
结构光法:为解决双目匹配问题而生
深度图效果:结构光vs.双目
投射图案的编码方式
时分复用编码
空分复用编码
iPhone X原深感相机是缩小版的更强大的Kinect1
结构光法优缺点总结
——————————————————————
结构光法:为解决双目匹配问题而生
前面文章《深度相机原理揭秘–双目立体视觉》中提到基于双目立体视觉的深度相机对环境光照强度比较敏感,且比较依赖图像本身的特征,因此在光照不足、缺乏纹理等情况下很难提取到有效鲁棒的特征,从而导致匹配误差增大甚至匹配失败。
而基于结构光法的深度相机就是为了解决上述双目匹配算法的复杂度和鲁棒性问题而提出的,其他处理步骤和双目立体视觉类似,本文不再赘述。结构光法不依赖于物体本身的颜色和纹理,采用了主动投影已知图案的方法来实现快速鲁棒的匹配特征点,能够达到较高的精度,也大大扩展了适用范围。

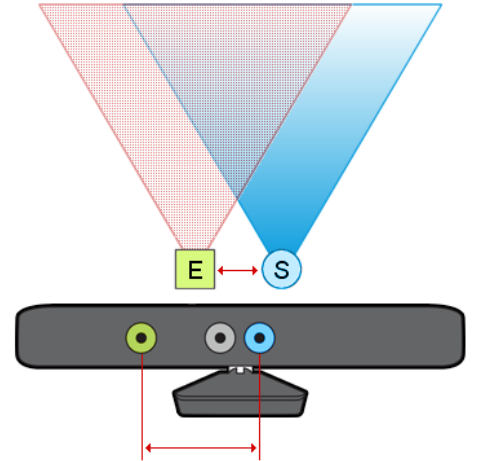
结构光深度相机原理示意图(注意E端发射的带图案的光源)
深度图效果:结构光vs.双目
下图左是普通双目立体视觉深度相机拍摄的图像和对应的深度图结果;下图右是结构光法的深度相机投射的图案及对应的深度图结果,明显可以观察到在同样的场景下结构光法得到的深度图更完整,细节更丰富,效果大大好于双目立体视觉法。

双目立体视觉(左)和结构光(右)深度相机拍摄的图像和对应的深度图
投射图案的编码方式
结构光法投射的图案需要进行精心设计和编码,结构光编码的方式有很多种,一般分为如下几大类:
1、直接编码(direct coding)
根据图像灰度或者颜色信息编码,需要很宽的光谱范围。
优势:对所有点都进行了编码,理论上可以达到较高的分辨率。
缺点:受环境噪音影响较大,测量精度较差。
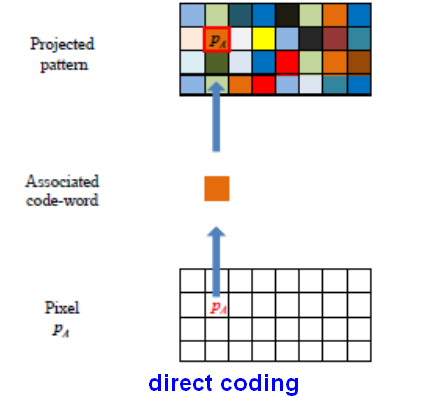
直接编码原理示意图
2、时分复用编码(time multiplexing coding)
顾名思义,该技术方案需要投影N个连续序列的不同编码光,接收端根据接收到N个连续的序列图像来每个识别每个编码点。投射的编码光有二进制码(最常用)、N进制码、灰度+相移等方案。
该方案的优点:测量精度很高(最高可达微米级);可得到较高分辨率深度图(因为有大量的3D投影点);受物体本身颜色影响很小(采用二进制编码)。
缺点:比较适合静态场景,不适用于动态场景;计算量较大(因为识别一个编码点需要计算连续N次投影)。
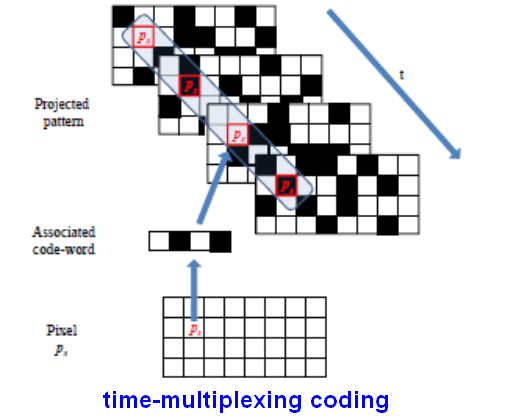
时分复用编码原理示意图
3、空分复用编码(spatial multiplexing coding
根据周围邻域内的一个窗口内所有的点的分布来识别编码。
该技术的优势:适用于运动物体。
缺点:不连续的物体表面可能产生错误的窗口解码(因为遮挡)。
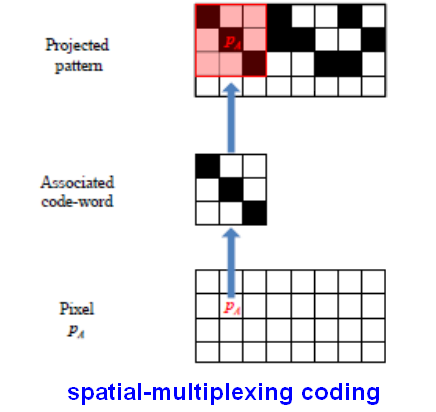
空分复用编码原理示意图
Kinect1原理
业界比较有名的结构光方案就是以色列PrimeSense公司的Light Coding的技术,该方案最早被应用于Microsoft的明星产品Kinect1(Kinect2是基于TOF的技术)上。下面以Kinect1为例,介绍一下其工作原理。

Microsoft和PrimeSense合作的Kinect1
Kinect1的红外IR发射端投射人眼不可见的伪随机散斑红外光点到物体上,每个伪随机散斑光点和它周围窗口内的点集在空间分布中的每个位置都是唯一且已知的。这是因为Kinect1的存储器中已经预储存了所有的数据。

Kinect1投影的伪随机散斑
这些散斑投影在被观察物体上的大小和形状根据物体和相机的距离和方向而不同。如下图所示。
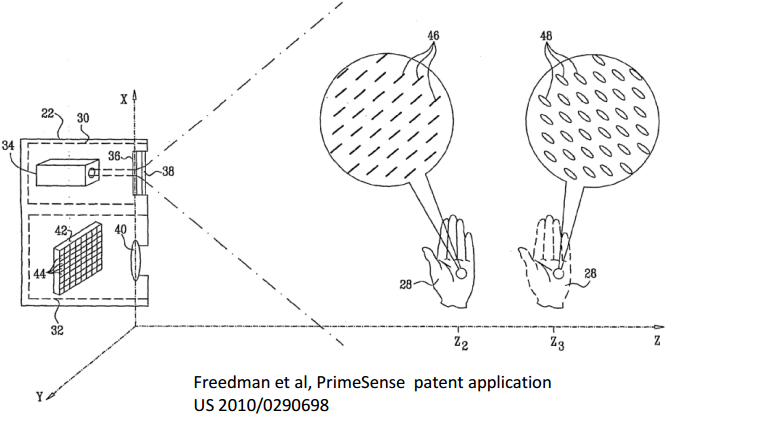
Kinect1根据三种不同的距离使用了三种不同尺寸的散斑,如下图所示。这样的目的是为了在远中近三种距离内都能得到相对较好的测量精度:
近距离(0.8 – 1.2 m):可以获得较高的测量精度
中距离(1.2 – 2.0 m):可以获得中等的测量精度
远距离(2.0 – 3.5 m):可以获得较低的测量精度
Kinect1测量精度如下:
spatial x/y resolution: 3mm @2m distance
depth z resolution: 1cm @2m distance
iPhone X原深感相机是缩小版更强大的Kinect1
2013年11月苹果公司以3.45亿美元收购了PrimeSense公司。之后,苹果一直在推动PrimeSense的深度相机向小型化发展。
2016年7月,苹果公布了新型3D手势控制专利,是一个内嵌在类似手机的iOS设备上的图形投影仪,可以识别出用户的手势操作。
2017年9月,苹果发布了重磅产品iPhone X。其中摄像技术最大的创新就是使用了前置深度相机(苹果称之为Truedepth)。虽然苹果没有透露具体的技术细节,但是从官网介绍来看,投影3万个不可见的红外光点完全符合结构光方案(而不是TOF)的特征。另外结构光方案和TOF方案相比,还具有功耗低,精度高的优势。这对移动设备做近距离的人脸识别来说,是极大的技术优势。

点阵投影在人脸上的示意图
(投影的是人眼不可见的红外光,这里只是示意图)

iPhone X基于原深感相机开发的动画表情功能
因此iPhone X的前置原深感相机可以认为是一个缩小版的功能更强的Kinect1。
结构光法优缺点总结
根据前面的原理介绍,我们总结一下基于结构光法深度相机的优缺点。
1、优点
1)、由于结构光主动投射编码光,因而非常适合在光照不足(甚至无光)、缺乏纹理的场景使用。
2)、结构光投影图案一般经过精心设计,所以在一定范围内可以达到较高的测量精度。
3)、技术成熟,深度图像可以做到相对较高的分辨率。
2、缺点
1)、室外环境基本不能使用。这是因为在室外容易受到强自然光影响,导致投射的编码光被淹没。增加投射光源的功率可以一定程度上缓解该问题,但是效果并不能让人满意。
2)、测量距离较近。物体距离相机越远,物体上的投影图案越大,精度也越差(想象一下手电筒照射远处的情景),相对应的测量精度也越差。所以基于结构光的深度相机测量精度随着距离的增大而大幅降低。因而,往往在近距离场景中应用较多。
3)、容易受到光滑平面反光的影响。
最后,给出几种主流的结构光的深度相机及参数。

几种结构光深度相机的参数
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/201828.html原文链接:https://javaforall.net


