下图,使用广度优先搜索算法
先概述一下这种算法的工作原理。
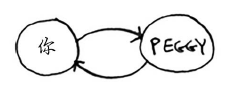
但这样可能会出现一些问题,Peggy既是Alice的朋友又是Bob的朋友,因此她将被加入队列两次:一次是在添加Alice的朋友时,另一次是在添加Bob的朋友时。因此,搜索队列将包含两个Peggy。

一开始,搜索队列包含你的所有邻居。

现在你检查Peggy。她不是芒果销售商,因此你将其所有邻居都加入搜索队列。
接下来,你检查自己。你不是芒果销售商,因此你将你的所有邻居都加入搜索队列。

以此类推。这将形成无限循环,因为搜索队列将在包含你和包含Peggy之间反复切换。

检查一个人之前,要确认之前没检查过他,这很重要。为此,你可使用一个列表来记录检查过的人。
图不过是一系列的节点和边,因此在JAVA中,你可以使用HashMap来表示一个图。
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.concurrent.LinkedBlockingQueue; public class BFS { public static void main(String[] args) { HashMap
hashMap=new HashMap<>(); hashMap.put("YOU",new String[]{"CLAIRE","ALICE","BOB"}); hashMap.put("CLAIRE",new String[]{"YOU","JONNY","THON"}); hashMap.put("JONNY",new String[]{"CLAIRE"}); hashMap.put("THOH",new String[]{"CLAIRE"}); hashMap.put("ALICE",new String[]{"YOU","PEGGY"}); hashMap.put("BOB",new String[]{"YOU","PEGGY","ANUJ"}); hashMap.put("PEGGY",new String[]{"BOB","ALICE"}); hashMap.put("ANUJ",new String[]{"BOB"}); Node target = findTarget("YOU","ANUJ",hashMap); //打印出最短路径的各个节点信息 printSearPath(target); } / * 打印出到达节点target所经过的各个节点信息 * @param target */ static void printSearPath(Node target) { if (target != null) { System.out.print("找到了目标节点:" + target.id + "\n"); List
searchPath = new ArrayList
(); searchPath.add(target); Node node = target.parent; while(node!=null) { searchPath.add(node); node = node.parent; } String path = ""; for(int i=searchPath.size()-1;i>=0;i--) { path += searchPath.get(i).id; if(i!=0) { path += "-->"; } } System.out.print("步数最短:"+path); } else { System.out.print("未找到了目标节点"); } } static Node findTarget(String startId,String targetId,HashMap
map) { List
hasSearchList = new ArrayList
(); LinkedBlockingQueue
queue=new LinkedBlockingQueue<>(); queue.offer(new Node(startId,null)); while(!queue.isEmpty()) { Node node = queue.poll(); if(hasSearchList.contains(node.id)) { continue; } System.out.print("判断节点:" + node.id +"\n"); if (targetId.equals(node.id)) { return node; } hasSearchList.add(node.id); if (map.get(node.id) != null && map.get(node.id).length > 0) { for (String childId : map.get(node.id)) { queue.offer(new Node(childId,node)); } } } return null; } static class Node{ public String id; public Node parent; public Node(String id,Node parent) { this.id = id; this.parent = parent; } } }
运行时间
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/200475.html原文链接:https://javaforall.net

![《Python 快速入门》一千个程序员有一千套编码规范[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
