

本文主要讲“变量选择”“模型开发”“评分卡创建和刻度”
变量分析
单因子分析,用来检测各变量的预测强度,方法为WOE、IV;
WOE
这里说一下,有的地方计算WOE时使用的是 b a d 占 比 g o o d 占 比 \frac{bad占比}{good占比} good占比bad占比的,其实是没有影响的,因为我们计算WOE的目的其实是通过WOE去计算IV,从而达到预测的目的。后面IV计算中,会通过相减后相乘的方式把负号给抵消掉。所以不管谁做分子,谁做分母,最终的IV预测结果是不变的。
IV
| IV | 预测能力 |
|---|---|
| <0.03 | 无预测能力 |
| 0.03~0.09 | 低 |
| 0.1~0.29 | 中 |
| 0.3~0.49 | 高 |
| >=0.5 | 极高 |
根据IV值来调整分箱结构并重新计算WOE和IV,直到IV达到最大值,此时的分箱效果最好。
分组一般原则
- 组间差异大
- 组内差异小
- 每组占比不低于5%
- 必须有好、坏两种分类
举例说明
例如按年龄分组,一般进行分箱,我们都喜欢按照少年、青年、中年、老年几大类进行分组,但效果真的不一定好:
| Age | good | bad | WOE |
|---|---|---|---|
| <18 | 50 | 40 | l n ( 50 / 330 40 / 220 ) = − 0.3955 ln(\frac{50/330}{40/220}) = -0.3955 ln(40/22050/330)=−0.182321556793955 |
| 18~30 | 100 | 60 | l n ( 100 / 330 60 / 220 ) = 0.7826 ln(\frac{100/330}{60/220}) = 0.7826 ln(60/220100/330)=0.105360515657826 |
| 30~60 | 100 | 80 | l n ( 100 / 330 80 / 220 ) = − 0.3955 ln(\frac{100/330}{80/220}) = -0.3955 ln(80/220100/330)=−0.182321556793955 |
| >60 | 80 | 40 | l n ( 80 / 330 40 / 220 ) = 0.1781 ln(\frac{80/330}{40/220}) = 0.1781 ln(40/22080/330)=0.287682072451781 |
| ALL | 330 | 220 |
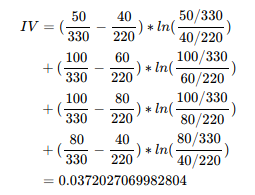
根据IV值可以看出,预测能力低,建议重新调整分箱。
建立模型
评分卡
评分卡计算方法
设置比率为 θ 0 \theta_0 θ0(也就是odds)的特定点分值为 P 0 P_0 P0,比率为 2 θ 0 2\theta_0 2θ0的点的分值为 P 0 + P D O P_0+PDO P0+PDO。带入上面公式可得到:
{ P 0 = A + B l n ( θ 0 ) P 0 + P D O = A + B l n ( 2 θ 0 ) \begin{cases} P_0 &= A+Bln(\theta_0) \\ P_0+PDO &= A+Bln(2\theta_0) \end{cases} {
P0P0+PDO=A+Bln(θ0)=A+Bln(2θ0)
求解上述公式,可以得到A、B值:
{ B = P D O l n 2 A = P 0 − B l n ( θ 0 ) \begin{cases} B &= \frac{PDO}{ln2} \\ A &= P_0-Bln(\theta_0) \end{cases} {
BA=ln2PDO=P0−Bln(θ0)
P 0 P_0 P0 和 P D O PDO PDO 的值都是已知常数,可以设置 P 0 = 600 P_0 = 600 P0=600 和 P D O = 20 PDO = 20 PDO=20,
可以计算出A、B值。
这里 P 0 P_0 P0 和 P D O PDO PDO 主要是根据你想要分数落在一个什么范围内,然后进行人为设定,不用太纠结取值的意义。
分值分配
之前步骤中每个变量都有进行分箱操作,分为若干类。所以下一步的话,把每个变量对应的分数,分别乘以变量中每个分箱的WOE,得到每个分箱的评分结果。
| 变量 | 分箱类别 | 分值 |
|---|---|---|
| 基础分数 | – | ( A + B ∗ w 0 ) (A+B*w_0) (A+B∗w0) |
| x 1 x_1 x1 | 1 2 … i i i |
( B ∗ w 1 ) ∗ W O E 11 (B*w_1)*WOE_{11} (B∗w1)∗WOE11 ( B ∗ w 1 ) ∗ W O E 12 (B*w_1)*WOE_{12} (B∗w1)∗WOE12 ··· ( B ∗ w 1 ) ∗ W O E 1 i (B*w_1)*WOE_{1i} (B∗w1)∗WOE1i |
| x 2 x_2 x2 | 1 2 … j j j |
( B ∗ w 2 ) ∗ W O E 21 (B*w_2)*WOE_{21} (B∗w2)∗WOE21 ( B ∗ w 2 ) ∗ W O E 22 (B*w_2)*WOE_{22} (B∗w2)∗WOE22 ··· ( B ∗ w 2 ) ∗ W O E 2 j (B*w_2)*WOE_{2j} (B∗w2)∗WOE2j |
| ··· | ··· | ··· |
| x n x_n xn | 1 2 … k k k |
( B ∗ w n ) ∗ W O E n 1 (B*w_n)*WOE_{n1} (B∗wn)∗WOEn1 ( B ∗ w n ) ∗ W O E n 2 (B*w_n)*WOE_{n2} (B∗wn)∗WOEn2 ··· ( B ∗ w n ) ∗ W O E n k (B*w_n)*WOE_{nk} (B∗wn)∗WOEnk |
以上步骤都完成后,假如新产生一个用户,我们只需将此用户每个变量对应到各分箱中得到其对应的WOE值,再根据上面的公式计算出这个样本在每个变量下的分数。最后将所有变量对应的分数相加,即为最终评分结果。
最后说一下,特征选择方面,并不是维度越多越好。一个评分卡中,一般不超过15个维度。可根据Logistic Regression模型系数来确定每个变量的权重,保留权重高的变量。通过协方差计算的相关性大于0.7的变量一般只保留IV值最高的那一个。
引用
《信用风险评分卡研究》Mamdouh Refaat著
《互联网金融时代消费信贷评分建模与应用》单良著
手把手教你用R语言建立信用评分模型
《统计学习方法》李航著
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/201588.html原文链接:https://javaforall.net


