
MPP架构
0x01 摘要
本文综合各家看法,再加上个人理解,介绍下对MPP架构的理解以及一些其他架构的对比。
0x02 MPP架构基本概念
2.1 什么是MPP
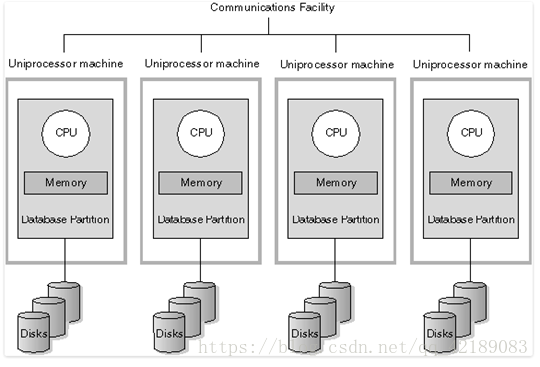

MPP,全称为Massively Parallel Processor,翻译过来就是大规模并行处理。MPP系统是由许多松耦合的处理单元组成的(要注意的是这里指的是处理单元而不是处理器)。每个处理单元内的CPU都有自己私有的资源,如总线,内存,硬盘等,且都有操作系统和管理数据库的实例复本。这种结构最大的特点在于不共享资源(share-nothing)。
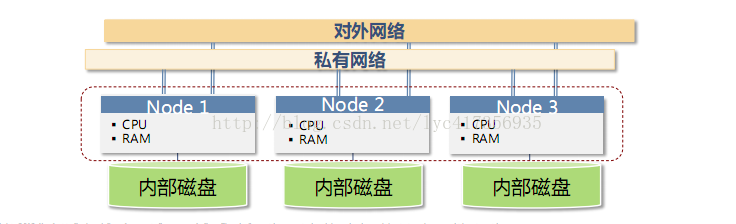
2.2 MPP架构特点
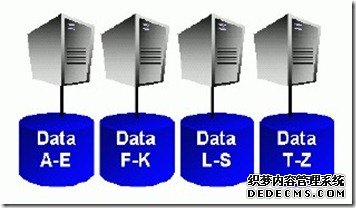
MPP架构有如下特点:
- Share Nothing、节点之间数据不共享,只有通过网络连接实现的协同
- 每个节点有独立的存储和内存
- 数据根据某种规则(如Hash)散布到各个节点
- 计算任务也是会发布到各个节点并行执行,最后再将结果聚合到整体返回
- 用户使用时会看做整体
- MPP数据库(如GreePlum)往往优先考虑
C一致性,然后是A可用性,最后考虑P分区容忍 - MPP架构目前被并行数据库广泛采用,一般通过scan、sort和merge等操作符实时返回查询结果
2.3 MPP架构劣势
- 很难高可用 -> 影响可用性和可靠性
因为数据按某种规则如HASH已经散布到了各个节点上。 - 节点数=任务并行数 -> 影响扩展性
一个作业提交时,每个节点都要执行相同任务。而不像MapReduce那样做了根据实际开销进行任务拆分后散发到有资源的几个节点上。这一点大大影响了MPP架构应用的可扩展性。 - 每个客户端同时连接所有节点通信 -> 影响网络
MPP架构每个节点独立,所以客户端往往需要连接所有节点进行通信,这使得网络也成为瓶颈。 - 分区容错性差
前面提到过MPP主要考虑CA,最次才是P。那么一旦扩展节点太多后,元数据管理十分困难。
2.4 MPP 适用场景
集群规模100以内、并发小(50以下)
MPP架构目前被并行数据库广泛采用,一般通过scan、sort和merge等操作符实时返回查询结果
0x03 典型的MPP架构应用
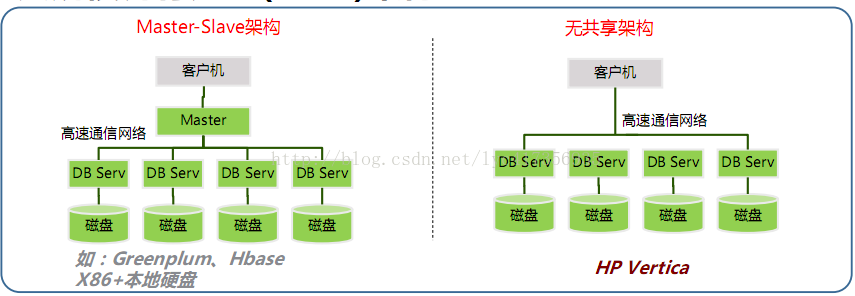
- GreenPlum
Master-Slave架构的MPP
可以参考这篇文章:大数据系统的另一种解决方案-采用MPP架构的GreenPlum数据库 - HP Vertica
无共享架构的MPP,特点如下- 无特殊节点
- 所有节点对等
- 可通过任意节点查询或加载数据
- 实时加载与查询同步进行
- Impala
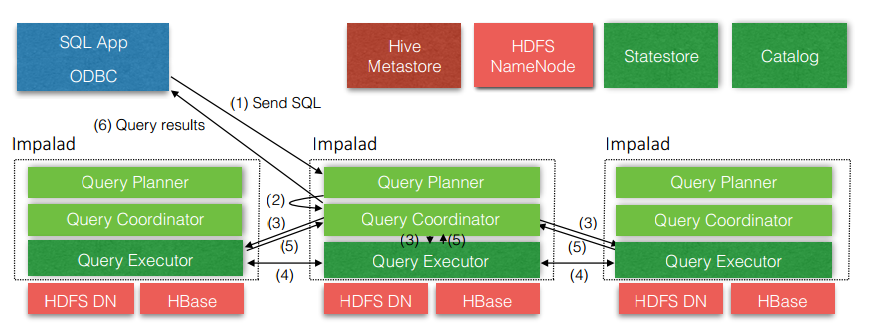
0x04 其他架构
4.1 SMP
4.1.1 什么是SMP
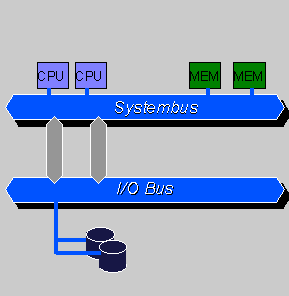
SMP全称为Symmetric Multi Processing,翻译过来是对称多处理。其最大的特点是CPU共享所有资源,如内存、IO等。操作系统只有一个,他管理着一个队列,每个处理器依次处理队列中的进程。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA : Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
4.1.2 SMP的问题
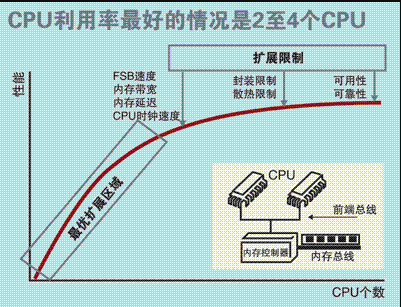
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。
对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。
实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
4.1.3 适用场景
当节点之间通信交互较少时,MPP更适用。集中式数据库SMP更适用。
MPP架构服务器就是由多个SMP服务器通过若干节点组成,通过网络协同工作。
4.2 NUMA
4.2.1 什么是NUMA
NUMA全称为Non-Uniform Memory Access。
4.2.2 NUMA特点
NUMA 服务器的基本特征:
- 具有多个 CPU 模块
- 每个 CPU 模块又是由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O slot等
- 节点之间通过互联模块 ( 如称为 Crossbar Switch) 进行通信交互,每个 CPU 可以访问整个系统的内存 ( NUMA 与 MPP 的重要差别,因为MPP中CPU不可访问其他节点内存 )
显然,访问本地内存的速度将远远高于访问其他节点上的内存的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理节点内可以支持上百个 CPU 。
4.2.3 NUMA的问题
但 NUMA 技术同样有一定缺陷,由于访问其他节点上的内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。
如 HP 公司发布 Superdome 服务器时,曾公布了它与 HP 其它 UNIX 服务器的相对性能值,结果发现, 64 路 CPU 的 Superdome (NUMA 结构 ) 的相对性能值是 20 ,而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3 。从这个结果可以看到, 8 倍数量的 CPU 换来的只是 3 倍性能的提升。
4.2.4 NUMA例子
比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
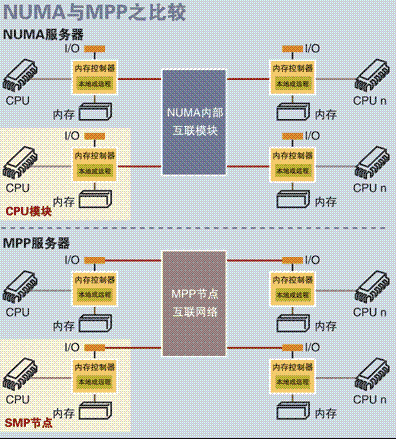
4.2.5 NUMA和MPP比较
4.2.5.1 相同
- 它们都由多个节点组成,
- 每个节点都具有自己的 CPU 、内存、 I/O ,
- 节点之间都可以通过节点互联机制进行信息交互。
4.2.5.2 不同
- 节点互联机制不同。
- NUMA 的节点互联机制是在同一个物理服务器内部实现的。当某个 CPU 需要进行同模块其他节点内存访问时,它必须等待,这也是 NUMA 服务器无法实现 CPU 增加时性能线性扩展的主要原因。
- 而 MPP 的节点互联机制是在不同的 SMP 服务器外部通过 I/O 实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此 MPP 在增加节点时性能基本上可以实现线性扩展。
- 内存访问机制不同。
- 在 NUMA 服务器内部,任何一个 CPU 可以访问整个系统的内存,但非本节点内存访问的性能远远低于本节点内存访问,因此在开发应用程序时应该尽量非本节点内存访问。
- 在 MPP 服务器中,每个节点只访问本地内存,不存在远地内存访问的问题。
4.2.6 适用场景
NUMA不适合大量数据需要处理且有交互的场景。
4.3 Hadoop
- 数据存储sharding技术不同
MPP一般用hash切分,很难resharding导致扩展困难,采用这种方式切分的一般上百台性能达到平静,每次增加节点需要reshard;Hadoop用元数据服务(NameNode)统一管理,数据的分区逻辑和分区的存储逻辑分离了,数据的写入和读取都是通过查询元数据服务得到数据分区的具体节点位置,也会受限于元数据服务能力,一般上限10K。 - 内存管理
MPP内存管理精细,就像每个节点有个小数据库,数据量小时延时低,但数据量太大吞吐就达到瓶颈了;Hive内存管理粗放,scan+batch所以吞吐量大,但延时高 - 数据管理理念不同(以下转自为什么说HADOOP扩展性优于MPP架构的关系型数据库?,作者 王涛)

- 解决data locality时机不同
- hadoop为计算时,MPP为数据加载时,所以HADOOP更易扩展
- 事务和数据模型处理不同(以下转自为什么说HADOOP扩展性优于MPP架构的关系型数据库?,作者:黄东旭)
MPP数据库属于关系型数据库,一个完整的关系模型分散到多台物理节点上去做管理,因此对于DML操作、强事务型操作,MPP数据库压力很大,规模上来以后,DML操作的性能基本无法接受,而对于DQL操作,就没有太大影响,因为数据相对不动,因此无修改数据,对于数据模型的维护来讲,成本非常小。所以说,对于MPP分析类的数据库(只查询),扩展性影响不大。而相反,事务型MPP数据库,扩展性就很差了。Hadoop是非关系型数据库,不涉及太多的数据模型维护工作,因此扩展性很高。 - failover机制
- 当数据基本是结构化且需要使用MPP数据库的RDBMS特性时可考虑使用MPP数据库;MPP更适合多维度数据分析、数据集市等
- 而非结构化和半结构化数据或数据量巨大需要海量扩展节点或是需要使用一些基于HDFS的一些技术栈的时候就用Hadoop这套。
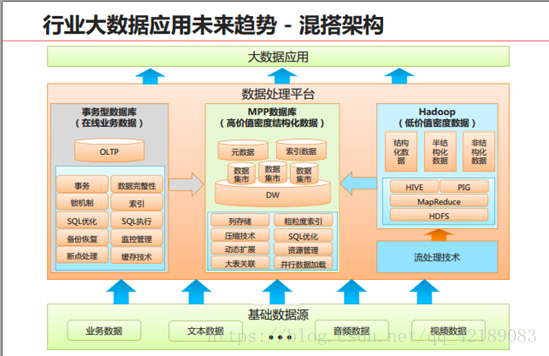
由上述对比可预见未来大数据存储与处理趋势:
- MPPDB+Hadoop混搭使用,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事物支持能力;
- 用Hadoop实现半结构化、非结构化数据处理。
- 这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。
4.4 集群和MPP区别(未完成)
- 集群中,每个机器节点都拥有独立内存、内盘等,内部使用网络来达到内部互联的目的。集群由程序员决定怎么分配工作。
- 简单理解MPP即这样的系统由多个物理上独立的节点通过高速网络互联组成的一个相互协同工作的大规模系统,从用户角度来看,用户的任务将会被透明的分割到多个节点计算,由协调节点聚合并返回结果。
0xFF 参考文档
MPP(大规模并行处理)简介
MPP
Hadoop与MPP解析
SMP、NUMA、MPP体系结构介绍
MPP(大规模并行处理)简介
What is the difference between a Cluster and MPP supercomputer architecture?
为什么说HADOOP扩展性优于MPP架构的关系型数据库?
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/200561.html原文链接:https://javaforall.net


