
MPP数据库初识
先了解下OLTP与OLAP区别
为什么需要MPP数据库?
1 海量数据的分析需求
传统数据库无法支持大规模集群与PB级别数据量
单台机器性能受限、成本高昂,扩展性受限
2 支持复杂的结构化查询(这里是重点)
复杂查询经常使用多表联结、全表扫描等,牵涉的数据量往往十分庞大;支持复杂sql查询和支持大数据规模;
3 Hadoop技术的先天不足
Hive等sql-on-hadoop性能太慢,分析场景不一样,SQL兼容性与支持不足
MPP数据库应用领域
大数据分析:MPP数据库做大数据计算或分析平台非常适合,例如:数据仓库系统、历史数据管理系统、数据集市等。
有很强的并行数据计算能力和海量数据存储能力,但是他不擅长高频的小规模数据插入、修改、删除,每次事务处理的数据量不大。这类数据衡量指标是TPS,适用的系统是OLTP数据库。
什么是MPP?
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
MPP架构特征
MPPDB架构
什么是MPP数据库?
MPP数据库是一款 Shared Nothing架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统
MPP数据库的使用场景?
MPP数据库有对SQL的完整兼容和一些事务的处理能力,对于用户来说,在实际的使用场景中,如果数据扩展需求不是特别大,需要的处理节点不多,数据都是结构化的数据,习惯使用传统的RDBMS的很多特性的场景,可以考虑MPP,例如Greenplum/Gbase等。
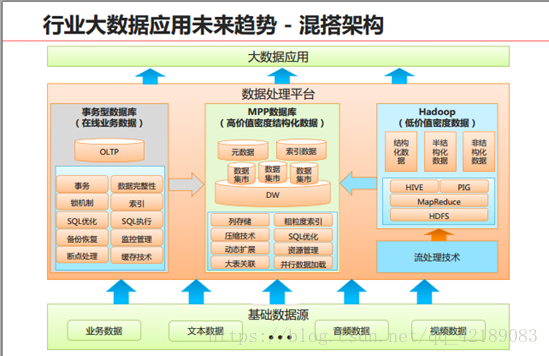
MPPDB、Hadoop与传统数据库技术对比与适用场景
综合而言,Hadoop和MPP两种技术的特定和适用场景为:
由上述对比可预见未来大数据存储与处理趋势:MPPDB+Hadoop混搭使用,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事物支持能力;用Hadoop实现半结构化、非结构化数据处理。这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/201327.html原文链接:https://javaforall.net


